如何通過 Docker 部署 Logstash 同步 Mysql 數據庫數據到 ElasticSearch
- 2019 年 10 月 25 日
- 筆記
在開發過程中,我們經常會遇到對業務數據進行模糊搜索的需求,例如電商網站對於商品的搜索,以及內容網站對於內容的關鍵字檢索等等。對於這些高級的搜索功能,顯然數據庫的 Like 是不合適的,通常我們採用 ElasticSearch 來完成數據的搜索和分析,有了這個利器,我們可以輕鬆應對上述場景,實現關鍵字搜索等功能。
不過,由於增加了 ElasticSearch 作為搜索引擎,隨之而來的問題就是,如何將業務中的數據同步到 ElasticSearch 中,主要有兩種方式:
- 業務雙寫(具有侵入性)
- 數據庫同步
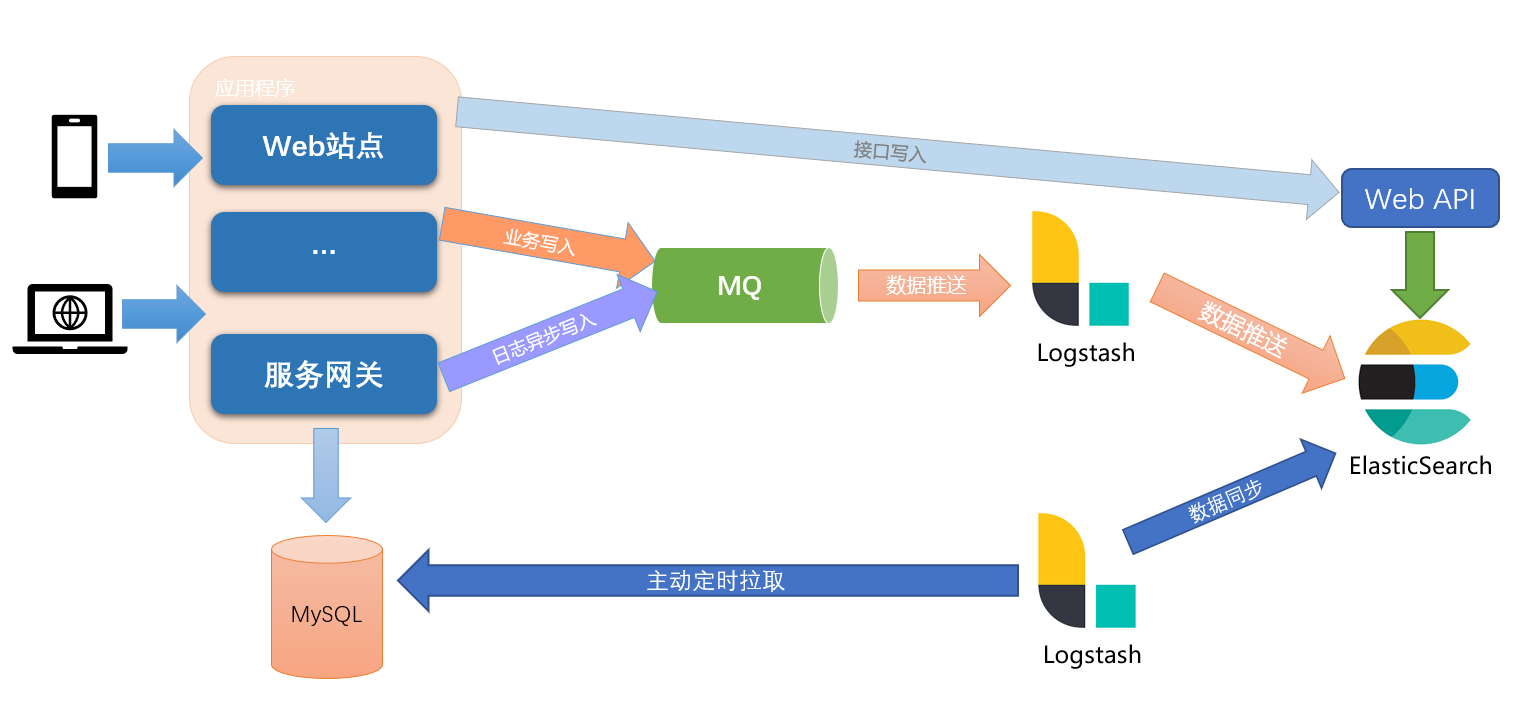
由於業務雙寫需要更改業務代碼,一般不建議採用此種方式,除非有強一致性要求,或者對業務侵入不敏感的系統可以採取此種方式:
- 強一致性:同步通過HTTP請求寫入 ElasticSearch
- 最終一致性:
- 可採取業務寫入日誌,後端通過日誌流數據過濾寫入 ElasticSearch(ELK標準模式,推薦)
- 另一種方案就是同步寫入 MQ,後端通過消費MQ異步寫入 ElasticSearch
本文主要討論非代碼侵入的數據庫同步方式,主要採用的是通過 LogStash 定時掃描數據庫來增量同步數據的方案。
數據庫腳本
數據庫表結構中,需要有一個時間類型的字段作為增量更新的標識字段(例如 lastupdatetime),當該條數據更新時,必須同時更新該字段。
CREATE TABLE user ( `id` int(11) NOT NULL, `name` varchar(50) NOT NULL, `age` int(11) NOT NULL, `createtime` datetime(0) NOT NULL, `lastupdatetime` datetime(0) NOT NULL, PRIMARY KEY (`id`) USING BTREE ) INSERT INTO `user` VALUES(1,"jack",18,Now(),Now()) INSERT INTO `user` VALUES(2,"William",18,Now(),Now()) SELECT * from `user`查詢結果:
| id | name | age | createtime | lastupdatetime |
|---|---|---|---|---|
| 1 | jack | 18 | 2019-10-24 10:31:14 | 2019-10-24 10:31:14 |
| 2 | William | 18 | 2019-10-24 10:31:49 | 2019-10-24 10:31:49 |
LogStash 配置信息
logstash docker 安裝腳本:
mkdir /opt/logstashsync/
mkdir /opt/logstashsync/pipeline
vi /opt/logstashsync/pipeline/logstash.conf
