【樸素貝葉斯】理解與使用
1:原理理解
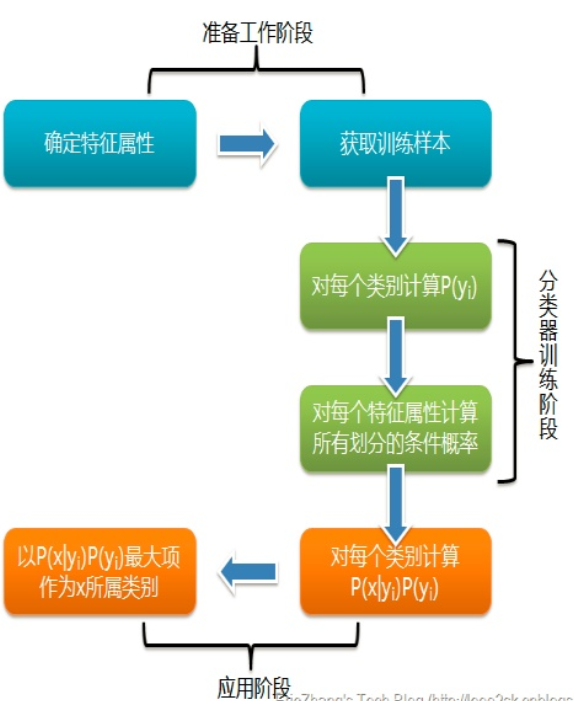
舉個形象的例子,若我們走在街上看到一個黑皮膚的外國友人,讓你來猜這位外國友人來自哪裡。十有八九你會猜是從非洲來的,因為黑皮膚人種中非洲人的佔比最多,雖然黑皮膚的外國人也有可能是美洲人或者是亞洲人。但是在沒有其它可用信息幫助我們判斷的情況下,我們會選擇可能出現的概率最高的類別,這就是樸素貝葉斯的基本思想。值得注意的是,樸素貝葉斯分類並非是瞎猜,也並非沒有任何理論依據。它是以貝葉斯理論和特徵條件獨立假設為基礎的分類算法。想要弄明白算法的原理,首先需要理解什麼是「特徵條件獨立假設」以及「貝葉斯定理」,而貝葉斯定理又牽涉到「先驗概率」、「後驗概率」及「條件概率」的概念,如下圖所示,雖然概念比較多但是都比較容易理解,下面我們逐個詳細介紹。

特徵條件獨立假設是貝葉斯分類的基礎,意思是假定該樣本中每個特徵與其他特徵之間都不相關。例如在預測信用卡客戶逾期的例子中,我們會通過客戶的月收入、信用卡額度、房車情況等不同方面的特徵綜合判斷。兩件看似不相關的事情實際上可能存在內在聯繫,就像蝴蝶效應一樣。普遍情況下,銀行批給收入較高的客戶的信用卡額度也比較高。同時收入高也代表這個客戶更有能力購買房產,所以這些特徵之間存在一定的依賴關係,某些特徵是由其他特徵決定的。然而在樸素貝葉斯算法中,我們會忽略這種特徵之間的內在關係,直接認為客戶的月收入、房產與信用卡額度之間沒有任何關係,三者是各自獨立的特徵。
2:真假概率
首先我們進行一個小實驗。假設將一枚質地均勻的硬幣拋向空中,理論上,因為硬幣的正反面質地均勻,落地時正面朝上或反面朝上的概率都是50%。這個概率不會隨着拋擲次數的增減而變化,哪怕拋了10次結果都是正面朝上,下一次是正面朝上的概率仍然是50%。
但在實際測試中,如果我們拋100次硬幣,正面朝上和反面朝上的次數通常不會恰好都是50次。有可能出現40次正面朝上和60次反面朝上的情況,也有可能出現35次正面朝上和65次反面朝上的情況。
只有我們一直拋,拋了成千上萬次,硬幣正面朝上與反面朝上的次數才會逐漸趨向於相等。
因此,我們說「正面朝上和反面朝上各有50%的概率」這句話所指的概率是理論上的客觀概率。只有當拋擲次數接近無數次時,才會達到這種理想中的概率。在理論概率下,儘管拋10次硬幣,前面5次都是正面朝上,第6次是反面朝上的概率仍然是50%。
但是在實際中,拋過硬幣的人都有這樣的感覺,如果出現連續5次正面朝上的情況,下一次是反面朝上的可能性極大,大到什麼程度?有沒有什麼方法可以求出實際的概率呢?
為了解決這個問題,一位名叫托馬斯·貝葉斯(ThomasBayes)的數學家發明了一種方法用於計算「在已知條件下,另外一個事件發生」的概率。該方法要求我們先預估一個主觀的先驗概率,再根據後續觀察到的結果進行調整,隨着調整次數的增加,真實的概率會越來越精確。
3:使用
import numpy as np import sklearn.naive_bayes as sk_bayes import sklearn.datasets as datasets iris = datasets.load_iris() # 鳥分類數據集 X = iris['data'] y = iris['target'] from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2) print("訓練集:",X_train.shape,y_train.shape) print("測試集:",X_test.shape,y_test.shape)
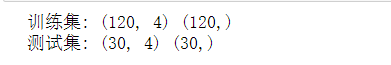
model = sk_bayes.MultinomialNB(alpha=1.0,fit_prior=True,class_prior=None) #多項式分佈的樸素貝葉斯 # model = sk_bayes.BernoulliNB(alpha=1.0,binarize=0.0,fit_prior=True,class_prior=None) #伯努利分佈的樸素貝葉斯 model = sk_bayes.GaussianNB()#高斯分佈的樸素貝葉斯 model.fit(X_train,y_train) acc=model.score(X_test,y_test) #根據給定數據與標籤返回正確率的均值 print('n樸素貝葉斯(高斯分佈)模型評價:',acc)




