文本分類(TFIDF/樸素貝葉斯分類器/TextRNN/TextCNN/TextRCNN/FastText/HAN)
- 2019 年 10 月 18 日
- 筆記
目錄
簡介
通常,進行文本分類的主要方法有三種:
- 基於規則特徵匹配的方法(如根據喜歡,討厭等特殊詞來評判情感,但準確率低,通常作為一種輔助判斷的方法)
- 基於傳統機器學習的方法(特徵工程 + 分類算法)
- 給予深度學習的方法(詞向量 + 神經網絡)
自BERT提出以來,各大NLP比賽基本上已經被BERT霸榜了,但筆者認為掌握經典的文本分類模型原理還是十分有必要的。這一節,將對一些經典模型進行介紹,並在我的github中給出部分模型的實現。
TFIDF
TF-IDF(term frequency–inverse document frequency)是一種統計方法,用以評估一字詞對於一個文件集或一個語料庫中的其中一份文件的重要程度。TF意思是詞頻(Term Frequency),IDF意思是逆文本頻率指數(Inverse Document Frequency)。
TFIDF的主要思想是:如果某個詞或短語在一篇文章中出現的頻率TF高,並且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類。其統計公式如下:
(tfidf_{i, j} = tf_{i, j} times idf_{i, j})
其中,tf表示詞頻(Term Frequency),即詞條在文檔i中出現的頻率;idf為逆向文件頻率(Inverse Document Frequency),表示某個關鍵詞在整個語料所有文章中出現的次數的倒數(該指標用於降低常用詞的重要性)。
優點:能過濾掉一些常見的卻無關緊要的詞語,同時保留影響整個文本的重要詞語。
缺點:不能有效反應特徵詞的分佈情況,也沒有體現詞語的位置信息(通常文章首尾句詞的重要性較高)。
樸素貝葉斯分類器
樸素貝葉斯分類器是文本分類常用的機器學習方法。貝葉斯分類器的核心思想就是貝葉斯決策論:貝葉斯決策論考慮如何基於某個先驗分佈下,使得平均風險最小的決策。該理論具有兩個最兩個關鍵的部分:先驗分佈和平均風險
貝葉斯公式
文本分類問題最簡單的方法,就是通過對文本所包含的字詞特徵來對文本進行歸類。假設類別為(Y),文本特徵集合為(X),用概率統計的方法來表示,則我們需要求得條件概率(P(Y|X))。如果我們將貝葉斯決策論的思想應用到該問題中,即我們熟知的貝葉斯公式:
