Java並發容器
- 2020 年 7 月 22 日
- 筆記
- ConcurrentHashMap, CopyOnWriteArrayList
HashMap常見的不安全問題及原因
-
非原子操作
++ modCount 等非原子操作存在且沒有任何加鎖機制會導致線程不安全問題;
-
擴容取值
擴容期間會創建新的table在數據轉儲期間,可能會有取到null的可能;
-
碰撞丟失
-
可見性問題
HashMap中沒有可見性volatile關鍵字修飾,多線程情況下不能保證可見性;
-
死循環
JDK1.7 擴容期間,頭插法也可能導致出現循環鏈表,即NodeA.next = NodeB ; NodeB.next = NodeA 在取值時則會發生死循環;
ConcurrentHashMap在JDK1.8中的升級
Java 7 版本的 ConcurrentHashMap
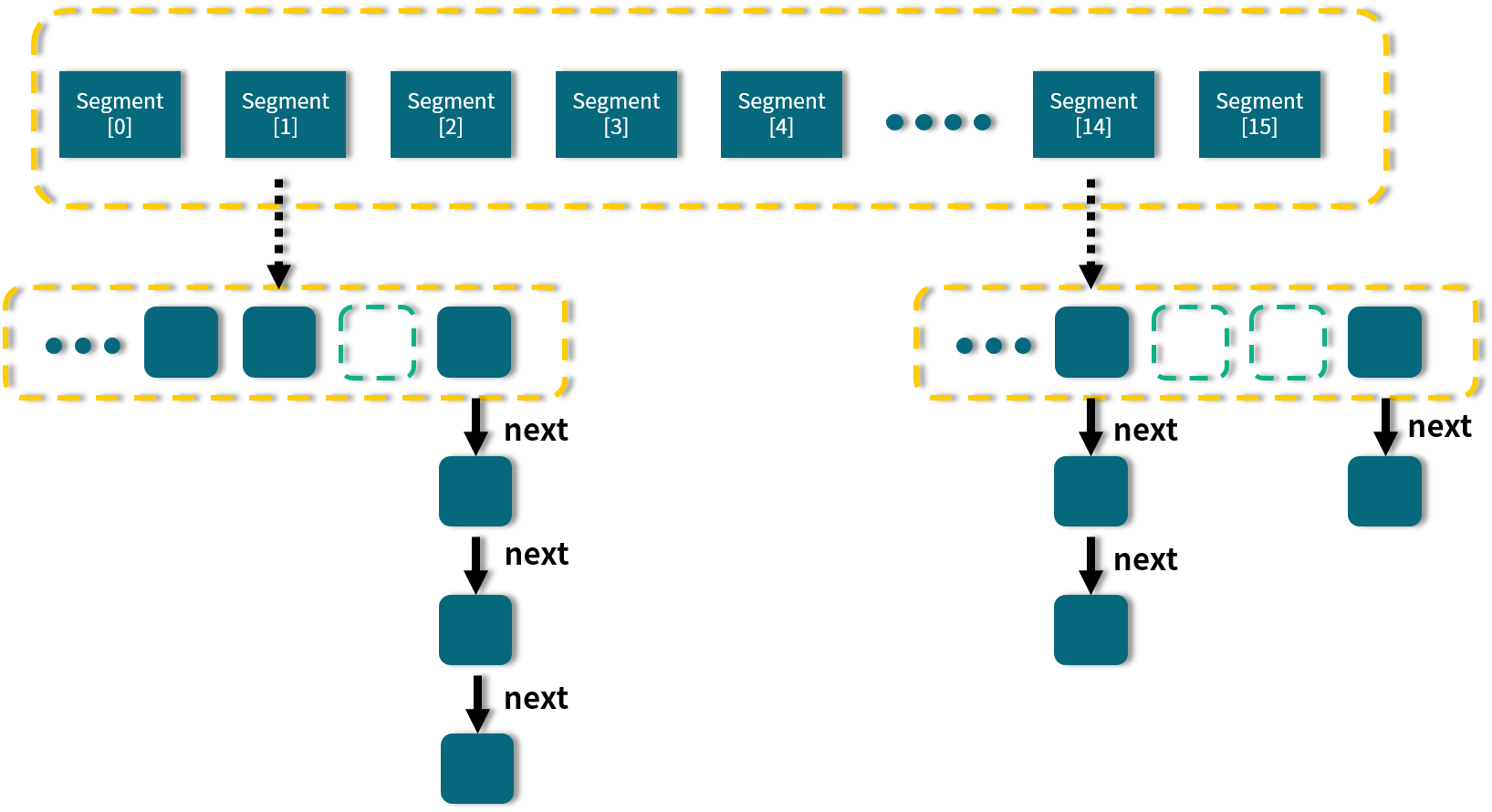
從圖中我們可以看出,在 ConcurrentHashMap 內部進行了 Segment 分段,Segment 繼承了 ReentrantLock,可以理解為一把鎖,各個 Segment 之間都是相互獨立上鎖的,互不影響分段鎖。相比於之前的 Hashtable 每次操作都需要把整個對象鎖住而言,大大提高了並發效率。因為它的鎖與鎖之間是獨立的,而不是整個對象只有一把鎖。
每個 Segment 的底層數據結構與 HashMap 類似的HashEntry(所以1.7中的put操作需要進行兩次Hash,先找到Segment再找到HashEntry,並使用 tryLock + 自旋的方式嘗試插入數據),仍然是數組和鏈表組成的拉鏈法結構。默認有 0~15 共 16 個 Segment,所以最多可以同時支持 16 個線程並發操作(操作分別分佈在不同的 Segment 上)。16 這個默認值可以在初始化的時候設置為其他值,但是一旦確認初始化以後,是不可以擴容的。
獲取Map的size時,依次執行兩種方案,嘗試不加鎖獲取兩次,若不變則說明size準確;否則執行方案二 加鎖情況下直接獲取size;
Java 8 版本的 ConcurrentHashMap
在 Java 8 中,幾乎完全重寫了 ConcurrentHashMap,代碼量從原來 Java 7 中的 1000 多行,變成了現在的 6000 多行,取消了Segment,使用 Node [] + 鏈表 + 紅黑樹,放棄了ReentrantLock的使用採用了`Synchronized + CAS + volatile(Node 的 value屬性) 鎖機制能適應更高的並發和更高效的鎖機制,也依賴於Java團隊對Synchronized鎖的優化。
獲取Map的size時,sumCount函數在每次操作時已經記錄好了,所以直接返回;但既然是高並發容器,size並沒有多大意義,瞬時值;
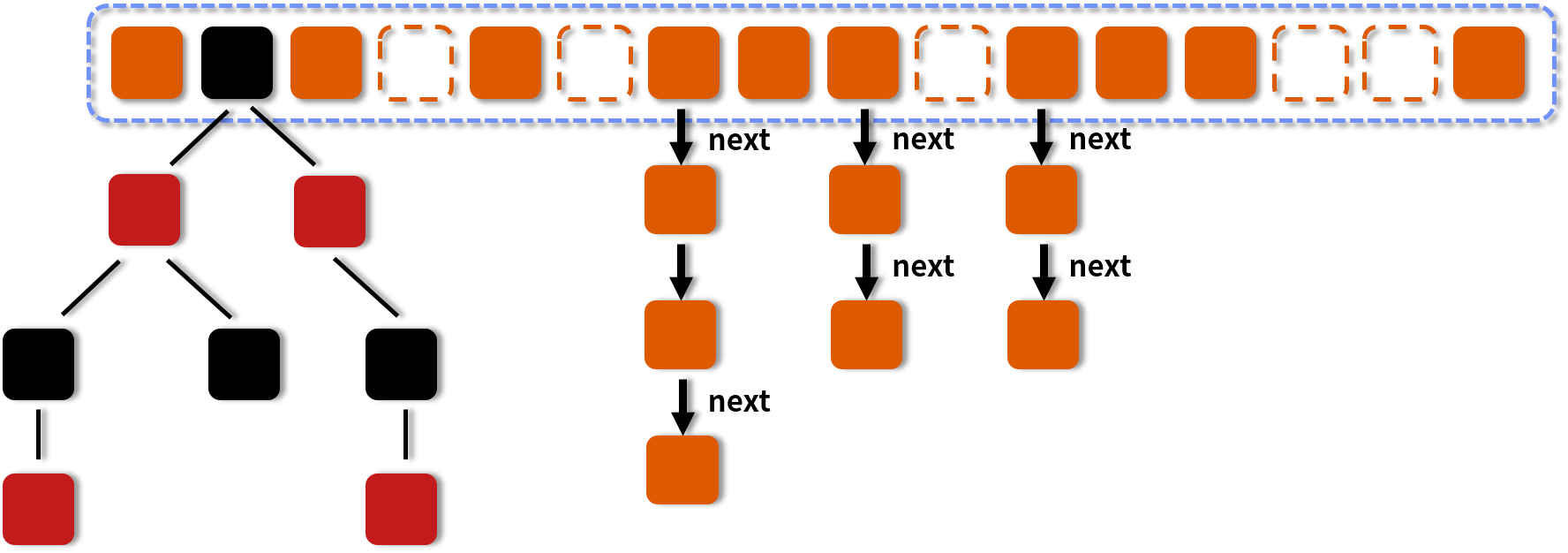
圖中的節點有三種類型。
