反制面試官 | 14張原理圖 | 再也不怕被問 volatile!
反制面試官 | 14張原理圖 | 再也不怕被問 volatile!
悟空
愛學習的程序猿,自主開發了Java學習平台、PMP刷題小程序。目前主修Java、多線程、SpringBoot、SpringCloud、k8s。本公眾號不限於分享技術,也會分享工具的使用、人生感悟、讀書總結。
絮叨
這一篇也算是Java並發編程的開篇,看了很多資料,但是輪到自己去整理去總結的時候,發現還是要多看幾遍資料才能完全理解。還有一個很重要的點就是,畫圖是加深印象和檢驗自己是否理解的一個非常好的方法。
一、Volatile怎麼念?
看到這個單詞一直不知道怎麼發音
英 [ˈvɒlətaɪl] 美 [ˈvɑːlətl]
adj. [化學] 揮發性的;不穩定的;爆炸性的;反覆無常的
那Java中volatile又是幹啥的呢?
二、Java中volatile用來幹啥?
- Volatile是Java虛擬機提供的
輕量級的同步機制(三大特性)- 保證可見性
- 不保證原子性
- 禁止指令重排
要理解三大特性,就必須知道Java內存模型(JMM),那JMM又是什麼呢?

三、JMM又是啥?
這是一份精心總結的Java內存模型思維導圖,拿去不謝。

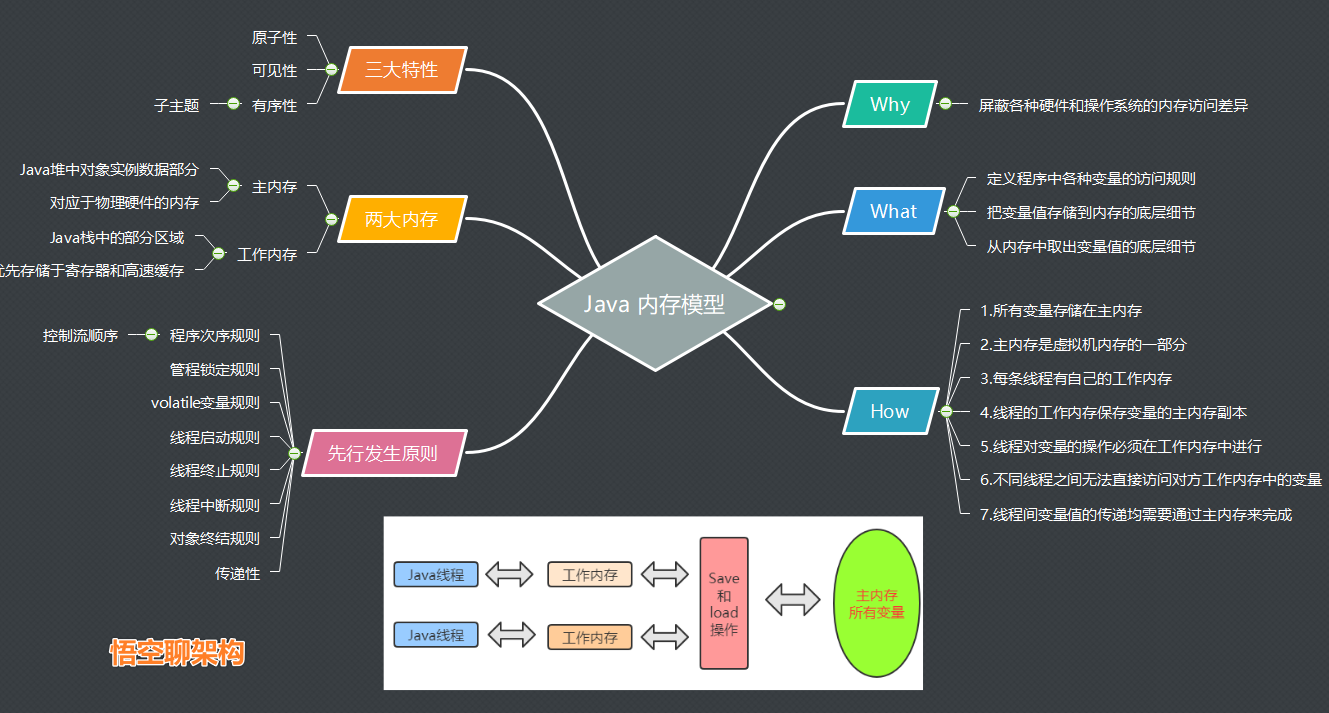
3.1 為什麼需要Java內存模型?
