高性能集群系統使用簡易記錄
集群系統通常使用SLURM作業調度腳本來提交、查看、修改作業。以下記錄它的腳本與命令的編寫與使用。
常用命令
以下是各種常用命令:
squeue #查看當前執行中的任務情況 sinfo #查看所有分區的情況 sacct #查看24小時內的歷史任務 scancel job 56200 #取消id為56200的任務 scontrol show node #顯示所有節點信息 scontrol show node node5 #顯示節點5的信息
大型作業
對於大型作業,要把任務提交到服務器排隊才能計算。所以要寫任務腳本,提交任務的命令如下:
sbatch test.job
腳本實例如下:
#!/bin/bash #SBATCH --job-name=Helloworld ##作業的名稱 #SBATCH --ntasks=1 ##總進程數,就是同樣的作業要一起跑幾個,一般煉丹一個就行了 #SBATCH --nodes=1 ##指定節點數量,一個進程只能分配給一個節點,不能分配給多節點多CPU運行 #SBATCH --ntasks-per-node=1 ##每個結點的進程數,一個進程那麼每個結點進程數一定是1,不填也沒事 #SBATCH --cpus-per-task=2 ##每個進程使用的CPU核心數,煉丹當然是越多越好,但是要的多分配的也慢 #SBATCH --partition=low ##使用哪個分區,可以sinfo看看有哪些分區 ##SBATCH --gres=gpu:1 ##指定GPU,不寫就不分配 ##SBATCH --nodelist=node56 ##使用指定的節點,自己指定的話通常優先度會高一些,缺點就是即使別的節點空閑了也不會分配給你。當然節點要在上面指定的分區內部才行 #SBATCH --output=test.out ##標準輸出的存放的文件,可以用%j表示任務ID #SBATCH --error=test.err ##錯誤提示的存放的文件 #SBATCH --qos=debug ##服務質量,debug就是交互式模式,分配資源少些,但是優先度高,另外還有normal普通模式,資源多但優先度低 source /public/home/chenqz/.bashrc ##要用的軟件的環境變量,直接把用戶的.bashrc給source了就好了 python3 test.py ##要執行的任務,看你終端所在的位置,如果已經在任務的文件夾中就不需要完整路徑了,上面的123.out和.err也一樣,都是輸出到這一位置。
交互式計算
直接進入計算節點
可以通過ssh從登陸節點訪問計算節點(可能運維沒有設置好,普通用戶也能進)。首先要訪問節點1,在節點1內才能訪問其它計算節點:
ssh comput1 #進入節點1 ssh comput55 #進入節點1後,再進入其它節點,節點55
計算節點後可以直接在命令行執行代碼,從而在計算節點運行。但是通常計算節點都是有人佔用的,所以以這種未申請的方式使用計算節點計算效率不高。
申請資源後再進入
申請資源後再以以上方式進入節點,就可以在比較好的資源下運行交互式代碼。使用salloc命令,以下是實例:
salloc -N 1 --cpus-per-task=1 -p low --qos=debug
各種參數格式如下(和上面的任務提交腳本類似,就是少了#SBATCH):
-J <任務名> #--job-name=<任務名> 的簡寫,下面一條-的都是簡寫,而且不用= -N <節點數量> #煉丹一般也就一個節點 --ntasks=<進程數> #煉丹就不需要了定義了,默認一個進程就夠了 --ntasks-per-node=<單節點進程數> #一個進程的話也不需要定義這個了 --cpus-per-task=<單進程CPU核心數> --gres=gpu:<單節點 GPU 卡數> -p <使用的分區> --qos=<使用的 QoS>
申請後的資源也是以作業的形式佔用,可以squeue查看:

看到申請的節點是58,然後進入這個節點,運行代碼:
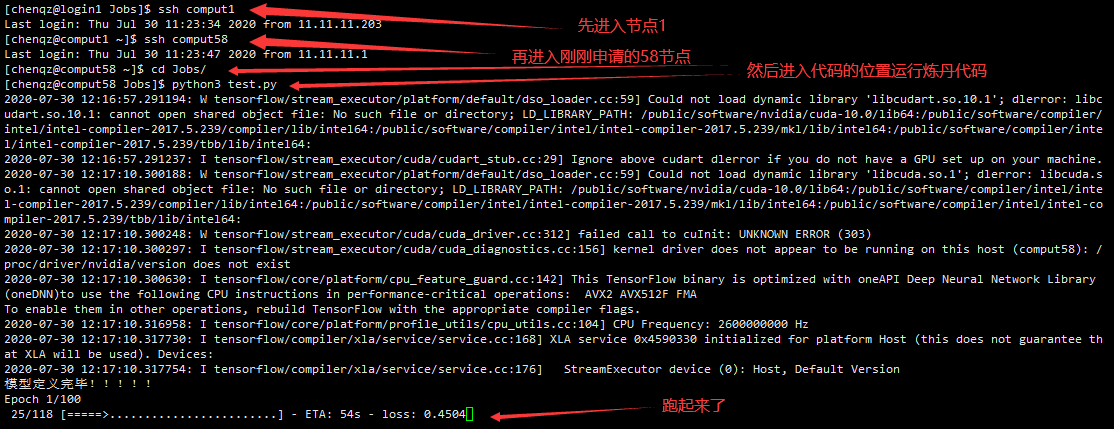
可以再開一個shell看看跑代碼時的CPU佔用:

佔用率很高666.6%,而如果不申請的話,佔用率不會超過10%。