(P(Y|X) = frac{P(Y)P(X|Y)}{P(X)})
其中,(P(Y|X))為後驗概率;(P(X))和(P(Y))為先驗概率。
我們可以將貝葉斯公式的右端拆成(P(Y))與(frac{P(X|Y)}{P(X)})乘積的形式,則我們可以將其理解為在X的條件下Y發生的概率,等於Y發生的概率乘以一個修正因子,若修正因子大於1,表明X條件的發生使得Y發生的概率變大了,修正因子小於1,則表明X條件使得Y發生個概率降低了。由於概率因子中,(P(X))是一個確定值(可以通過統計得到),我們只需要確定條件概率(P(X|Y)),即可確定給定文本特徵的情況下該條件概率分佈,從而進行文本分類。
貝葉斯決策論的理解
假設我們的文本由N種可能的類別標記,即(Y={c_1, c_2, …, c_N}),則我們可以由後驗概率(P(c_i|x))得到將樣本(x)分類為(c_i)的條件風險(或稱期望損失):
(R(c_i|x)=sum_{j=1}^{N}lambda_{ij}P(c_j|x))
其中,(lambda_{ij})表示將(c_i)標記為(c_j)產生的損失
如果我們想要得到最優的分類,就需要使得每次標記的條件風險最小化,即最優條件風險:
(h^*(x)=argmin_{c in Y}R(c|x))
這就是貝葉斯判定準則,如果我們想使得分類錯誤率(1-正確分類率)最小,則只需令條件風險為:
(R(c|x)=1 – P(c|x))
則最優條件風險簡化為
(h^*(x)=argmin_{c in Y}R(c|x)=argmax_{c in Y}P(c|x))
我們將貝葉斯公式帶入其中,可得
(h^*(x)=argmax_{c in Y}P(c|x)=argmax_{c in Y}frac{P(c)P(x|c)}{P(x)}=argmax_{c in Y}P(c)P(x|c))
綜合以上討論,當前求最小化分類錯誤率的問題轉化成了最大化後驗概率(P(x|c))的問題。
極大似然估計
我們已經假設輸入文本特徵滿足某種條件概率分佈,接下來的關鍵是由觀測到的文本特徵對該條件概率分佈進行參數估計,即極大似然估計。
極大似然估計源自於頻率學派,他們認為參數雖然未知,但卻是客觀存在的規定值,因此,可以通過優化似然函數等準則確定參數數值。
假設(D_c)表示訓練集中c類標籤的樣本集合,假設這些樣本是獨立同分佈的。求解極大似然估計主要由如下幾個步驟:
