Pytorch_第九篇_神經網絡中常用的激活函數
神經網絡中常用的激活函數
Introduce
理論上神經網絡能夠擬合任意線性函數,其中主要的一個因素是使用了非線性激活函數(因為如果每一層都是線性變換,那有啥用啊,始終能夠擬合的都是線性函數啊)。本文主要介紹神經網絡中各種常用的激活函數。
以下均為個人學習筆記,若有錯誤望指出。
各種常用的激活函數
早期研究神經網絡常常用sigmoid函數以及tanh函數(下面即將介紹的前兩種),近幾年常用ReLU函數以及Leaky Relu函數(下面即將介紹的後兩種)。torch中封裝了各種激活函數,可以通過以下方式來進行調用:
torch.sigmoid(x)
torch.tanh(x)
torch.nn.functional.relu(x)
torch.nn.functional.leaky_relu(x,α)
對於各個激活函數,以下分別從其函數公式、函數圖像、導數圖像以及優缺點來進行介紹。
(1) sigmoid 函數:
sigmoid函數是早期非常常用的一個函數,但是由於其諸多缺點現在基本很少使用了,基本上只有在做二分類時的輸出層才會使用。
sigmoid 的函數公式如下:
\]
sigmoid函數的導數有一個特殊的性質(導數是關於原函數的函數),導數公式如下:
\]
sigmoid 的函數圖形如下:
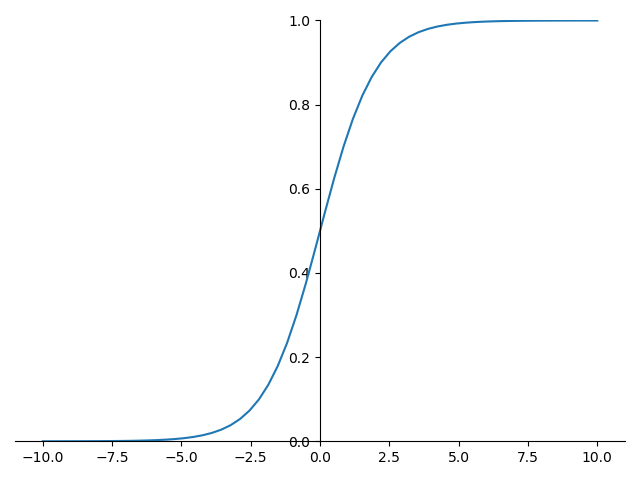
sigmoid 的導數圖形如下:

sigmoid 優點:
- 能夠把輸入的連續值變換為0和1之間的輸出 (可以看成概率)。
- 如果是非常大的負數或者正數作為輸入的話,其輸出分別為0或1,即輸出對輸入比較不敏感,參數更新比較穩定。
sigmoid 缺點:
- 在深度神經網絡反向傳播梯度時容易產生梯度消失(大概率)和梯度爆炸(小概率)問題。根據求導的鏈式法則,我們都知道一般神經網絡損失對於參數的求導涉及一系列偏導以及權重連乘,那連乘會有什麼問題呢?如果隨機初始化各層權重都小於1(注意到以上sigmoid導數不超過0.25,也是一個比較小的數),即各個連乘項都很小的話,接近0,那麼最終很多很多連乘(對應網絡中的很多層)會導致最終求得梯度為0,這就是梯度消失現象(大概率發生)。同樣地,如果我們隨機初始化權重都大於1(非常大)的話,那麼一直連乘也是可能出現最終求得的梯度非常非常大,這就是梯度爆炸現象(很小概率發生)。