第一種是最簡單的,空着的位置代表當前還沒有元素來填充。 第二種就是和 HashMap 非常類似的拉鏈法結構,在每一個槽中會首先填入第一個節點,但是後續如果計算出相同的 Hash 值,就用鏈表的形式往後進行延伸。 第三種結構就是紅黑樹結構,這是 Java 7 的 ConcurrentHashMap 中所沒有的結構,在此之前我們可能也很少接觸這樣的數據結構。 當第二種情況的鏈表長度大於某一個閾值(默認為 8),且同時滿足一定的容量要求的時候,ConcurrentHashMap 便會把這個鏈表從鏈表的形式轉化為紅黑樹的形式,目的是進一步提高它的查找性能。所以,Java 8 的一個重要變化就是引入了紅黑樹的設計,由於紅黑樹並不是一種常見的數據結構,所以我們在此簡要介紹一下紅黑樹的特點。
紅黑樹是每個節點都帶有顏色屬性的自平衡的二叉查找樹,顏色為紅色或黑色,紅黑樹的本質是對二叉查找樹 BST 的一種平衡策略,我們可以理解為是一種平衡二叉查找樹,查找效率高,會自動平衡,防止極端不平衡從而影響查找效率的情況發生。
由於自平衡的特點,即左右子樹高度幾乎一致,所以其查找性能近似於二分查找,時間複雜度是 O(log(n)) 級別;反觀鏈表,它的時間複雜度就不一樣了,如果發生了最壞的情況,可能需要遍歷整個鏈表才能找到目標元素,時間複雜度為 O(n),遠遠大於紅黑樹的 O(log(n)),尤其是在節點越來越多的情況下,O(log(n)) 體現出的優勢會更加明顯。
紅黑樹的一些其他特點:
-
每個節點要麼是紅色,要麼是黑色,但根節點永遠是黑色的。
-
紅色節點不能連續,也就是說,紅色節點的子和父都不能是紅色的。
-
從任一節點到其每個葉子節點的路徑都包含相同數量的黑色節點。
正是由於這些規則和要求的限制,紅黑樹保證了較高的查找效率,所以現在就可以理解為什麼 Java 8 的 ConcurrentHashMap 要引入紅黑樹了。好處就是避免在極端的情況下衝突鏈表變得很長,在查詢的時候,效率會非常慢。而紅黑樹具有自平衡的特點,所以,即便是極端情況下,也可以保證查詢效率在 O(log(n))。
事實上,鏈表長度超過 8 就轉為紅黑樹的設計,更多的是為了防止用戶自己實現了不好的哈希算法時導致鏈表過長,從而導致查詢效率低,而此時轉為紅黑樹更多的是一種保底策略,用來保證極端情況下查詢的效率。
通常如果 hash 算法正常的話,那麼鏈表的長度也不會很長,那麼紅黑樹也不會帶來明顯的查詢時間上的優勢,反而會增加空間負擔。所以通常情況下,並沒有必要轉為紅黑樹,所以就選擇了概率非常小,小於千萬分之一概率,也就是長度為 8 的概率,把長度 8 作為轉化的默認閾值。
所以如果平時開發中發現 HashMap 或是 ConcurrentHashMap 內部出現了紅黑樹的結構,這個時候往往就說明我們的哈希算法出了問題,需要留意是不是我們實現了效果不好的 hashCode 方法,並對此進行改進,以便減少衝突。
源碼分析
-
putVal方法,關鍵詞:CAS、helpTransfer、synchronized、addCount
