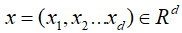內存一致性模型和內存屏障的學習
- 2019 年 10 月 23 日
- 筆記
磕叨
因為大學沒學過java,都是學C++的,工作時陰差陽錯地走歪了,現在成了一個寫業務代碼的程序猿,平時工作多寫java,一部分golang和js,能讓我走歪了也不太走不太差的原因大概是因為大學所學的編譯原理和後來自己在圖書館所學的編程語言範式(函數範式和OO),還有DDD吧。
但其實我多語言的特性了解得非常模糊的,而且這個東西隨着語言工具的新版演進有所捨棄和新增,所以最近決定複習下編譯原理,然後系統的學習下jvm(源碼),也算一個進階的必經之路吧,為什麼選jvm,因為java寫業務代碼,還是思路挺暢順的,另外據說jvm是現在能見到的最好的vm(如果是最好,那java為什麼沒有async/await呢)。
好了,本篇要說的是內存一致性模型,因為要了解一下基本的概念才好繼續深入vm底層,在看JMM時提到一個有意思的東西—內存屏障,以前只知道他的作用,保證多線程執行環境下變量的狀態符合預期結果。內存一致性模型不是有java才關注的,現在的多核計算機編程基本都應該會面臨內存一致性問題。
(網文很多,這個權當學習的筆記,加深下印象)
起因
在芯片設計的領域,在單芯主頻提高慢慢地越來越難,然後某一刻走向了多核時代(?這段可以自己Google去)。這樣,CPU里有多於個1個核心,在同一時間CPU能夠同時運行多個線程,那麼系統的處理能力就得到大大的提升。也帶來了一些副作用,那就是內存一致性的問題。
對CPU而言,主存實在太慢了,所以芯片設計者為CPU設計了高速緩存(高速緩存技術早就出現了)。而起初只有一個高速緩存,後來CPU越跑越快,核心數越來越多,芯片設計者為CPU分級緩存,?後來更複雜了多級緩存了,帶來的性能提升也是喪心病狂的,哈哈,但是基本模型就是這樣 獨立的cache(L1) -> 核心共享的cache(L2) -> 主存(RAM)。我們就在這個基本的模型上展開吧。
但是同時也引入了一些問題。因為而處理核心承載的線程並不是老死不相來往的,現實中很可能他們在處理同一份相關的數據基本的模型。
演進
內存一致性模型和面臨情況
- 下面就從最嚴格的的模型開始一步一步放開約束,變得越來越寬鬆。
a.) 順序存儲模型 SC(sequential consistency model)
-
順序存儲模型是最基本的存儲模型,也是最符合人腦思維的模型。CPU會按照程序中順序依次執行store和load指令,(為了方便理解,這裡假設cache是完美一致的,沒有緩存間的同步問題)
分析一下代碼
core1 core2 S1: store data=NEW S2: store flag=SET L1: load r1=flag B1: if (r1≠SET) goto L1 L2: load r2=data 在順序存儲器模型里,會嚴格按照代碼指令流來執行代碼,上面代碼在主存里的訪問順序是:
S1 S2 L1 L2其訪問行為與UP(單核)上是一致的。我們能得到期望的數據狀態,即r2的值為NEW。
b.) 完全存儲定序 TSO(total store order)
-
(這裡開始燒腦了哦)
按照上面那個兩級告訴緩存和主存的模型,假設最初的變量data僅僅存在主存里,那麼core1執行
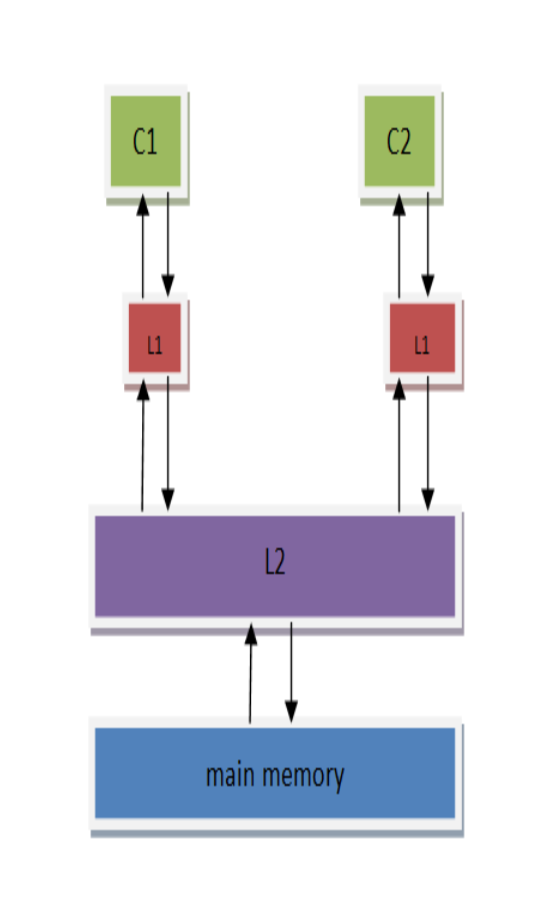