Why:屏蔽各種硬件和操作系統的內存訪問差異
JMM是Java內存模型,也就是Java Memory Model,簡稱JMM,本身是一種抽象的概念,實際上並不存在,它描述的是一組規則或規範,通過這組規範定義了程序中各個變量(包括實例字段,靜態字段和構成數組對象的元素)的訪問方式。
3.2 到底什麼是Java內存模型?
- 1.定義程序中各種變量的訪問規則
- 2.把變量值存儲到內存的底層細節
- 3.從內存中取出變量值的底層細節
3.3 Java內存模型的兩大內存是啥?
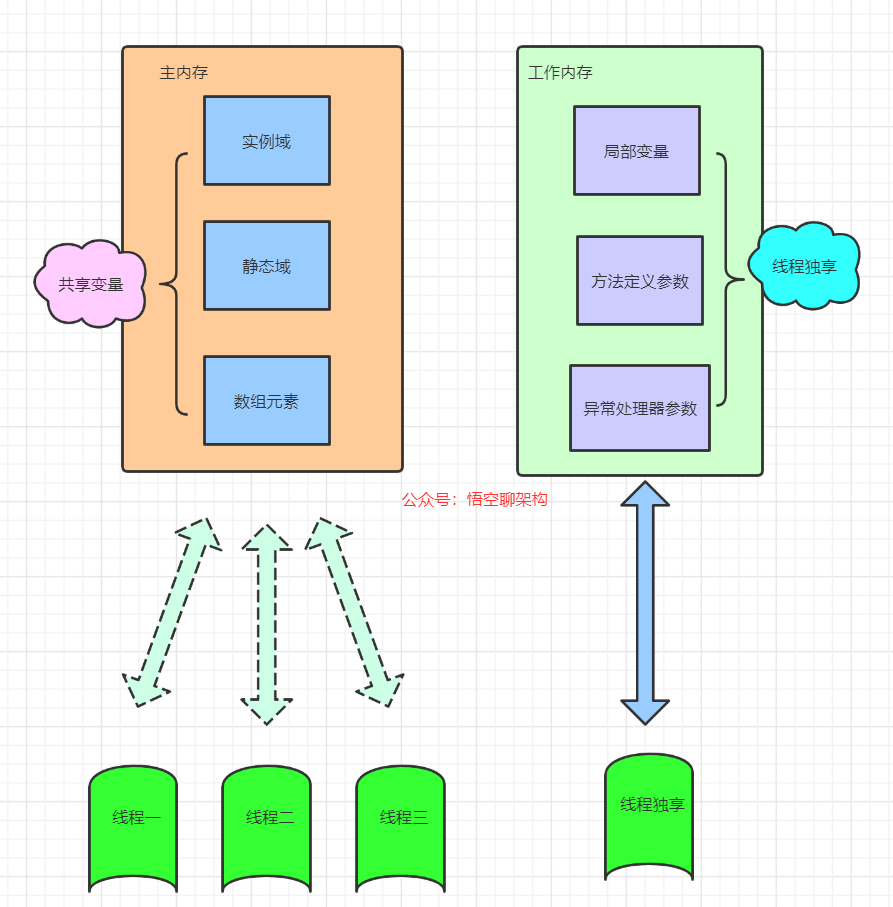
- 主內存
- Java堆中對象實例數據部分
- 對應於物理硬件的內存
- 工作內存
- Java棧中的部分區域
- 優先存儲於寄存器和高速緩存
3.4 Java內存模型是怎麼做的?
Java內存模型的幾個規範:
-
1.所有變量存儲在主內存
-
2.主內存是虛擬機內存的一部分
-
3.每條線程有自己的工作內存
-
4.線程的工作內存保存變量的主內存副本
-
5.線程對變量的操作必須在工作內存中進行
-
6.不同線程之間無法直接訪問對方工作內存中的變量
-
7.線程間變量值的傳遞均需要通過主內存來完成
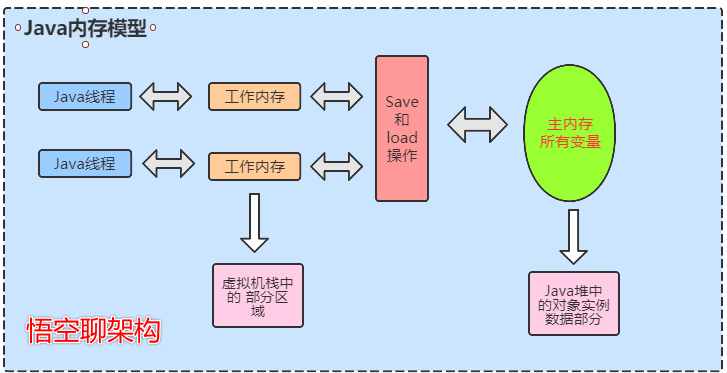
由於JVM運行程序的實體是線程,而每個線程創建時JVM都會為其創建一個工作內存(有些地方稱為棧空間),工作內存是每個線程的私有數據區域,而Java內存模型中規定所有變量都存儲在主內存,主內存是共享內存區域,所有線程都可以訪問,但線程對變量的操作(讀取賦值等)必須在工作內存中進行,首先要將變量從主內存拷貝到自己的工作內存空間,然後對變量進行操作,操作完成後再將變量寫會主內存,不能直接操作主內存中的變量,各個線程中的工作內存中存儲着主內存中的變量副本拷貝,因此不同的線程間無法訪問對方的工作內存,線程間的通信(傳值)必須通過主內存來完成,其簡要訪問過程:
3.5 Java內存模型的三大特性
- 可見性(當一個線程修改了共享變量的值時,其他線程能夠立即得知這個修改)
- 原子性(一個操作或一系列操作是不可分割的,要麼同時成功,要麼同時失敗)
- 有序性(變量賦值操作的順序與程序代碼中的執行順序一致)
關於有序性:如果在本線程內觀察,所有的操作都是有序的;如果在一個線程中觀察另一個線程,所有的操作都是無序的。前半句是指「線程內似表現為串行的語義」(Within-Thread As-If-Serial Semantics),後半句是指「指令重排序」現象和「工作內存與主內存同步延遲」現象。
四、能給個示例說下怎麼用volatile的嗎?
考慮一下這種場景:
有一個對象的字段
number初始化值=0,另外這個對象有一個公共方法setNumberTo100()可以設置number = 100,當主線程通過子線程來調用setNumberTo100()後,主線程是否知道number值變了呢?答案:如果沒有使用volatile來定義number變量,則主線程不知道子線程更新了number的值。
(1)定義如上述所說的對象:ShareData
class ShareData {
int number = 0;
public void setNumberTo100() {
