支持向量機SMO算法實現(注釋詳細)
一:SVM算法
(一)見西瓜書及筆記
(二)統計學習方法及筆記
(三)推文//zhuanlan.zhihu.com/p/34924821
(四)推文
支持向量機原理(一) 線性支持向量機
支持向量機原理(二) 線性支持向量機的軟間隔最大化模型
二:SMO算法
(一)見西瓜書及筆記
(二)統計學習方法及筆記
(三)見機器學習實戰及筆記
(四)推文
支持向量機原理(四)SMO算法原理
三:代碼實現(一)SMO中的輔助函數
(一)加載數據集
import numpy as np import matplotlib.pyplot as plt #一:SMO算法中的輔助函數 #加載數據集 def loadDataSet(filename): dataSet = np.loadtxt(filename) m,n = dataSet.shape data_X = dataSet[:,0:n-1] data_Y = dataSet[:,n-1] return data_X,data_Y
(二)隨機選取一個J值,作為α_2的下標索引
#隨機選取一個數J,為後面內循環選取α_2做輔助(如果α選取不滿足條件,就選擇這個方法隨機選取) def selectJrand(i,m): #主要就是根據α_1的索引i,從所有數據集索引中隨機選取一個作為α_2的索引 j = i while j==i: j = np.int(np.random.uniform(0,m)) #從0~m中隨機選取一個數,是進行整數化的 print("random choose index for α_2:%d"%(j)) return j #由於這裡返回隨機數,所以後面結果 可能導致不同
(三)根據關於α_1與α_2的優化問題對應的約束問題分析,對α進行截取約束

def clipAlpha(aj,H,L): #根據我們的SVM算法中的約束條件的分析,我們對獲取的aj,進行了截取操作 if aj > H: aj = H if aj < L: aj = L return aj
四:代碼實現(二)SMO中的支持函數
(一)定義一個數據結構,用於保存所有的重要值
#首先我們定義一個數據結構(類),來保存所有的重要值 class optStruct: def __init__(self,data_X,data_Y,C,toler): #輸入參數分別是數據集、類別標籤、常數C用於軟間隔、和容錯率toler self.X = data_X self.label = data_Y self.C = C self.toler = toler #就是軟間隔中的ε,調節最大間隔大小 self.m = data_X.shape[0] self.alphas = np.zeros(self.m) #存放每個樣本點的α值 self.b = 0 #存放閾值 self.eCache = np.zeros((self.m,2)) #用於緩存誤差,每個樣本點對應一個Ei值,第一列為標識符,標誌是否為有效值,第二列存放有效值
(二)計算每個樣本點k的Ek值,就是計算誤差值=預測值-標籤值
#計算每個樣本點k的Ek值,就是計算誤差值=預測值-標籤值 def calcEk(oS,k): # 根據西瓜書6.24,我們可以知道預測值如何使用α值進行求解 fxk = np.multiply(oS.alphas,oS.label).T@([email protected][k,:])+oS.b #np.multiply之後還是(m,1),([email protected][k,:])之後是(m,1),通過轉置(1,m)@(m,1)-->實數後+b即可得到預測值fx #獲取誤差值Ek Ek = fxk - oS.label[k] return Ek
(三)重點:內循環的啟發式方法,獲取最大差值|Ei-Ej|對應的Ej的索引J