input { jdbc { jdbc_driver_library => "/app/mysql-connector-java-8.0.18.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.10.102:3306/synctest" jdbc_user => "root" jdbc_password => "123456" tracking_column => "unix_ts_in_secs" use_column_value => true schedule => "*/5 * * * * *" statement => "SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > :sql_last_value AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC" } } filter { mutate { copy => { "id" => "[@metadata][_id]"} remove_field => ["id", "@version", "unix_ts_in_secs"] } } output { elasticsearch { hosts => "192.168.10.102:9200" index => "syncuser" timeout => 300 document_id => "%{[@metadata][_id]}" } }上述配置說明:
- jdbc_driver_library:logstash的鏡像中並不包含 jdbc connector,需要在官方網站中下載下來之後,在容器啟動時映射到容器中,可點此下載。
- tracking_column:用於跟蹤 Logstash從MySQL讀取的最後最後一條數據的 lastupdatetime 的值,並默認持久化到磁盤文件 .logstash_jdbc_last_run 中。該值用於在下一次循環同步時,同步的起始值,從而達到增量同步的作用,存儲在 .logstash_jdbc_last_run 在 SQL 語句中可以以 :sql_last_value 訪問。
- schedule:設置多久循環同步一次,以cron語法指定,我們當前設置的是5秒一次循環。
- statement:執行同步的SQL語句。值得注意的是where條件中為什麼要這麼寫,可以參考 https://www.elastic.co/blog/how-to-keep-elasticsearch-synchronized-with-a-relational-database-using-logstash 文章中給定的解釋。
- 重要: 關於上述配置中的 [@metadata][_id],在同步過程中,必須使用數據庫數據id作為 ElasticSearch 中的文檔 _id,這樣當數據庫中該條數據有修改時,ElasticSearch 中的文檔才會相應的同步修改,否則會以一條新的數據插入 ElasticSearch,導致數據同步錯誤。
有了上述配置,我們把 Logstath 的 docker 容器跑起來:
docker run -d -v /opt/logstashsync/config/logstash.yml:/usr/share/logstash/config/logstash.yml -v /opt/logstashsync/pipeline/logstash.conf:/usr/share/logstash/pipeline/logstash.conf -v /opt/logstashsync/mysql-connector-java-8.0.18.jar:/app/mysql-connector-java-8.0.18.jar --name=logstash logstash:6.7.1注意:上述腳本可以看到,我們將本地 /opt/logstashsync/ 目錄下的 mysql-connector-java-8.0.18.jar 映射到了容器的 /app 目錄下,對應在上述 logstash.conf 中的配置的 jdbc_driver_library 的值