this.number = 100;
}
}
(2)主線程中初始化一個子線程,名字叫做子線程
子線程先休眠3s,然後設置number=100。主線程不斷檢測的number值是否等於0,如果不等於0,則退出主線程。
public class volatileVisibility {
public static void main(String[] args) {
// 資源類
ShareData shareData = new ShareData();
// 子線程 實現了Runnable接口的,lambda表達式
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t come in");
// 線程睡眠3秒,假設在進行運算
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 修改number的值
myData.setNumberTo100();
// 輸出修改後的值
System.out.println(Thread.currentThread().getName() + "\t update number value:" + myData.number);
}, "子線程").start();
while(myData.number == 0) {
// main線程就一直在這裡等待循環,直到number的值不等於零
}
// 按道理這個值是不可能打印出來的,因為主線程運行的時候,number的值為0,所以一直在循環
// 如果能輸出這句話,說明子線程在睡眠3秒後,更新的number的值,重新寫入到主內存,並被main線程感知到了
System.out.println(Thread.currentThread().getName() + "\t 主線程感知到了 number 不等於 0");
/**
* 最後輸出結果:
* 子線程 come in
* 子線程 update number value:100
* 最後線程沒有停止,並行沒有輸出"主線程知道了 number 不等於0"這句話,說明沒有用volatile修飾的變量,變量的更新是不可見的
*/
}
}
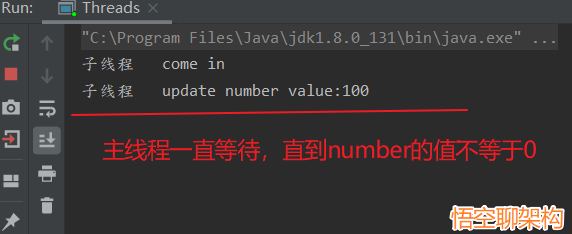
(3)我們用volatile修飾變量number
class ShareData {
//volatile 修飾的關鍵字,是為了增加多個線程之間的可見性,只要有一個線程修改了內存中的值,其它線程也能馬上感知
volatile int number = 0;
public void setNumberTo100() {
this.number = 100;
}
}
輸出結果:
子線程 come in
子線程 update number value:100
main 主線程知道了 number 不等於 0
Process finished with exit code 0
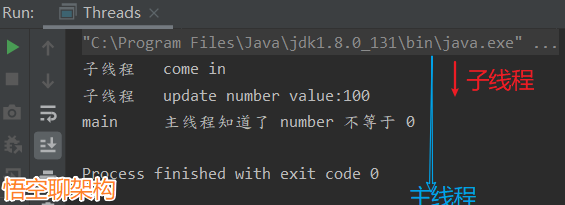
小結:說明用volatile修飾的變量,當某線程更新變量後,其他線程也能感知到。
五、那為什麼其他線程能感知到變量更新?