- 由訓練集的特徵集合以及事先假設的概率分佈函數,寫出似然函數
(P(D_c|theta)=prod_{x in D_c}P(x|theta))
- 由於很多小概率的乘積會導致浮點數下溢出,我們對其求對數,將原來的乘積運算變為求和運算
(L(theta)=logP(D_c|theta)=sum_{x in D_c}logP(x|theta))
- 當(L(hat theta))取得極大值時,(theta)的極大似然估計為(hat theta),即
(hat theta = argmax_{theta}L(theta))
樸素貝葉斯分類器
從上一節可知,我們可以用極大似然的方法來估計我們需要的概率分佈參數,接下來的關鍵就是我們如何從訓練樣本中準確估計出條件概率P(x|c)。我們知道文本之間的相互關係是十分複雜的,但為了簡化模型複雜度從而更簡單的估計出條件概率,樸素貝葉斯分類器做了「屬性條件獨立性假設」:對已知類別,假設所有屬性相互獨立,即假設每個屬性獨立的對分類結果發生影響,即
(P(x|c)=prod_{i=1}^{d}P(x_i|c))
有了條件概率的簡化條件之後,我們很容易將貝葉斯準則改寫為
(h^*(x)=argmax_{c in Y}P(c|x)=argmax_{c in Y}P(c)prod_{i=1}^{d}P(x_i|c))
上式即樸素貝葉斯的表達式。
接下來,我們從訓練集中統計得到似然估計,令(D_c)表示訓練集D中第c類樣本組成的集合,先驗概率(P(c))的似然估計為:
(P(c)=frac{|D_c|}{|D|})
對於條件概率(P(x|c)),通常,我們假設該條件概率滿足某種概率分佈,在sklearn中有三種假設的分佈:GuassianNB、MultinomialNB和BernoulliNB(分別假設為高斯分佈、多項分佈和伯努利分佈,文本分類通常使用多項式分佈),假設滿足多項式分佈,則條件概率為如下形式:
(P(X=x_{jl}|Y=c_k) = frac{x_{jl}+lambda}{m_k+nlambda})
其中,(m_k)是訓練集中輸出為第k類的樣本個數,(lambda)取1時即拉普拉斯平滑,目的是防止0概率估計的出現,而影響後驗概率的計算結果。
總的來說,樸素貝葉斯分類的推導主要基於貝葉斯公式,決策方式為在「屬性條件獨立性假設」條件下的貝葉斯決策論,參數估計的方法為極大似然估計。
TextRNN