store data=NEW這個cpu指令時,就要先將他從主存加載到緩存(以緩存行的形式),而這個過程很可能過了幾個時鐘周期了,所以芯片設計人員為這個耗時的過程設計了一個store buffer,它的作用是為store指令提供緩衝,使得CPU不用等待存儲器的響應。只要store buffer里還有空間,寫就只需要1個時鐘周期。但這裡也引入了另一個問題—訪問亂序。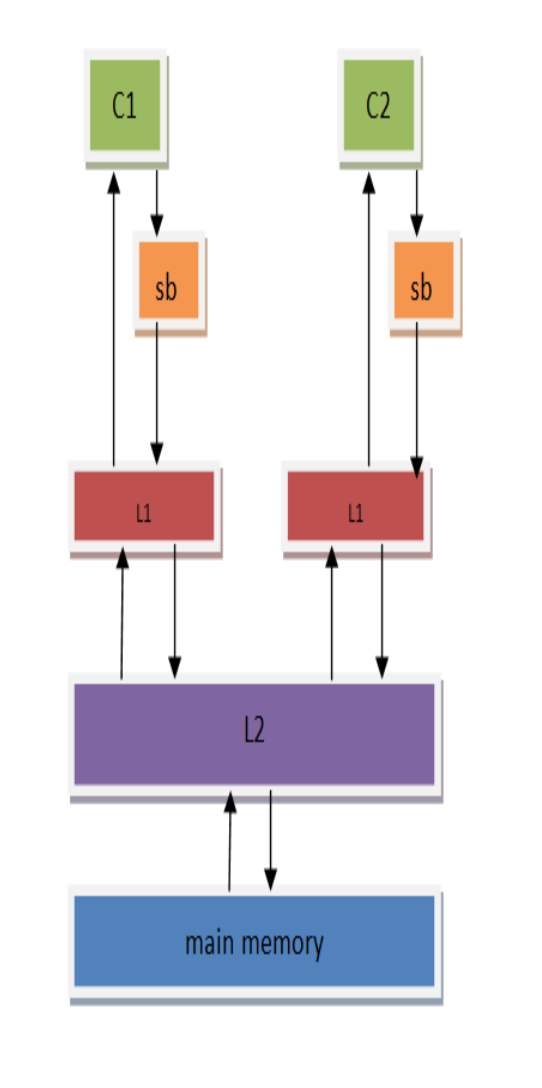
相比於以前的內存模型而言,store的時候數據會先被放到store buffer裏面,然後再被寫到L1 cache里。
core1 – S1: store flag=SET S2: load r1=data S3: store b=SET 如果按照順序存儲模型,S1肯定會比S2先執行。S1將指令放到了store buffer後會立刻返回,這個時候會立刻執行S2。S2是read指令,CPU必須等到數據讀取到r1後才會繼續執行。這樣很可能S1的
store flag=set指令還在store buffer上,而S2的load指令可能已經執行完(特別是data在cache上存在,而flag沒在cache中的時候。這個時候CPU往往會先執行S2,這樣可以減少等待時間)。這裡就可以看出再加入了store buffer之後,內存一致性模型就發生了改變。如果我們定義store buffer必須嚴格按照FIFO的次序將數據發送到主存(所謂的FIFO表示先進入store buffer的指令數據必須先於後面的指令數據寫到存儲器中),這樣S3必須要在S1之後執行,CPU能夠保證store指令的存儲順序,這種內存模型就叫做完全存儲定序(TSO)。
core1 core2 S1: store data=NEW L1: store flag=NEW S2: load r1=flag L2: load r1=data -
按照SC模型,可能發生如下順序
S1 S2 L1 L2 S1 L1 S2 L2 S1 L1 L2 S2 L1 L2 S1 S2 L1 S1 S2 L2 L1 S1 L2 S2最終我們看到的結果是至少有一個CORE的r1值為
NEW,或者都為NEW(所有store指令均先於load指令發生)。 -
按照TSO模型,由於store buffer的存在,L1和S1的store指令會被先放到store buffer裏面,然後CPU會繼續執行後面的load指令。Store buffer中的數據可能還沒有來得及往存儲器中寫,這個時候我們可能看到C1和C2的r1都為0的情況。
所以,我們可以看到,在store buffer被引入之後,內存一致性模型已經發生了變化(從SC模型變為了TSO模型),會出現store-load亂序的情況,這就造成了代碼執行邏輯與我們預先設想不相同的情況。而且隨着內存一致性模型越寬鬆(通過允許更多形式的亂序讀寫訪問),這種情況會越劇烈,會給多線程編程帶來很大的挑戰。
-
c.) 部分存儲定序 PSO(part store order)
-
芯片設計人員並不滿足TSO帶來的性能提升,於是他們在TSO模型的基礎上繼續放寬內存訪問限制,允許CPU以非FIFO來處理store buffer緩衝區中的指令。
CPU只保證地址相關指令在store buffer中才會以FIFO的形式進行處理,而其他的則可以亂序處理,所以這被稱為部分存儲定序(PSO)。core1 core2 S1: store data=NEW S2: store flag=SET L1: load r1=flag B1: if (r1≠SET) goto L1 L2: load r2=data S1與S2是地址無關的store指令,cpu執行的時候都會將其推到store buffer中。如果這個時候flag在C1的cahe中存在,那麼CPU會優先將S2的store執行完,然後等data緩存到C1的cache之後,再執行store data=NEW指令。