其實這裡就是用到了「窺探(snooping)」協議。在說「窺探(snooping)」協議之前,首先談談緩存一致性的問題。
5.1 緩存一致性
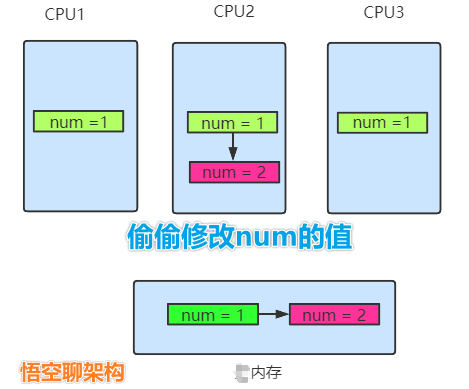
當多個CPU持有的緩存都來自同一個主內存的拷貝,當有其他CPU偷偷改了這個主內存數據後,其他CPU並不知道,那拷貝的內存將會和主內存不一致,這就是緩存不一致。那我們如何來保證緩存一致呢?這裡就需要操作系統來共同制定一個同步規則來保證,而這個規則就有MESI協議。
如下圖所示,CPU2 偷偷將num修改為2,內存中num也被修改為2,但是CPU1和CPU3並不知道num值變了。
5.2 MESI
當CPU寫數據時,如果發現操作的變量是共享變量,即在其它CPU中也存在該變量的副本,系統會發出信號通知其它CPU將該內存變量的緩存行設置為無效。如下圖所示,CPU1和CPU3 中num=1已經失效了。
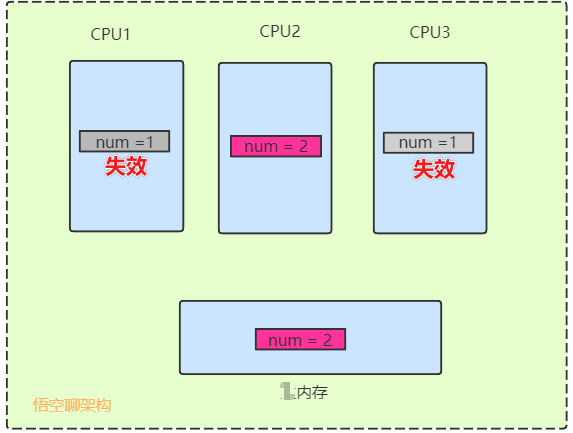
當其它CPU讀取這個變量的時,發現自己緩存該變量的緩存行是無效的,那麼它就會從內存中重新讀取。
如下圖所示,CPU1和CPU3發現緩存的num值失效了,就重新從內存讀取,num值更新為2。
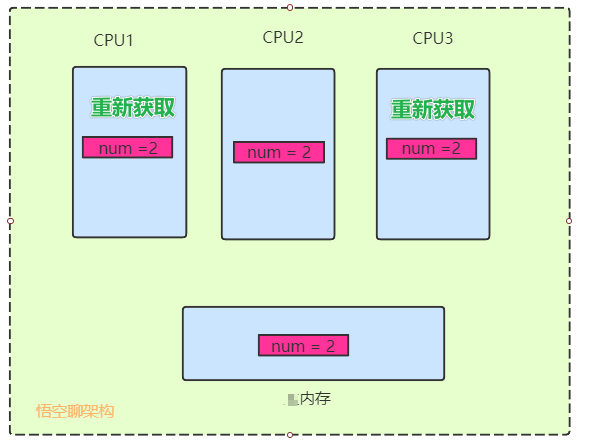
5.3 總線嗅探
那其他CPU是怎麼知道要將緩存更新為失效的呢?這裡是用到了總線嗅探技術。
每個CPU不斷嗅探總線上傳播的數據來檢查自己緩存值是否過期了,如果處理器發現自己的緩存行對應的內存地址被修改,就會將當前處理器的緩存行設置為無效狀態,當處理器對這個數據進行修改操作的時候,會重新從內存中把數據讀取到處理器緩存中。
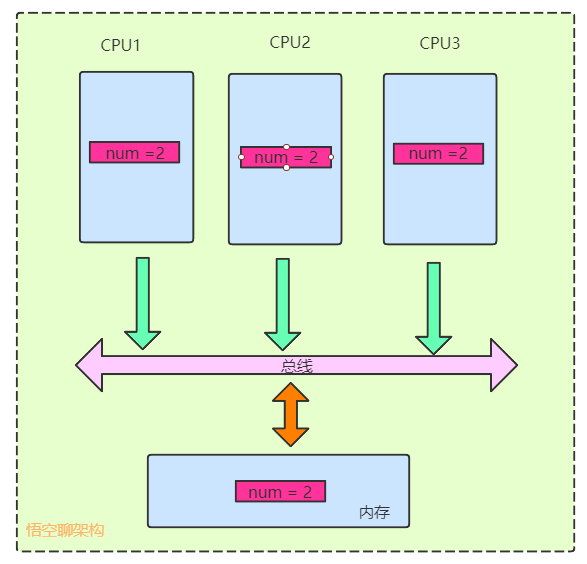
5.4 總線風暴
總線嗅探技術有哪些缺點?