1 final V putVal(K key, V value, boolean onlyIfAbsent) { 2 if (key == null || value == null) { 3 throw new NullPointerException(); 4 } 5 //計算 hash 值 6 int hash = spread(key.hashCode()); 7 int binCount = 0; 8 for (Node<K, V>[] tab = table; ; ) { 9 Node<K, V> f; 10 int n, i, fh; 11 //如果數組是空的,就進行初始化 12 if (tab == null || (n = tab.length) == 0) { 13 tab = initTable(); 14 } 15 // 找該 hash 值對應的數組下標 16 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { 17 //如果該位置是空的,就用 CAS 的方式放入新值 18 if (casTabAt(tab, i, null, 19 new Node<K, V>(hash, key, value, null))) { 20 break; 21 } 22 } 23 //hash值等於 MOVED 代表在擴容 24 else if ((fh = f.hash) == MOVED) { 25 tab = helpTransfer(tab, f); 26 } 27 //槽點上是有值的情況 28 else { 29 V oldVal = null; 30 //用 synchronized 鎖住當前槽點,保證並發安全 31 synchronized (f) { 32 if (tabAt(tab, i) == f) { 33 //如果是鏈表的形式 34 if (fh >= 0) { 35 binCount = 1; 36 //遍歷鏈表 37 for (Node<K, V> e = f; ; ++binCount) { 38 K ek; 39 //如果發現該 key 已存在,就判斷是否需要進行覆蓋,然後返回 40 if (e.hash == hash && 41 ((ek = e.key) == key || 42 (ek != null && key.equals(ek)))) { 43 oldVal = e.val; 44 if (!onlyIfAbsent) { 45 e.val = value; 46 } 47 break; 48 } 49 Node<K, V> pred = e; 50 //到了鏈表的尾部也沒有發現該 key,說明之前不存在,就把新值添加到鏈表的最後 51 if ((e = e.next) == null) { 52 pred.next = new Node<K, V>(hash, key, 53 value, null); 54 break; 55 } 56 } 57 } 58 //如果是紅黑樹的形式 59 else if (f instanceof TreeBin) { 60 Node<K, V> p; 61 binCount = 2; 62 //調用 putTreeVal 方法往紅黑樹里增加數據 63 if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key, 64 value)) != null) { 65 oldVal = p.val; 66 if (!onlyIfAbsent) { 67 p.val = value; 68 } 69 } 70 } 