通過查看 Logstash 容器運行日誌,我們可以看到如下日誌內容,說明該容易已經按照我們預期的每5s同步一次數據庫:
[2019-10-25T06:27:59,056][INFO ][logstash.inputs.jdbc ] (0.039651s) SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > 0 AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC [2019-10-25T06:28:05,154][INFO ][logstash.inputs.jdbc ] (0.004232s) SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > 1571913109 AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC [2019-10-25T06:28:10,230][INFO ][logstash.inputs.jdbc ] (0.002832s) SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > 1571913109 AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC 通過Kibana查詢同步結果
在 Kibana 中創建 syncuser index,即可以查看到已經同步的數據:

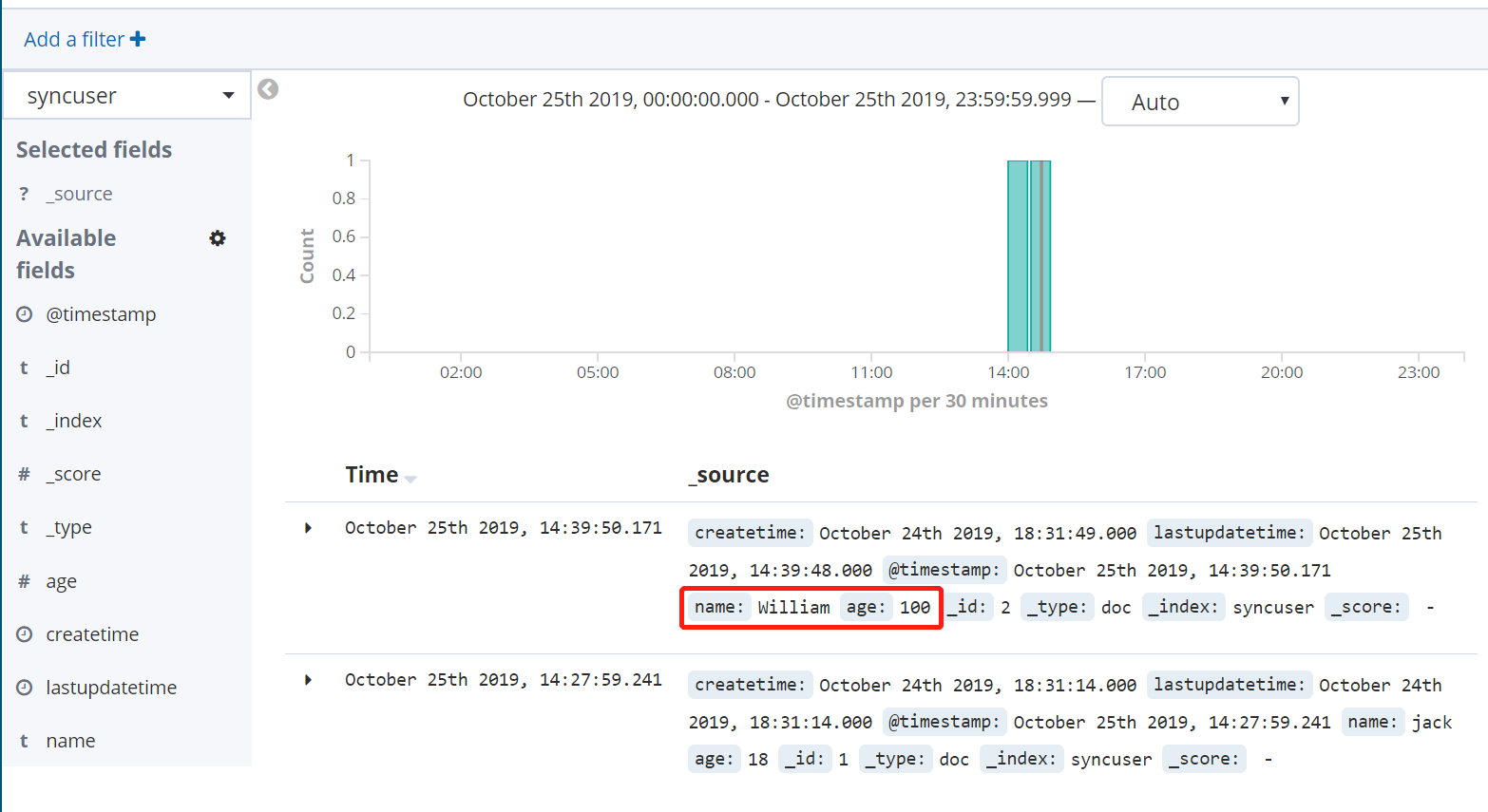
嘗試對數據庫數據做更新操作,將名為 William 的用戶年齡修改為100(記得同時要更新lastupdatetime 字段):
UPDATE `user` SET age=100, lastupdatetime=NOW() WHERE `name`='William'; SELECT * from `user`
再次查看 Kibana 中的數據,可以看到該數據已經成功同步:
結語
根據上述過程,我們完成了簡單的單表數據定時同步至 ElasticSearch 過程,但是在實際使用過程中,需要注意以下問題:
- sql語句需要考慮每次同步最大條數。大多數情況下,數據庫可能已經存在大量數據,如果不做控制,可能會導致 Logstash 剛啟動時一次同步的數據量過大,發生異常,採取的方式可以在 SQL 語句中增加每次獲取最大條數限制。
- 增量更新的標識字段,既然是通過>號方式判斷,那麼如果id是自增主鍵,也可以採用 int 類型的主鍵字段,這樣可以減少在數據庫中創建 lastupdatetime 索引。但如果不是主鍵,則需要謹慎使用,具體原因請仔細參考上述配置說明中 statement 給出的鏈接。
- 由於增量同步機制所致,所有數據庫中的刪除操作應該以軟刪除的方式進行,即增加 is_delete 字段,否則如果硬刪除會導致該條數據狀態無法同步至 ElasticSearch,當然在查詢 ElasticSearch 時,也應該增加該條件,排除已經刪除的數據。