由於MESI緩存一致性協議,需要不斷對主線進行內存嗅探,大量的交互會導致總線帶寬達到峰值。因此不要濫用volatile,可以用鎖來替代,看場景啦~
六、能演示下volatile為什麼不保證原子性嗎?
原子性:一個操作或一系列操作是不可分割的,要麼同時成功,要麼同時失敗。
這個定義和volatile啥關係呀,完全不能理解呀?Show me the code!
考慮一下這種場景:
當20個線程同時給number自增1,執行1000次以後,number的值為多少呢?
在單線程的場景,答案是20000,如果是多線程的場景下呢?答案是可能是20000,但很多情況下都是小於20000。
示例代碼:
package com.jackson0714.passjava.threads;
/**
演示volatile 不保證原子性
* @create: 2020-08-13 09:53
*/
public class VolatileAtomicity {
public static volatile int number = 0;
public static void increase() {
number++;
}
public static void main(String[] args) {
for (int i = 0; i < 50; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
increase();
}
}, String.valueOf(i)).start();
}
// 當所有累加線程都結束
while(Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println(number);
}
}
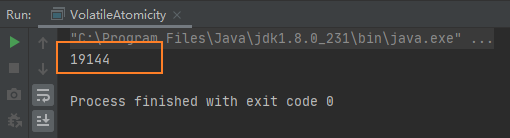
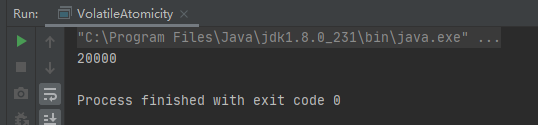
執行結果:第一次19144,第二次20000,第三次19378。
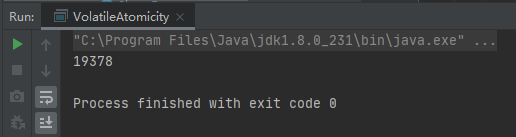
我們來分析一下increase()方法,通過反編譯工具javap得到如下彙編代碼:
public static void increase();
Code:
0: getstatic #2 // Field number:I
3: iconst_1
4: iadd
5: putstatic #2 // Field number:I
8: return
number++其實執行了3條指令:
getstatic:拿number的原始值
iadd:進行加1操作
putfield:把加1後的值寫回
執行了getstatic指令number的值取到操作棧頂時,volatile關鍵字保證了number的值在此時是正確的,但是在執行iconst_1、iadd這些指令的時候,其他線程可能已經把number的值改變了,而操作棧頂的值就變成了過期的數據,所以putstatic指令執行後就可能把較小的number值同步回主內存之中。
總結如下:
在執行number++這行代碼時,即使使用volatile修飾number變量,在執行期間,還是有可能被其他線程修改,沒有保證原子性。
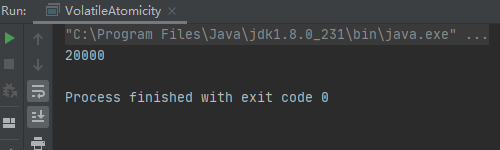
七、怎麼保證輸出結果是20000呢?