71 } 72 } 73 if (binCount != 0) { 74 //檢查是否滿足條件並把鏈錶轉換為紅黑樹的形式,默認的 TREEIFY_THRESHOLD 閾值是 8 75 if (binCount >= TREEIFY_THRESHOLD) { 76 treeifyBin(tab, i); 77 } 78 //putVal 的返回是添加前的舊值,所以返回 oldVal 79 if (oldVal != null) { 80 return oldVal; 81 } 82 break; 83 } 84 } 85 } 86 addCount(1L, binCount); 87 return null; 88 }
putVal方法中會逐步根據當前槽點是未初始化、空、擴容、鏈表、紅黑樹等不同情況做出不同的處理。當第一次put 會對數組進行初始化,bucket為空則CAS操作賦值,不為空則判斷是鏈表還是紅黑樹進行賦值操作,若此時數組正在擴容則調用helpTransfer進行多線程並發擴容操作,最後返回oldValue 並對操作調用addCount記錄(size相關);
-
getVal源碼分析
1 public V get(Object key) { 2 Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; 3 //計算 hash 值 4 int h = spread(key.hashCode()); 5 //如果整個數組是空的,或者當前槽點的數據是空的,說明 key 對應的 value 不存在,直接返回 null 6 if ((tab = table) != null && (n = tab.length) > 0 && 7 (e = tabAt(tab, (n - 1) & h)) != null) { 8 //判斷頭結點是否就是我們需要的節點,如果是則直接返回 9 if ((eh = e.hash) == h) { 10 if ((ek = e.key) == key || (ek != null && key.equals(ek))) 11 return e.val; 12 } 13 //如果頭結點 hash 值小於 0,說明是紅黑樹或者正在擴容,就用對應的 find 方法來查找 14 else if (eh < 0) 15 return (p = e.find(h, key)) != null ? p.val : null; 16 //遍歷鏈表來查找 17 while ((e = e.next) != null) { 18 if (e.hash == h && 19 ((ek = e.key) == key || (ek != null && key.equals(ek)))) 20 return e.val; 21 } 22 } 23 return null; 24 }
get過程:
-
計算 Hash 值,並由此值找到對應的bucket;
-
如果數組是空的或者該位置為 null,那麼直接返回 null 就可以了;
-
如果該位置處的節點剛好就是我們需要的,直接返回該節點的值;
-
如果該位置節點是紅黑樹或者正在擴容,就用 find 方法繼續查找;
-
否則那就是鏈表,就進行遍歷鏈表查找。