#內循環的啟發式方法,獲取最大差值|Ei-Ej|對應的Ej的索引J def selectJ(i,oS,Ei): #注意我們要傳入第一個α對應的索引i和誤差值Ei,後面會用到 maxK = -1 #用於保存臨時最大索引 maxDeltaE = 0 #用於保存臨時最大差值--->|Ei-Ej| Ej = 0 #保存我們需要的Ej誤差值 #重點:這裡我們是把SMO最後一步(根據最新閾值b,來更新Ei)提到第一步來進行了,所以這一步是非常重要的 oS.eCache[i] = [1,Ei] #開始獲取各個Ek值,比較|Ei-Ej|獲取Ej的所有 #獲取所有有效的Ek值對應的索引 validECacheList = np.where(oS.eCache[:,0]!=0)[0] #根據誤差緩存中第一列非0,獲取對應的有效誤差值 if len(validECacheList) > 1: #如果有效誤差緩存長度大於1(因為包括Ei),則正常進行獲取j值,否則使用selectJradn方法選取一個隨機J值 for k in validECacheList: if k == i: #相同則不處理 continue #開始計算Ek值,進行對比,獲取最大差值 Ek = calcEk(oS,k) deltaE = abs(Ei - Ek) if deltaE > maxDeltaE: #更新Ej及其索引位置 maxK = k maxDeltaE = deltaE Ej = Ek return maxK,Ej #返回我們找到的第二個變量α_2的位置 else: #沒有有效誤差緩存,則隨機選取一個索引,進行返回 j = selectJrand(i,oS.m) Ej = calcEk(oS,j) return j,Ej
(四)實現更新Ek操作
#實現更新Ek操作,因為除了最後我們需要更新Ei之外,我們在內循環中計算α_1與α_2時還是需要用到E1與E2, #因為每次的E1與E2由於上一次循環中更新了α值,所以這一次也是需要更新E1與E2值,所以單獨實現一個更新Ek值的方法還是有必要的 def updateEk(oS,k): Ek = calcEk(oS,k) oS.eCache[k] = [1,Ek] #第一列1,表示為有效標識
五:代碼實現(三)SMO中的內循環函數
外循環是要找違背KKT條件最嚴重的樣本點(每個樣本點對應一個α),這裡我們將外循環的該判別條件放入內循環中考慮。
(一)補充違背KKT條件選取
對於SVM中的KKT條件如下:

一般來說,我們首先選擇違反0<αi<C⇒yig(xi)=1這個條件的點。
如果這些支持向量都滿足KKT條件,再選擇違反αi=0⇒yig(xi)≥1和 αi=C⇒yig(xi)≤1的點。
(二)分析0<αi<C⇒yig(xi)=1條件
對於上面違反KKT條件實際應用時的兩種情況(或狀態):
1. 0<αi⇒yig(xi)>1違背KKT條件
之所以不考慮α<c的情況,因為當yig(xi)>1時,必然出現α≠c,又因為0<α<c,所以我們只用考慮0<α⇒yig(xi)>1即可。
2. αi <C⇒yig(xi)<1違背KKT條件
之所以不考慮α>0的情況,因為當yig(xi)<1時,必然出現α≠0,又因為0<α<c,所以我們只用考慮α<C⇒yig(xi)<1即可。
(三)軟間隔分析(同上)
相比較於硬間隔狀態,多了一個鬆弛變量,所以我們考慮的時候加上該鬆弛變量即可。
1. 0<αi⇒yig(xi)>1+ξ違背KKT條件
2. αi <C⇒yig(xi)<1-ξ違背KKT條件
(四)代碼分析
if ((oS.label[i]*Ei < -oS.toler) and (oS.alphas[i] < oS.C)) or\ ((oS.label[i]*Ei > oS.toler) and (oS.alphas[i] > 0)): #注意:對於硬間隔,我們直接和1對比,對於軟間隔,我們要和1 +或- ε對比
這裡的代碼和我們上面分析的違背KKT條件有所不同,所以下面進行推導:
主要看Ei的公式:Ei=g(xi)-yi
如(二)(三)分析可以知道,我們將進入優化的條件(即違背KKT條件)寫成代碼中形式:
(yiEi<-toler且α<C)或(yiEi>toler且α>C)
條件中yiEi=yi(g(xi)-yi)=yig(xi)-yi2
由於yi=±1,所以yi2=1
最後,我們就可以將代碼中的原條件化簡為:
(yig(xi)<1-toler且α<C)或(yig(xi)>1+toler且α>C)
即我們在(三)中的形式
(六)分析內循環中η值的性質
#計算η值=k_11+k_22-2k_12 eta = oS.X[i]@oS.X[i] + oS.X[j]@oS.X[j] - 2.0*oS.X[i]@oS.X[j] #eta性質可以知道是>=0的,所以我們只需要判斷是否為0即可 if eta <= 0: print("eta <= 0") return 0
由下述η化簡可以知道:
![]()
η的取值範圍必然是η>=0。