7.1 synchronized同步代碼塊
我們可以通過使用synchronized同步代碼塊來保證原子性。從而使結果等於20000
public synchronized static void increase() {
number++;
}
但是使用synchronized太重了,會造成阻塞,只有一個線程能進入到這個方法。我們可以使用Java並發包(JUC)中的AtomicInterger工具包。
7.2 AtomicInterger原子性操作
我們來看看AtomicInterger原子自增的方法getAndIncrement()
public static AtomicInteger atomicInteger = new AtomicInteger();
public static void main(String[] args) {
for (int i = 0; i < 20; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
atomicInteger.getAndIncrement();
}
}, String.valueOf(i)).start();
}
// 當所有累加線程都結束
while(Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println(atomicInteger);
}
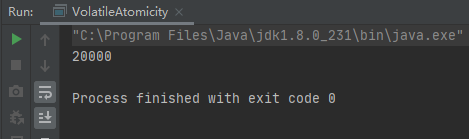
多次運行的結果都是20000。
八、禁止指令重排又是啥?
說到指令重排就得知道為什麼要重排,有哪幾種重排。
如下圖所示,指令執行順序是按照1>2>3>4的順序,經過重排後,執行順序更新為指令3->4->2->1。
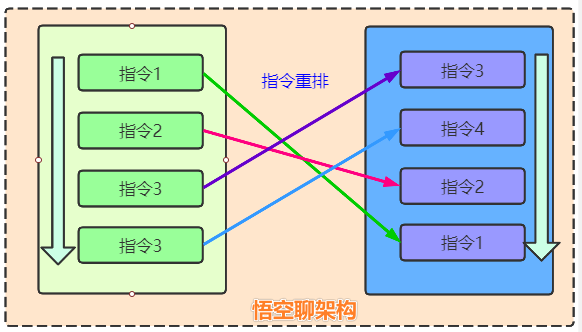
會不會感覺到重排把指令順序都打亂了,這樣好嗎?
可以回想下小學時候的數學題:2+3-5=?,如果把運算順序改為3-5+2=?,結果也是一樣的。所以指令重排是要保證單線程下程序結果不變的情況下做重排。
8.1 為什麼要重排
計算機在執行程序時,為了提高性能,編譯器和處理器常常會對指令做重排序。
8.2 有哪幾種重排
-
1.編譯器優化重排:編譯器在不改變單線程程序語義的前提下,可以重新安排語句的執行順序。
-
2.指令級的並行重排:現代處理器採用了指令級並行技術來將多條指令重疊執行。如果不存在數據依賴性,處理器可以改變語句對應機器指令的執行順序。
-
3.內存系統的重排:由於處理器使用緩存和讀/寫緩衝區,這使得加載和存儲操作看上去可能是在亂序執行。

注意:
-
單線程環境裏面確保最終執行結果和代碼順序的結果一致
-
處理器在進行重排序時,必須要考慮指令之間的
數據依賴性 -
多線程環境中線程交替執行,由於編譯器優化重排的存在,兩個線程中使用的變量能否保證一致性是無法確定的,結果無法預測。
8.3 舉個例子來說說多線程中的指令重排?
設想一下這種場景:定義了變量num=0和變量flag=false,線程1調用初始化函數init()執行後,線程調用add()方法,當另外線程判斷flag=true後,執行num+100操作,那麼我們預期的結果是num會等於101,但因為有指令重排的可能,num=1和flag=true執行順序可能會顛倒,以至於num可能等於100
public class VolatileResort {
static int num = 0;
static boolean flag = false;
public static void init() {
num= 1;
flag = true;
}
public static void add() {
if (flag) {
num = num + 5;
System.out.println("num:" + num);
}
}
public static void main(String[] args) {
init();
new Thread(() -> {
add();
},"子線程").start();
}
}
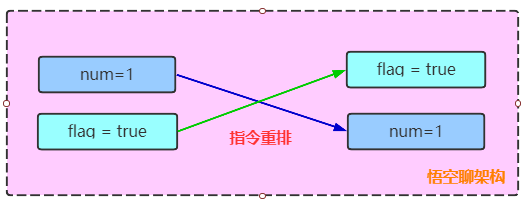
先看線程1中指令重排:
num= 1;flag = true; 的執行順序變為 flag=true;num = 1;,如下圖所示的時序圖
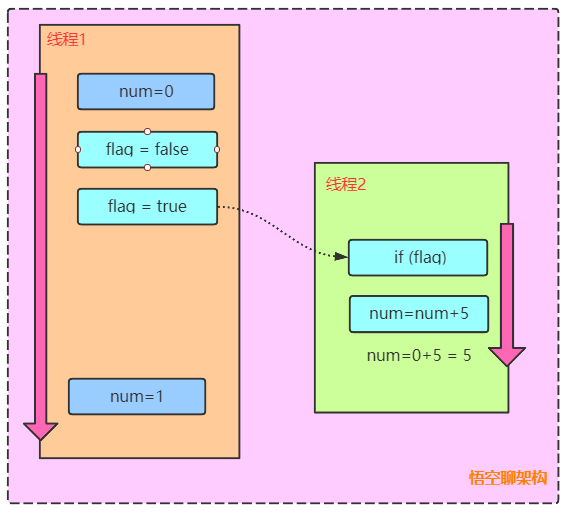
如果線程2 num=num+5 在線程1設置num=1之前執行,那麼線程2的num變量值為5。如下圖所示的時序圖。
8.4 volatile怎麼實現禁止指令重排?