總結
-
數據結構:Java 7 採用 Segment 分段鎖來實現,而 Java 8 中的 ConcurrentHashMap 使用數組 + 鏈表 + 紅黑樹
-
並發度:Java 7 中,每個 Segment 獨立加鎖,最大並發個數就是 Segment 的個數,默認是 16。但是到了 Java 8 中,鎖粒度更細,理想情況下 table 數組元素的個數(也就是數組長度)就是其支持並發的最大個數,並發度比之前有提高。
-
並發原理:Java 7 採用 Segment 分段鎖來保證安全,而 Segment 是繼承自 ReentrantLock。
Java 8 中放棄了 Segment 的設計,採用 Node + CAS + synchronized 保證線程安全。
-
Hash碰撞:Java 7 在 Hash 衝突時,會使用拉鏈法,也就是鏈表的形式。
Java 8 先使用拉鏈法,在鏈表長度超過一定閾值時,將鏈錶轉換為紅黑樹,來提高查找效率。
CopyOnWriteArrayList / Set
其實在 CopyOnWriteArrayList 出現之前,我們已經有了 ArrayList 和 LinkedList 作為 List 的數組和鏈表的實現,而且也有了線程安全的 Vector 和 Collections.synchronizedList() 可以使用。
Vector和HashTable類似僅僅是對方法增加synchronized 上對象鎖,並發效率比較低;並且,前面這幾種 List 在迭代期間不允許編輯,如果在迭代期間進行添加或刪除元素等操作,則會拋出 ConcurrentModificationException 異常,這樣的特點也在很多情況下給使用者帶來了麻煩。所以從 JDK1.5 開始,Java 並發包里提供了使用 CopyOnWrite 機制實現的並發容器 CopyOnWriteArrayList 作為主要的並發 List,CopyOnWrite 的並發集合還包括 CopyOnWriteArraySet,其底層正是利用 CopyOnWriteArrayList 實現的。所以今天我們以 CopyOnWriteArrayList 為突破口,來看一下 CopyOnWrite 容器的特點。
適用場景
-
讀快寫慢
在很多應用場景中,讀操作可能會遠遠多於寫操作。比如,有些系統級別的信息,往往只需要加載或者修改很少的次數,但是會被系統內所有模塊頻繁的訪問。對於這種場景,我們最希望看到的就是讀操作可以儘可能的快,而寫即使慢一些也沒關係。
-
讀多寫少
黑名單是最典型的場景,假如我們有一個搜索網站,用戶在這個網站的搜索框中,輸入關鍵字搜索內容,但是某些關鍵字不允許被搜索。這些不能被搜索的關鍵字會被放在一個黑名單中,黑名單並不需要實時更新,可能每天晚上更新一次就可以了。當用戶搜索時,會檢查當前關鍵字在不在黑名單中,如果在,則提示不能搜索。這種讀多寫少的場景也很適合使用 CopyOnWrite 集合。
讀寫規則
-
讀寫鎖的規則
讀寫鎖的思想是:讀讀共享、其他都互斥(寫寫互斥、讀寫互斥、寫讀互斥),原因是由於讀操作不會修改原有的數據,因此並發讀並不會有安全問題;而寫操作是危險的,所以當寫操作發生時,不允許有讀操作加入,也不允許第二個寫線程加入。