又因為我們在推導SVM算法中知道:
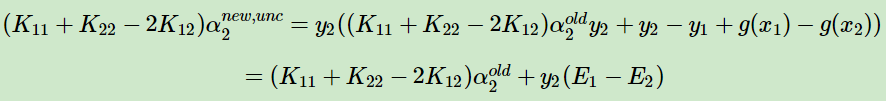
當η=0時,我們要求解的α無法更新,所以,我們只需要η>0即可。
所以,代碼中判斷η<=0時,不符合條件,退出即可。
(五)代碼實現
#三:實現內循環函數,相比於外循環,這裡包含了主要的更新操作 def innerL(i,oS): #由外循環提供i值(具體選取要違背kkT<這裡實現>,使用交替遍歷<外循環中實現>)---提供α_1的索引 Ei = calcEk(oS,i) #計算E1值,主要是為了下面KKT條件需要使用到 #如果下面違背了KKT條件,則正常進行α、Ek、b的更新,重點:後面單獨說明下面是否滿足違反KKT條件 if ((oS.label[i]*Ei < -oS.toler) and (oS.alphas[i] < oS.C)) or\ ((oS.label[i]*Ei > oS.toler) and (oS.alphas[i] > 0)): #注意:對於硬間隔,我們直接和1對比,對於軟間隔,我們要和1 +或- ε對比 #開始在內循環中,選取差值最大的α_2下標索引 j,Ej = selectJ(i,oS,Ei) #因為後面要修改α_1與α_2的值,但是後面修改閾值b的時候需要用到新舊兩個值,所以我們需要在更新α值之前進行保存舊值 alphaIold = oS.alphas[i].copy() alphaJold = oS.alphas[j].copy() #分析約束條件(是對所有α都適用),一會對我們新的α_2進行截取糾正,注意:α_1是由α_2推出的,所以不需要進行驗證了。 #如果y_1!=y_2異號時: if oS.label[i] != oS.label[j]: L = max(0,alphaJold-alphaIold) H = min(oS.C,oS.C+alphaJold-alphaIold) else: #如果y_1==y_2同號時 L = max(0,alphaJold+alphaIold-oS.C) H = min(oS.C,alphaJold+alphaIold) #上面就是將α_j調整到L,H之間 if L==H: #如果L==H,之間返回0,跳出這次循環,不進行改變(單值選擇,沒必要) return 0 #計算η值=k_11+k_22-2k_12 eta = oS.X[i]@oS.X[i] + oS.X[j]@oS.X[j] - 2.0*oS.X[i]@oS.X[j] #eta性質可以知道是>=0的,所以我們只需要判斷是否為0即可 if eta <= 0: print("eta <= 0") return 0 #當上面所有條件都滿足以後,我們開始正式修改α_2值,並更新對應的Ek值 oS.alphas[j] += oS.label[j]*(Ei-Ej)/eta oS.alphas[j] = clipAlpha(oS.alphas[j],H,L) updateEk(oS,j) #查看α_2是否有足夠的變化量,如果沒有足夠變化量,我們直接返回,不進行下面更新α_1,注意:因為α_2變化量較小,所以我們沒有必要非得把值變回原來的舊值 if abs(oS.alphas[j] - alphaJold) < 0.00001: print("J not move enough") return 0 #開始更新α_1值,和Ek值 oS.alphas[i] += oS.label[i]*oS.label[j]*(alphaJold-oS.alphas[j]) updateEk(oS,i) #開始更新閾值b,正好使用到了上面更新的Ek值 b1 = oS.b - Ei - oS.label[i] * (oS.alphas[i] - alphaIold) * oS.X[i] @ oS.X[i] - oS.label[j] * ( oS.alphas[j] - alphaJold) * oS.X[i] @ oS.X[j] b2 = oS.b - Ej - oS.label[i] * (oS.alphas[i] - alphaIold) * oS.X[i] @ oS.X[j] - oS.label[j] * ( oS.alphas[j] - alphaJold) * oS.X[j] @ oS.X[j] #根據統計學習方法中閾值b在每一步中都會進行更新, #1.當新值alpha_1不在界上時(0<alpha_1<C),b_new的計算規則為:b_new=b1 #2.