之前介紹過詞向量以及三大特徵提取器,這裡就不再贅述了,深度學習模型無非就是用特徵抽取器拼接起來的不同結構的神經網絡模型,所以接下來的幾個部分基本是對模型結構的簡介。
首先我們來看看用經典的LSTM/GRU實現文本分類模型的基本結構:
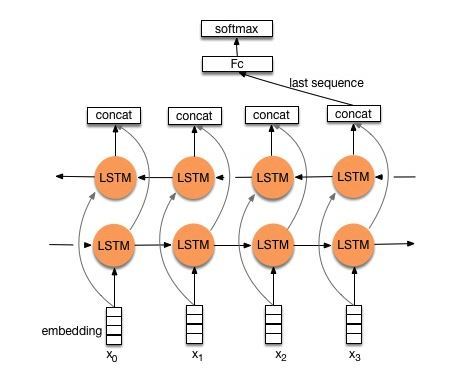
由上圖可知,TextRNN僅僅是將Word Embedding輸入到雙向LSTM中,然後對最後一位的輸出輸入到全連接層中,在對其進行softmax分類即可。
TextCNN
對於TextCNN在上一篇文章中簡單的提到過,這裡再做一些簡單的補充,其模型結構如下圖所示:
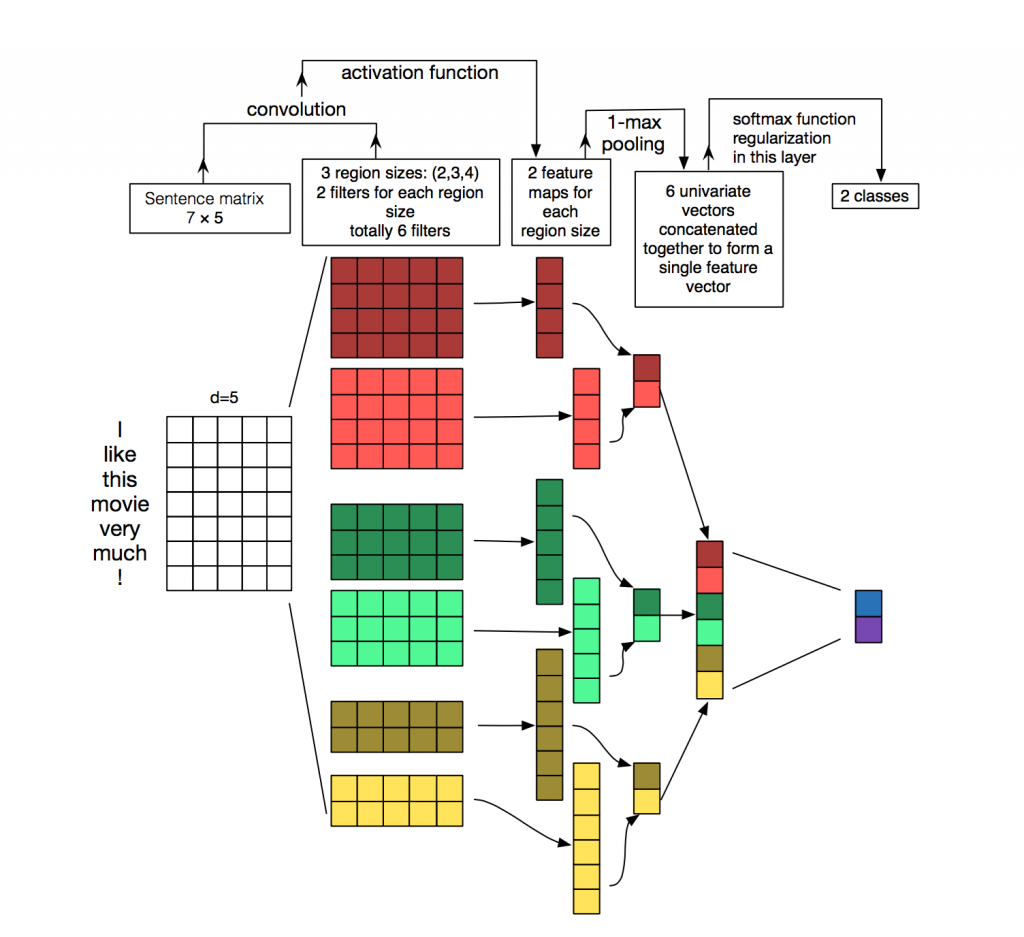
上圖很直觀的展現了,與圖像中的二維卷積不同,TextCNN中採用的是一維卷積,每個卷積核的大小為(h times k)(h為卷積核的窗口大小,k為詞向量的維度),文中採用了多種不同尺寸的卷積核,用以提取不同文本長度的特徵(上圖種可以看見,卷積核有h=2, 3, 4三種)
然後,作者對於卷積核的輸出進行MaxPooling,目的是提取最重要的特徵。將所有卷積核的輸出通過MaxPooling之後拼接形成一個新向量,再將該向量輸出到全連接層分類器(Dropout + Linear + Softmax)實現文本分類。
TextRCNN
這篇論文中描述稍微複雜了點,實際模型非常簡單,該模型結構如下圖所示:
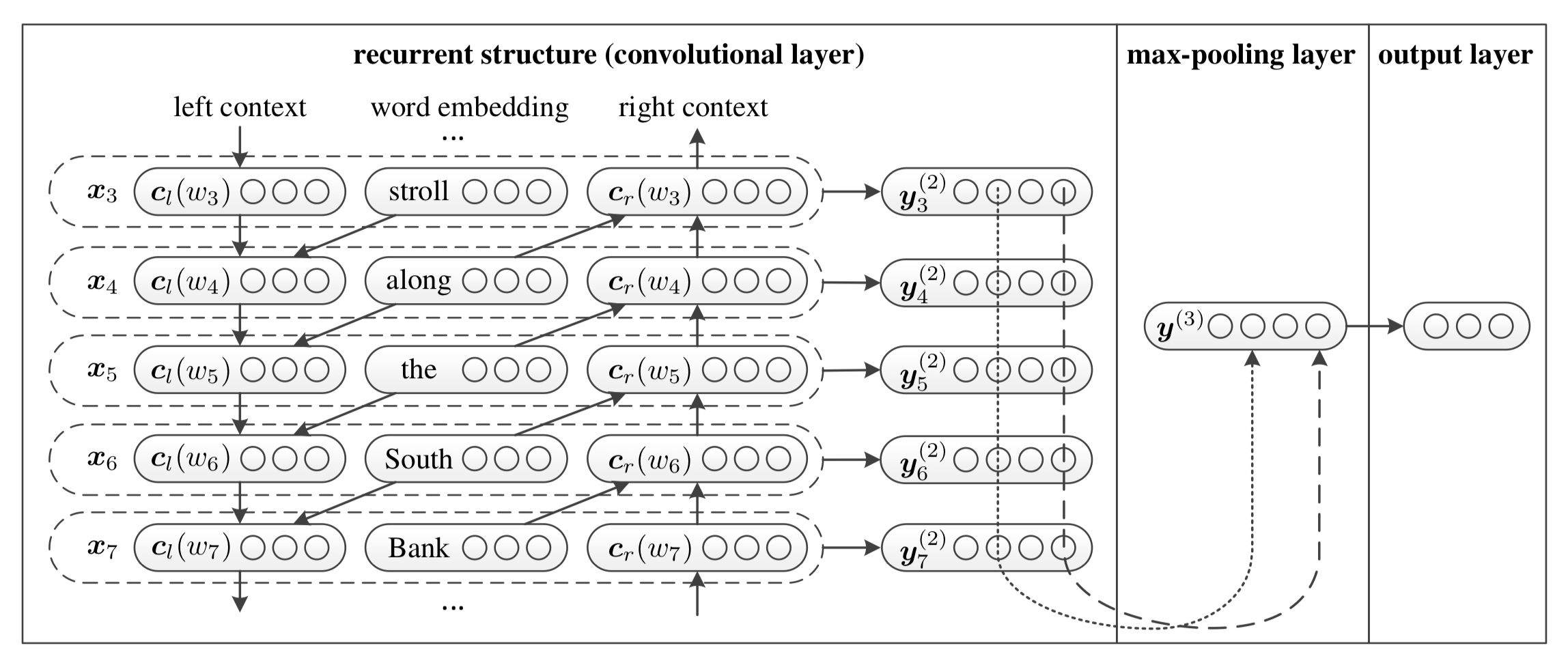
該模型的主要思想如下:
- 首先獲得詞向量表示(e(w_i))
- 其次將詞向量通過雙向RNN(實踐中可以是LSTM或GRU)得到(c_l(w_i))和(c_r(w_i))
- 將(c_l(w_i)), (e(w_i))以及(c_r(w_i))拼接得到新的向量,將其輸入到全連接網絡對其進行整合,激活函數為tanh
- 再將全連接網絡的輸出進行MaxPooling
- 最後將其輸入一個全連接分類器中實現分類
FastText
FastText是Facebook於2016年發佈的文本分類模型,其主要思想基於word2vec中的skip-gram模型(關於skip-gram模型參考我之前詞向量的博客,這裡也就不再贅述),在訓練文本分類模型的同時,也將訓練出字符級n-gram詞向量。