這個時候可能的執行順序:
S2 L1 L2 S1這樣在C1將data設置為NEW之前,C2已經執行完,r2最終的結果會為0,而不是我們期望的NEW,這樣PSO帶來的store-store亂序將會對我們的代碼邏輯造成致命影響。從這裡可以看到,store-store亂序的時候就會將我們的多線程代碼完全擊潰。所以在PSO內存模型的架構上編程的時候,要特別注意這些問題。
d.) 寬鬆存儲模型 RMO(relax memory order)
-
喪心病狂的芯片研發人員為了榨取更多的性能,在PSO的模型的基礎上進一步放寬內存模型,進一步允許load-load,load-store亂序,只要是地址無關的指令,在讀寫訪問的時候都可以打亂所有load/store的順序,這就是寬鬆內存模型(RMO)。
core1 core2 S1: store data=NEW S2: store flag=SET L1: load r1=flag B1: if (r1≠SET) goto L1 L2: load r2=data 還是上面的代碼。按照PSO模型,由於S2可能會比S1先執行,從而會導致C2的r2寄存器獲取到的data值為0。在RMO模型里,不僅會出現PSO的store-store亂序,C2本身執行指令的時候,由於L1與L2是地址無關的,所以L2可能先比L1執行,這樣即使C1沒有出現store-store亂序,C2本身的load-load亂序也會導致我們看到的r2為0。從上面的分析可以看出,RMO內存模型里亂序出現的可能性會非常大,這是一種亂序隨可見的內存一致性模型。
內存屏障 (memory barrier)
-
芯片設計者在提高性能放寬內存模型的同時,也引入了多線程情況下的軟件邏輯問題,為此芯片設計者也提供了內存屏障來應對這些問題。
到這裡,回歸到JMM中看,JMM為不同的內存一致性模型使用了相應的內存屏障。(這圖很多說java內存模型的文章都有貼上)
不同內存屏障的解讀如圖:
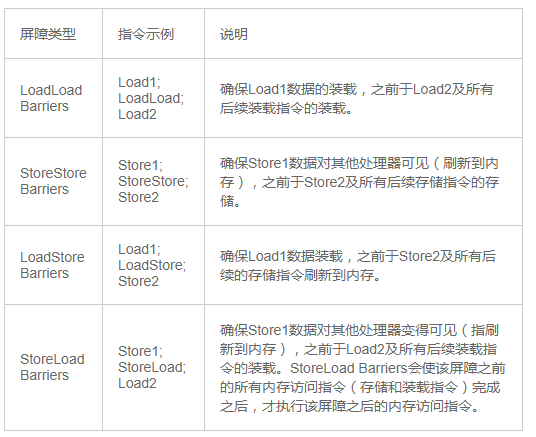
其中StoreLoad Barriers是一個「全能型」的屏障,它同時具有其他三個屏障的效果。現代的多處理器大都支持該屏障(其他類型的屏障不一定被所有處理器支持)。執行該屏障開銷會很昂貴,因為當前處理器通常要把寫緩衝區中的數據全部刷新到內存中(buffer fully flush)。
結合上面的例子,能很好掌握內存一致性模型和內存屏障哦(不管他也無所謂,畢竟JMM已經管理好了)
JMM和JSR-133
大部分關於java內存模型的規範都在JSR-133中定義了。其中就有happens-before規則。
java的專家們以經為我們準備了更簡單的happens-before規則,一經搜索,就能發現很多文章有寫,不做展開了。
happens-before概述一下就是:
第n指令 happens-before 第n+1指令 第n+1指令 happens-before 第n+2指令 同時根據傳遞性可推導出 第n指令 happens-before 第n+2指令而JMM會在happens-before規則中根據指令的變量相關性適當的安排內存屏障或不做安排(允許重排)。
總結
JMM為我們屏蔽了大量細節,我們只需要合理運用好final、volatile、synchornize關鍵字,以及正確的CAS就能很好地應對並發安全問題了(JUC包中的核心類AQS就是一個volatile修飾的state變量以及相關的cas操作寫成的)。
了解內存一直性模型可能對編寫java沒啥幫助,用好JUC就能好地寫成並發安全的代碼了,可是我很可能跑回C++哦,要學的要學的,哈哈。