當新值alpha_2不在界上時(0 < alpha_2 < C),b_new的計算規則為:b_new = b2 #3.否則當alpha_1和alpha_2都不在界上時,b_new = 1/2(b1+b2) if oS.alphas[i] > 0 and oS.alphas[i] < oS.C: oS.b = b1 elif oS.alphas[j] > 0 and oS.alphas[j] < oS.C: oS.b = b2 else: oS.b = 1/2*(b1+b2) #注意:這裡我們應該根據b_new更新一次Ei,但是我們這裡沒有寫,因為我們將這一步提前到了最開始,即selectJ中 #以上全部更新完畢,開始返回標識 return 1 return 0 #沒有違背KKT條件
六:代碼實現(四)SMO中的外循環函數
(一)交替遍歷
交替遍歷一種方式是在所有的數據集上進行單遍掃描,另一種是在非邊界上(不在邊界0或C上的值)進行單遍掃描
交替遍歷:
交替是通過一個外循環來選擇第一個alpha值的,並且其選擇過程會在兩種方式之間交替:
一種方式是在所有數據集上進行單遍掃描,
另一種方式則是在非邊界alpha中實現單遍掃描,所謂非邊界alpha指的是那些不等於邊界0或C的alpha值。
對整個數據集的掃描相當容易,
而實現非邊界alpha值的掃描時,首先需要建立這些alpha值的列表,然後對這個表進行遍歷。
同時,該步驟會跳過那些已知不變的alpha值。
(二)代碼實現
#四:開始外循環,由於我們在內循環中實現了KKT條件的判斷,所以這裡我們只需要進行交替遍歷即可 #交替遍歷一種方式是在所有的數據集上進行單遍掃描,另一種是在非邊界上(不在邊界0或C上的值)進行單遍掃描 # 交替遍歷: # 交替是通過一個外循環來選擇第一個alpha值的,並且其選擇過程會在兩種方式之間交替: # 一種方式是在所有數據集上進行單遍掃描, # 另一種方式則是在非邊界alpha中實現單遍掃描,所謂非邊界alpha指的是那些不等於邊界0或C的alpha值。 # 對整個數據集的掃描相當容易, # 而實現非邊界alpha值的掃描時,首先需要建立這些alpha值的列表,然後對這個表進行遍歷。 # 同時,該步驟會跳過那些已知不變的alpha值。 def smoP(data_X,data_Y,C,toler,maxIter): oS = optStruct(data_X,data_Y,C,toler) iter = 0 entireSet = True #標誌是否應該遍歷整個數據集 alphaPairsChanged = 0 #標誌一次循環中α更新的次數 #開始進行迭代 #當iter >= maxIter或者((alphaPairsChanged == 0) and not entireSet)退出循環 #前半個判斷條件很好理解,後面的判斷條件中,表示上一次循環中,是在整個數據集中遍歷,並且沒有α值更新過,則退出 while iter < maxIter and ((alphaPairsChanged > 0) or entireSet): alphaPairsChanged = 0 if entireSet: #entireSet是true,則在整個數據集上進行遍歷 for i in range(oS.m): alphaPairsChanged += innerL(i,oS) #調用內循環 print("full dataset, iter: %d i:%d,pairs changed:%d"%(iter,i,alphaPairsChanged)) iter += 1 #無論是否更新過,我們都計算迭代一次 else: #遍歷非邊界值 nonBounds = np.where((oS.alphas>0) & (oS.alphas<C))[0] #獲取非邊界值中的索引 for i in nonBounds: #開始遍歷 alphaPairsChanged += innerL(i,oS) print("non bound, iter: %d i:%d,pairs changed:%d"%(iter,i,alphaPairsChanged)) iter += 1 #無論是否更新過,我們都計算迭代一次 #下面實現交替遍歷 if entireSet: entireSet = False elif alphaPairsChanged == 0: #如果是在非邊界上,並且α更新過。則entireSet還是False,下一次還是在非邊界上進行遍歷。可以認為這裡是傾向於非邊界遍歷,因為非邊界遍歷的樣本更符合內循環中的違反KKT條件 entireSet = True print("iteration number: %d"%iter) return oS.b,oS.alphas