通常認為,形態類似的單詞具有相似的語義特徵。而對於Word2Vec模型,其構建的語料庫中,把不同的單詞直接映射到獨立的id信息,這樣,使得不同單詞之間的形態學信息完全丟失了,如英文中的「nation」和「national」,中文中的「上海市政府」和「上海市」。如果能夠學習到形態學變換到單詞特徵的規則,我們可以利用這個規則來得到許多訓練集中不可見的單詞表示。
為了解決這個問題,FastText用字符級別的n-gram來表示一個單詞或句子,如
中華人民共和國
bigram:中華 華人 人民 民共 共和 和國
trigram:中華人 華人民 人民共 民共和 共和國
得到了詞的n-gram表徵之後,我們可以用n-gram子詞(subword)的詞向量疊加來表示整個詞語,詞典則是所有詞子詞的並集。
其主要模型結構如下圖所示,最後也採用了層次softmax的提速手段:
對比skip-gram模型,可以FastText的詞典規模會更大,模型參數會更多。但每一個詞的詞向量都是子詞向量的和,使得一些生僻詞或未出現的單詞能夠從形態相近的單詞中得到較好的詞向量表示,從而在一定程度上能夠解決OOV問題
HAN
HAN的全稱為Hierarchical Attention Network(分級注意網絡),從字面意思就可以理解其是一個分層架構模型。該模型主要用於文檔分類(長文本分類),其主要結構如下所示:
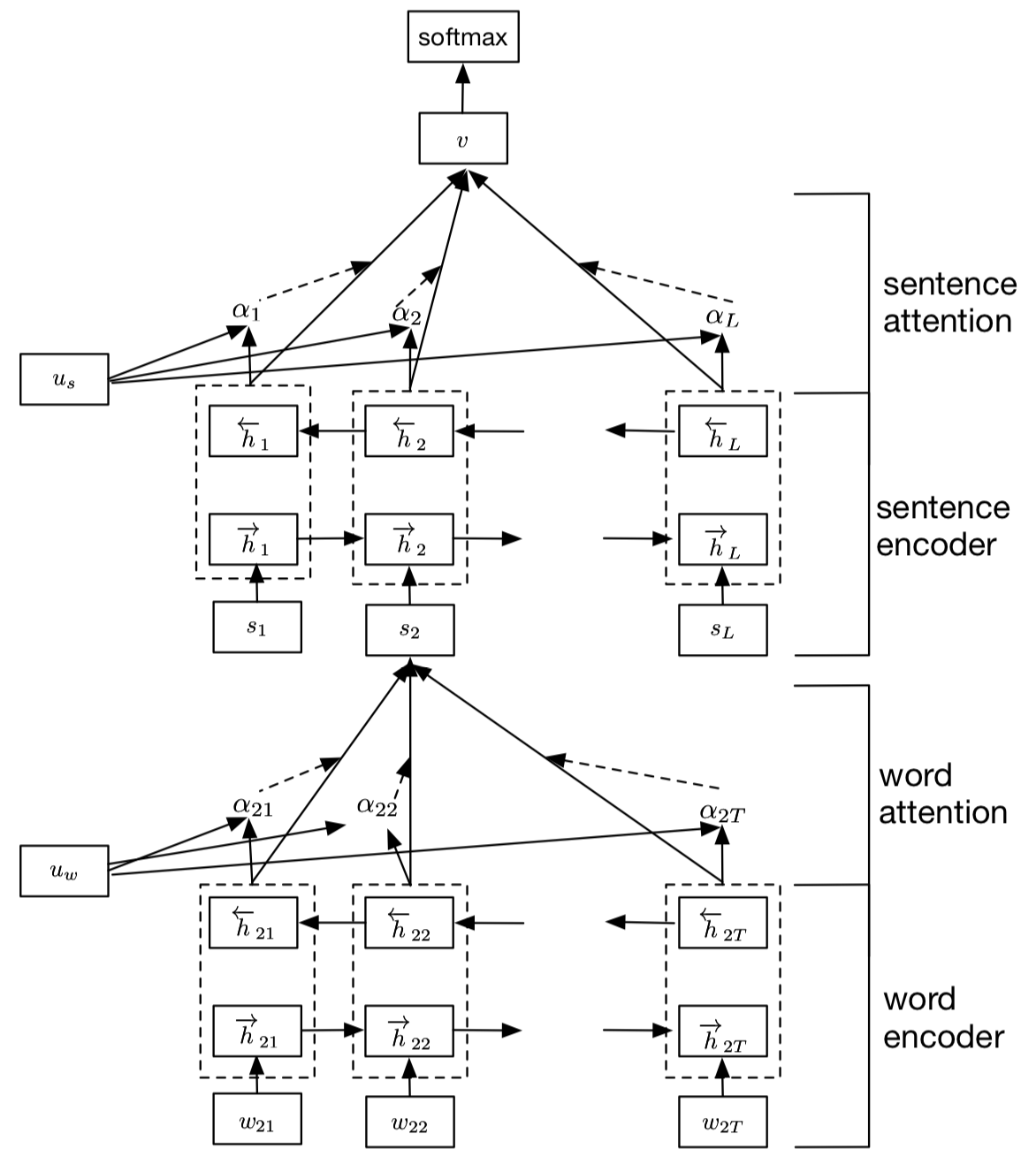
HAN主要由兩個層次的模型架構:詞級別和句級別,每個層次的模型都包括一個編碼器和注意力模型兩個部分,整個模型的細節如下:
- 如上圖所示,假設我們的文檔中有(L)個句子,對於第二個句子,單詞長度為(T)
- 首先將單詞輸入Embedding層獲取詞向量
- 將獲取的詞向量輸入詞編碼器,即一個雙向GRU,將兩個方向的GRU輸出拼接在一起得到詞級別的隱向量(h)
- 將詞級別的隱向量通過一個單層感知機(MLP,實際上就是全連接神經網絡,激活函數選用tanh),輸出的結果可以看作是更高層次的隱向量表示:
(u_{it}=tanh(W_wu_{it}+b_w)) - 隨機初始化一個上下文向量(u_w)(隨着訓練不斷優化),將該上下文向量(u_w)與高層次的隱向量表示(u_{it})輸入softmax,得到每個詞與上下文向量的相似度表示:
(alpha_{it}=frac{exp(u_{it}^Tu_w)}{sum_texp(u_{it}^Tu_w)}) - 將上述相似度作為權重,對(h_{it})加權求和得到句子級別的向量表示:
(s_i=sum_talpha_{it}h_{it}) - 對於句子級別的向量,我們用相類似的方法,將其通過編碼層,注意力層,最後將文檔中所有句子的隱向量表示加權求和,得到整個文檔的文檔向量(v),將該向量通過一個全連接分類器進行分類。
其實HAN中使用到的的Attention就是最常用的 Soft-Attention ,整個模型的結構就相當於TextRNN + Soft-Attention的疊加。,分別用來處理詞級別和句子級別,對於短文本分類,我們只需借鑒詞級別的模型即可。
Highway Networks
門限神經網絡(Gated Networks),在之前一篇文章中也提到過,主要是利用(sigmoid)函數「門限」的性質,來實現對信息流的自動控制的一種方法,Highway Networks就是一種典型的門限網絡結構,這裡也簡單的介紹一下。
根據原文的定義,假設原來網絡的輸出為:
[y = H(x, W_H)]
其中(H(·))表示非線性變換(可以設置為激活函數為relu的全連接層)。定義(T(x, W_T) = sigmoid(W_T^Tx + b_T))文章的做法就是將其改進為:
[y = H(x, W_H) cdot T(x, W_T) + x cdot (1-T(x, W_T))]
則對於輸出y,有:
[y = begin{cases} x, & if T(x, W_T) = 0 \ H(x, W_H), & if T(x, W_T) = 1 end{cases}]
https://blog.csdn.net/zhangph1229/article/details/52106301
https://www.kesci.com/home/project/5be7e948954d6e0010632ef2
https://zhuanlan.zhihu.com/p/32091937
https://zhuanlan.zhihu.com/p/64603089
https://zhuanlan.zhihu.com/p/24780258
https://zhuanlan.zhihu.com/p/32965521
https://zhuanlan.zhihu.com/p/63111928
https://zhuanlan.zhihu.com/p/53342715
https://zhuanlan.zhihu.com/p/44776747