我們使用volatile定義flag變量:
static volatile boolean flag = false;
如何實現禁止指令重排:
原理:在volatile生成的指令序列前後插入內存屏障(Memory Barries)來禁止處理器重排序。
有如下四種內存屏障:

volatile寫的場景如何插入內存屏障:
-
在每個volatile寫操作的前面插入一個StoreStore屏障(寫-寫 屏障)。
-
在每個volatile寫操作的後面插入一個StoreLoad屏障(寫-讀 屏障)。
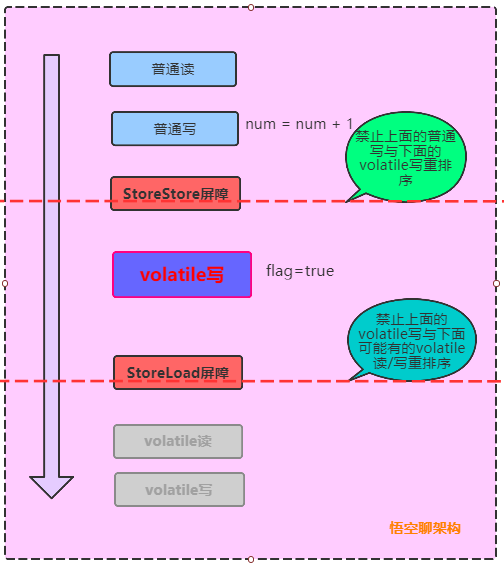
StoreStore屏障可以保證在volatile寫(flag賦值操作flag=true)之前,其前面的所有普通寫(num的賦值操作num=1) 操作已經對任意處理器可見了,保障所有普通寫在volatile寫之前刷新到主內存。
volatile讀場景如何插入內存屏障:
-
在每個volatile讀操作的後面插入一個LoadLoad屏障(讀-讀 屏障)。
-
在每個volatile讀操作的後面插入一個LoadStore屏障(讀-寫 屏障)。
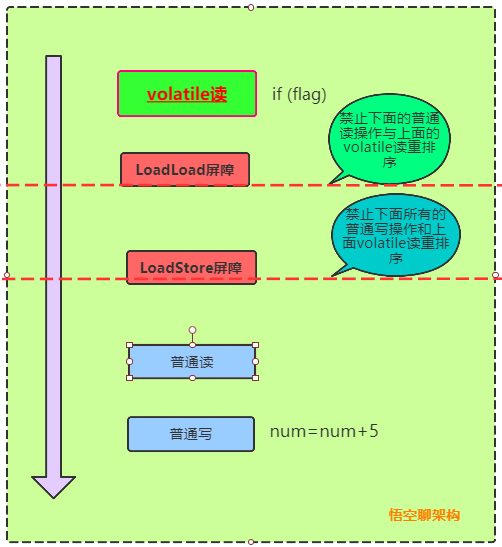
LoadStore屏障可以保證其後面的所有普通寫(num的賦值操作num=num+5) 操作必須在volatile讀(if(flag))之後執行。
十、volatile常見應用
這裡舉一個應用,雙重檢測鎖定的單例模式
package com.jackson0714.passjava.threads;
/**
演示volatile 單例模式應用(雙邊檢測)
* @author: 悟空聊架構
* @create: 2020-08-17
*/
class VolatileSingleton {
private static VolatileSingleton instance = null;
private VolatileSingleton() {
System.out.println(Thread.currentThread().getName() + "\t 我是構造方法SingletonDemo");
}
public static VolatileSingleton getInstance() {
// 第一重檢測
if(instance == null) {
// 鎖定代碼塊
synchronized (VolatileSingleton.class) {
// 第二重檢測
if(instance == null) {
// 實例化對象
instance = new VolatileSingleton();
}
}
}
return instance;
}
}
代碼看起來沒有問題,但是 instance = new VolatileSingleton();其實可以看作三條偽代碼:
memory = allocate(); // 1、分配對象內存空間
instance(memory); // 2、初始化對象
instance = memory; // 3、設置instance指向剛剛分配的內存地址,此時instance != null
步驟2 和 步驟3之間不存在 數據依賴關係,而且無論重排前 還是重排後,程序的執行結果在單線程中並沒有改變,因此這種重排優化是允許的。
