MapReduce之WritableComparable排序
@
排序概述
- 排序是MapReduce框架中最重要的操作之一。
- Map Task和ReduceTask均會默認對數據按照key進行排序。該操作屬於Hadoop的默認行為。任何應用程序中的數據均會被排序,而不管邏輯上是否需要。
- 黑默認排序是按照字典順序排序,且實現該排序的方法是快速排序。
- 對於
MapTask,它會將處理的結果暫時放到一個緩衝區中,當緩衝區使用率達到一定閾值後,再對緩衝區中的數據進行一次排序,並將這些有序數據寫到磁盤上,而當數據處理完畢後,它會對磁盤上所有文件進行一次合併,以將這些文件合併成一個大的有序文件。 - 對於
ReduceTask,它從每個MapTak上遠程拷貝相應的數據文件,如果文件大小超過一定闌值,則放到磁盤上,否則放到內存中。如果磁盤上文件數目達到一定閾值,則進行一次合併以生成一個更大文件;如果內存中文件大小或者數目超過一定閾值,則進行一次合併後將數據寫到磁盤上。當所有數據拷貝完畢後,ReduceTask統一對內存和磁盤上的所有數據進行一次歸併排序。 - 排序器:排序器影響的是排序的速度(效率,對什麼排序?),QuickSorter
- 比較器:比較器影響的是排序的結果(按照什麼規則排序)
獲取Mapper輸出的key的比較器(源碼)
public RawComparator getOutputKeyComparator() {
// 從配置中獲取mapreduce.job.output.key.comparator.class的值,必須是RawComparator類型,如果沒有配置,默認為null
Class<? extends RawComparator> theClass = getClass(JobContext.KEY_COMPARATOR, null, RawComparator.class);
// 一旦用戶配置了此參數,實例化一個用戶自定義的比較器實例
if (theClass != null){
return ReflectionUtils.newInstance(theClass, this);
}
//用戶沒有配置,判斷Mapper輸出的key的類型是否是WritableComparable的子類,如果不是,就拋異常,如果是,系統會自動為我們提供一個key的比較器
return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class), this);
}
案例實操(區內排序)
需求
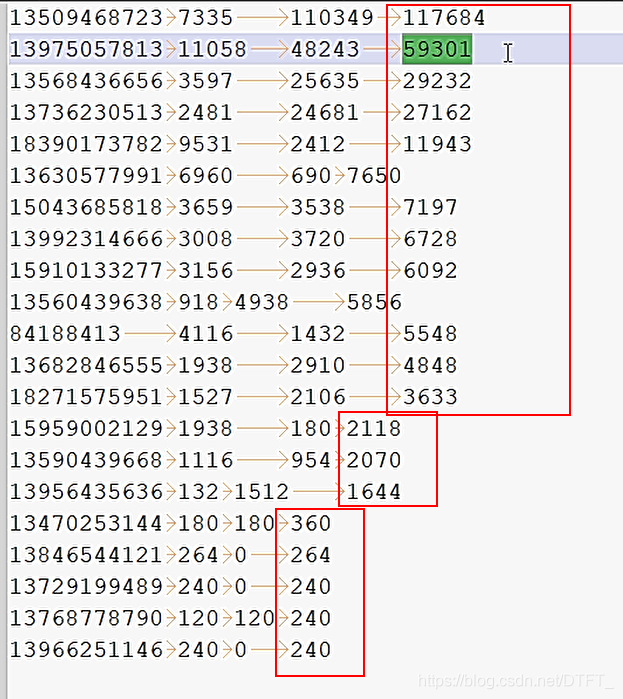
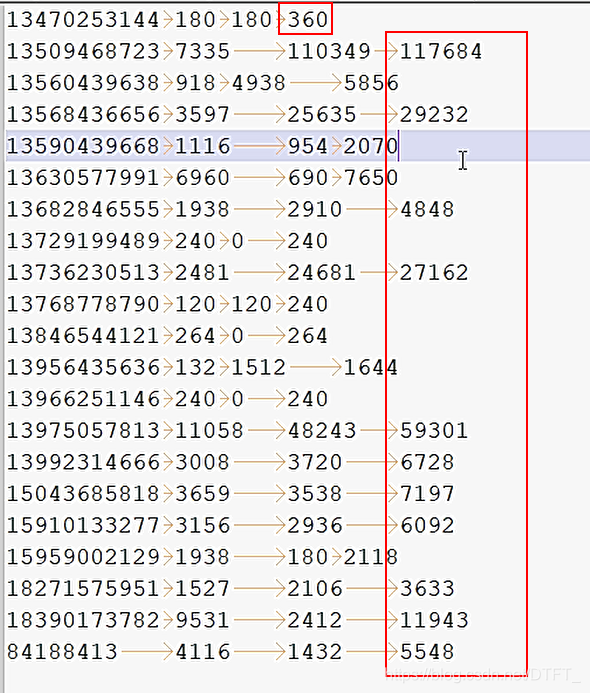
對每個手機號按照上行流量和下行流量的總和進行內部排序。
思考
因為Map Task和ReduceTask均會默認對數據按照key進行排序,所以需要把流量總和設置為Key,手機號等其他內容設置為value
FlowBeanMapper.java
public class FlowBeanMapper extends Mapper<LongWritable, Text, LongWritable, Text>{
private LongWritable out_key=new LongWritable();
private Text out_value=new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
//封裝總流量為key
out_key.set(Long.parseLong(words[3]));//切分後,流量和的下標為3
//封裝其他內容為value
out_value.set(words[0]+"\t"+words[1]+"\t"+words[2]);
context.write(out_key, out_value);
}
}
FlowBeanReducer.java
public class FlowBeanReducer extends Reducer<LongWritable, Text, Text, LongWritable>{