七:根據α實現求解權重W值
(一)公式
根據西瓜書中6.37:
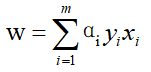
求解權重向量
(二)代碼實現
def calcWs(alphas,data_X,data_Y): #根據西瓜書6.37求W m,n = data_X.shape w = np.zeros(n) for i in range(m): w += alphas[i]*data_Y[i]*data_X[i].T return w
八:測試SMO算法的實現
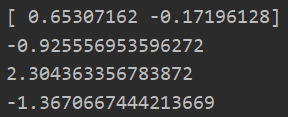
data_X,data_Y = loadDataSet("testSet.txt") C = 0.6 toler = 0.001 maxIter = 40 b,alphas = smoP(data_X,data_Y,C,toler,maxIter) ws = calcWs(alphas,data_X,data_Y) #含有隨機操作,所以有多種可能性結果 print(ws) test = data_X[0]@ws+b print(test) test = data_X[2]@ws+b print(test) test = data_X[1]@ws+b print(test)
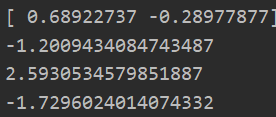
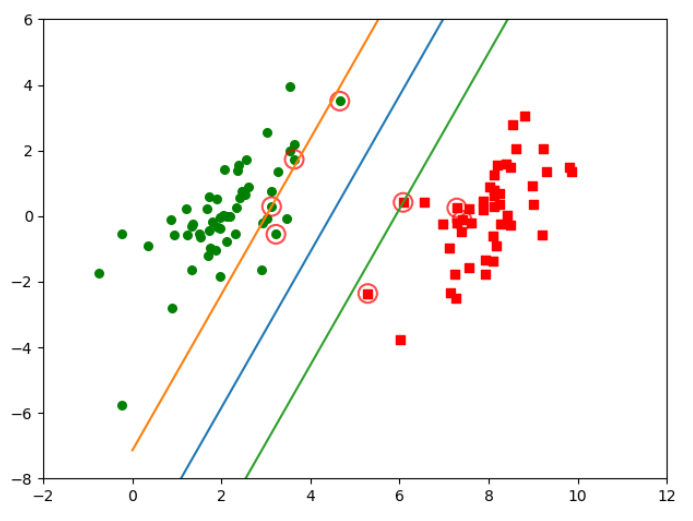
九:繪製圖像和支持向量
(一)代碼實現
#繪製圖像 def plotFigure(weights, b,toler,data_X,data_Y): m,n = data_X.shape # 進行數據集分類操作 cls_1x = data_X[np.where(data_Y==1)] cls_1y = data_Y[np.where(data_Y==1)] cls_2x = data_X[np.where(data_Y!=1)] cls_2y = data_Y[np.where(data_Y!=1)] plt.scatter(cls_1x[:,0].flatten(), cls_1x[:,1].flatten(), s=30, c='r', marker='s') plt.scatter(cls_2x[:,0].flatten(), cls_2x[:,1].flatten(), s=30, c='g') # 畫出 SVM 分類直線 xx = np.arange(0, 10, 0.1) # 由分類直線 weights[0] * xx + weights[1] * yy1 + b = 0 易得下式 yy1 = (-weights[0] * xx - b) / weights[1] # 由分類直線 weights[0] * xx + weights[1] * yy2 + b + 1 = 0 易得下式 yy2 = (-weights[0] * xx - b - 1 - toler) / weights[1] # 由分類直線 weights[0] * xx + weights[1] * yy3 + b - 1 = 0 易得下式 yy3 = (-weights[0] * xx - b + 1 + toler) / weights[1] plt.plot(xx, yy1.T) plt.plot(xx, yy2.T) plt.plot(xx, yy3.T) # 畫出支持向量點 for i in range(m): if alphas[i] > 0.0: plt.scatter(data_X[i, 0], data_X[i, 1], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red') plt.xlim((-2, 12)) plt.ylim((-8, 6)) plt.show() plotFigure(ws,b,toler,data_X,data_Y)
(二)圖像顯示