memory = allocate(); // 1、分配對象內存空間
instance = memory; // 3、設置instance指向剛剛分配的內存地址,此時instance != null,但是對象還沒有初始化完成
instance(memory); // 2、初始化對象
如果另外一個線程執行:if(instance == null) 時,則返回剛剛分配的內存地址,但是對象還沒有初始化完成,拿到的instance是個假的。如下圖所示:
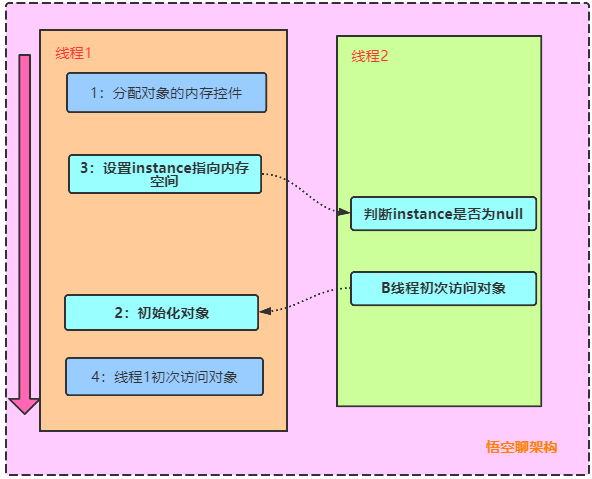
解決方案:定義instance為volatile變量
private static volatile VolatileSingleton instance = null;
十一、volatile都不保證原子性,為啥我們還要用它?
奇怪的是,volatile都不保證原子性,為啥我們還要用它?
volatile是輕量級的同步機制,對性能的影響比synchronized小。
典型的用法:檢查某個狀態標記以判斷是否退出循環。
比如線程試圖通過類似於數綿羊的傳統方法進入休眠狀態,為了使這個示例能正確執行,asleep必須為volatile變量。否則,當asleep被另一個線程修改時,執行判斷的線程卻發現不了。
那為什麼我們不直接用synchorized,lock鎖?它們既可以保證可見性,又可以保證原子性為何不用呢?
因為synchorized和lock是排他鎖(悲觀鎖),如果有多個線程需要訪問這個變量,將會發生競爭,只有一個線程可以訪問這個變量,其他線程被阻塞了,會影響程序的性能。
注意:當且僅當滿足以下所有條件時,才應該用volatile變量
- 對變量的寫入操作不依賴變量的當前值,或者你能確保只有單個線程更新變量的值。
- 該變量不會與其他的狀態一起納入不變性條件中。
- 在訪問變量時不需要加鎖。
十二、volatile和synchronzied的區別
- volatile只能修飾實例變量和類變量,synchronized可以修飾方法和代碼塊。
- volatile不保證原子性,而synchronized保證原子性
- volatile 不會造成阻塞,而synchronized可能會造成阻塞
- volatile 輕量級鎖,synchronized重量級鎖
- volatile 和synchronized都保證了可見性和有序性
十三、小結
- volatile 保證了可見性:當一個線程修改了共享變量的值時,其他線程能夠立即得知這個修改。
- volatile 保證了單線程下指令不重排:通過插入內存屏障保證指令執行順序。
- volatitle不保證原子性,如a++這種自增操作是有並發風險的,比如扣減庫存、發放優惠券的場景。
- volatile 類型的64位的long型和double型變量,對該變量的讀/寫具有原子性。
- volatile 可以用在雙重檢鎖的單例模式種,比synchronized性能更好。
- volatile 可以用在檢查某個狀態標記以判斷是否退出循環。
期待後篇么?CAS走起!
我是悟空,越挫越勇的悟空,奧利給!

參考資料:
《深入理解Java虛擬機》
《Java並發編程的藝術》
《Java並發編程實戰》