@Override
protected void reduce(LongWritable key, Iterable<Text> values,
Reducer<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value, key);
}
}
}
FlowBeanDriver.java
public class FlowBeanDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("E:\\mroutput\\flowbean");
Path outputPath=new Path("e:/mroutput/flowbeanSort1");
//作為整個Job的配置
Configuration conf = new Configuration();
//保證輸出目錄不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①創建Job
Job job = Job.getInstance(conf);
// ②設置Job
// 設置Job運行的Mapper,Reducer類型,Mapper,Reducer輸出的key-value類型
job.setMapperClass(FlowBeanMapper.class);
job.setReducerClass(FlowBeanReducer.class);
// Job需要根據Mapper和Reducer輸出的Key-value類型準備序列化器,通過序列化器對輸出的key-value進行序列化和反序列化
// 如果Mapper和Reducer輸出的Key-value類型一致,直接設置Job最終的輸出類型
//由於Mapper和Reducer輸出的Key-value類型不一致(maper輸出類型是long-text,而reducer是text-value)
//所以需要額外設定
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 設置輸入目錄和輸出目錄
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 默認升序排,可以設置使用自定義的比較器
//job.setSortComparatorClass(DecreasingComparator.class);
// ③運行Job
job.waitForCompletion(true);
}
}
運行結果(默認升序排)
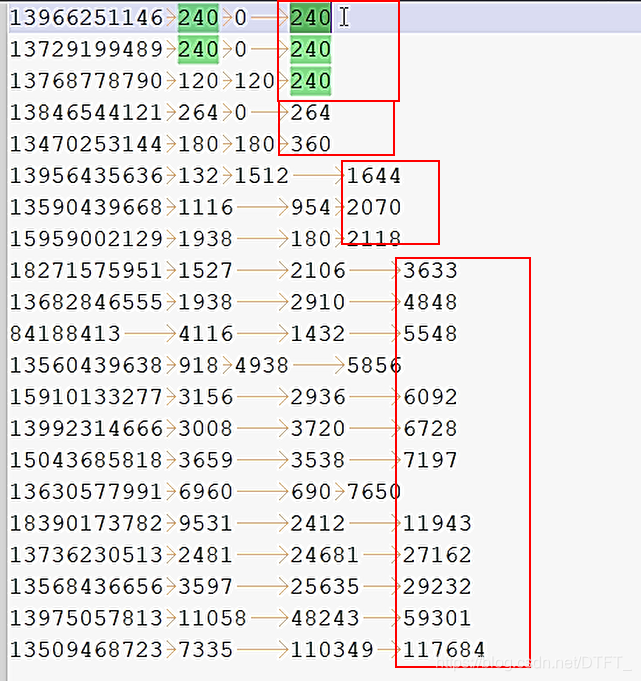
自定義排序器,使用降序
-
方法一:自定義類,這個類必須是
RawComparator類型,通過設置mapreduce.job.output.key.comparator.class自定義的類的類型。
自定義類時,可以繼承WriableComparator類,也可以實現RawCompartor
調用方法時,先調用RawCompartor. compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2),再調用RawCompartor.compare() -
方法二:定義Mapper輸出的key,讓key實現
WritableComparable,實現CompareTo()
MyDescComparator.java
public class MyDescComparator extends WritableComparator{
@Override
public int compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2) {
long thisValue = readLong(b1, s1);
long thatValue = readLong(b2, s2);
//這裡把第一個-1改成1,把第二個1改成-1,就是降序排
return (thisValue<thatValue ? 1 : (thisValue==thatValue ? 0 : -1));
}
}
運行結果