- sigmoid函數的輸出是0到1之間的,並不是以0為中心的(或者說不是關於原點對稱的)。這會導致什麼問題呢?神經網絡反向傳播過程中各個參數w的更新方向(是增加還是減少)是可能不同的,這是由各層的輸入值x決定的(為什麼呢?推導詳見)。有時候呢,在某輪迭代,我們需要一個參數w0增加,而另一個參數w1減少,那如果我們的輸入都是正的話(sigmoid的輸出都是正的,會導致這個問題),那這兩個參數在這一輪迭代中只能都是增加了,這勢必會降低參數更新的收斂速率。當各層節點輸入都是負數的話,也如上分析,即所有參數在這一輪迭代中只能朝同一個方向更新,要麼全增要麼全減。(但是一般在神經網絡中都是一個batch更新一次,一個batch中輸入x有正有負,是可以適當緩解這個情況的)
- sigmoid涉及指數運算,計算效率較低。
(2) tanh 函數
tanh是雙曲正切函數。(一般二分類問題中,隱藏層用tanh函數,輸出層用sigmod函數,但是隨着Relu的出現所有的隱藏層基本上都使用relu來作為激活函數了)
tanh 的函數公式如下:
\]
其導數也具備同sigmoid導數類似的性質,導數公式如下:
\]
tanh 的函數圖形如下:

tanh 的導數圖形如下:
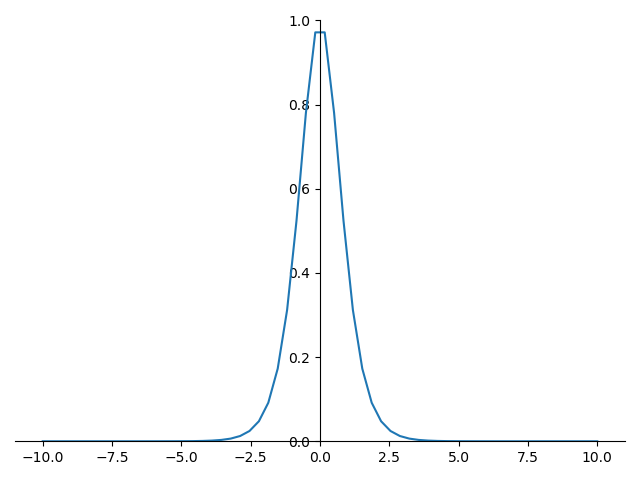
tanh 優點:
- 輸出區間在(-1,1)之間,且輸出是以0為中心的,解決了sigmoid的第二個問題。
- 如果使用tanh作為激活函數,還能起到歸一化(均值為0)的效果。
tanh 缺點:
- 梯度消失的問題依然存在(因為從導數圖中我們可以看到當輸入x偏離0比較多的時候,導數還是趨於0的)。
- 函數公式中仍然涉及指數運算,計算效率偏低。
(3) ReLU 函數
ReLU (Rectified Linear Units) 修正線性單元。ReLU目前仍是最常用的activation function,在隱藏層中推薦優先嘗試!
ReLU 的函數公式如下:
\]
ReLU 的函數圖形如下:
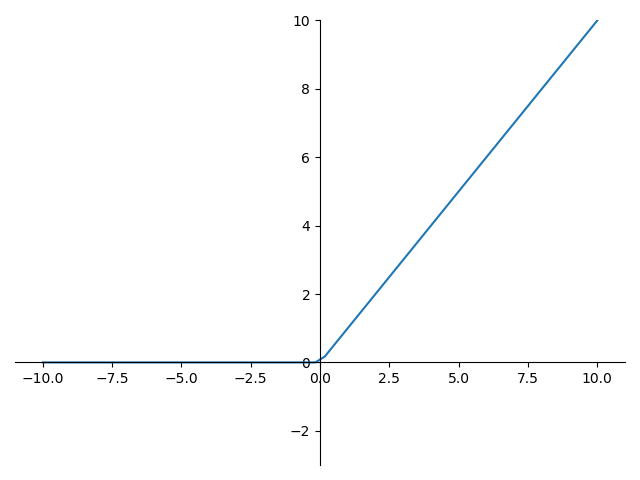
ReLU 的導數圖形如下:

ReLU 優點:
- 梯度計算很快,只要判斷輸入是否大於0即可,這一點加快了基於梯度的優化算法的計算效率,收斂速度遠快於Sigmoid和tanh。
- 在正區間上解決了梯度消失(因為梯度永遠為1,不會連乘等於0)的問題。
ReLU 缺點:
- ReLU 的輸出不是以0為中心的,但是這點可以通過一個batch更新一次參數來緩解。
- Exist Dead ReLU Problem,某些神經元存在死機的問題(永遠不會被激活),這是由於當輸入x小於0的時候梯度永遠為0導致的,梯度為0代表參數不更新(加0減0),這個和sigmoid、tanh存在一樣的問題,即有些情況下梯度很小很小很小,梯度消失。但是實際的運用中,該缺陷的影響不是很大。 因為比較難發生,為什麼呢?因為這種情況主要有兩個原因導致,其一:非常恰巧的參數初始化。神經元的輸入為加權求和,除非隨機初始化恰好得到了一組權值參數使得加權求和變成負數,才會出現梯度為0的現象,然而這個概率是比較低的。其二:學習率設置太大,使得某次參數更新的時候,跨步太大,得到了一個比原先更差的參數。選擇已經有一些參數初始化的方法以及學習率自動調節的算法可以防止出現上述情況。(具體方法筆者暫時還未了解!了解了之後再進行補充)
(4) Leaky Relu 函數(PRelu)
Leaky Relu 的函數公式如下:
\]
以下以α為0.1的情況為例,通常α=0.01,這邊取0.1隻是為了圖形梯度大一點,畫出來比較直觀。
Leaky Relu 的函數圖形如下:
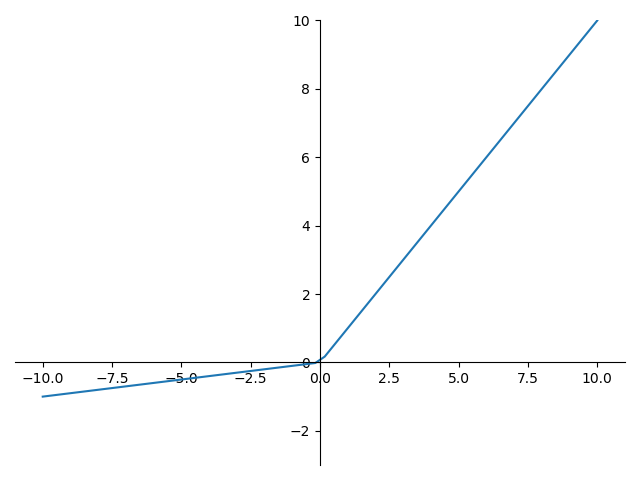
Leaky Relu 的導數圖形如下:
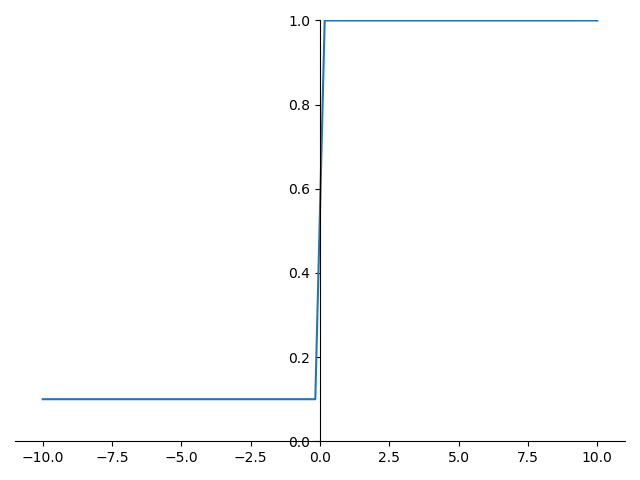
Leaky Relu 優點:
- 解決了relu函數輸入小於0時梯度為0的問題。
- 與ReLU一樣梯度計算快,是常數,只要判斷輸入大於0還是小於0即可。
對於Leaky Relu 的缺點筆者暫時不了解,但是實際應用中,並沒有完全證明Leaky ReLU總是好於ReLU,因此ReLU仍是最常用的激活函數。