-
對讀寫鎖規則的升級
CopyOnWriteArrayList 的思想比讀寫鎖的思想又更進一步。為了將讀取的性能發揮到極致,CopyOnWriteArrayList 讀取是完全不用加鎖的,更厲害的是,寫入也不會阻塞讀取操作,也就是說你可以在寫入的同時進行讀取,只有寫入和寫入之間需要進行同步,也就是不允許多個寫入同時發生,但是在寫入發生時允許讀取同時發生。這樣一來,讀操作的性能就會大幅度提升。
特點
-
CopyOnWrite的含義
從 CopyOnWriteArrayList 的名字就能看出它是滿足 CopyOnWrite 的 ArrayList,CopyOnWrite 的意思是說,當容器需要被修改的時候,不直接修改當前容器,而是先將當前容器進行 Copy,複製出一個新的容器 (和MySQL中的快照讀機制類似),然後修改新的容器,完成修改之後,再將原容器的引用指向新的容器。這樣就完成了整個修改過程。
這樣做的好處是,CopyOnWriteArrayList 利用了「數組不變性」原理,因為容器每次修改都是創建新副本,所以對於舊容器來說,其實是不可變的,也是線程安全的,無需進一步的同步操作。我們可以對 CopyOnWrite 容器進行並發的讀,而不需要加鎖,因為當前容器不會添加任何元素,也不會有修改。
CopyOnWriteArrayList 的所有修改操作(add,set等)都是通過創建底層數組的新副本來實現的,所以 CopyOnWrite 容器也是一種讀寫分離的思想體現,讀和寫使用不同的容器。
-
迭代期間允許修改集合內容
我們知道 ArrayList 在迭代期間如果修改集合的內容,會拋出 ConcurrentModificationException 異常。讓我們來分析一下 ArrayList 會拋出異常的原因。
在 ArrayList 源碼里的 ListItr 的 next 方法中有一個 checkForComodification 方法,代碼如下:
1 final void checkForComodification() { 2 if (modCount != expectedModCount) 3 throw new ConcurrentModificationException(); 4 }
這裡會首先檢查 modCount 是否等於 expectedModCount。modCount 是保存修改次數,每次我們調用 add、remove 或 trimToSize 等方法時它會增加,expectedModCount 是迭代器的變量,當我們創建迭代器時會初始化並記錄當時的 modCount。後面迭代期間如果發現 modCount 和 expectedModCount 不一致,就說明有人修改了集合的內容,就會拋出異常。而CopyOnWriteArrayList不會拋異常,參見源碼分析COWIterator;
缺點
這些缺點不僅是針對 CopyOnWriteArrayList,其實同樣也適用於其他的 CopyOnWrite 容器:
-
內存佔用問題
因為 CopyOnWrite 的寫時複製機制,所以在進行寫操作的時候,內存里會同時駐紮兩個對象的內存,這一點會佔用額外的內存空間。
-
在元素較多或者複雜的情況下,複製的開銷很大
複製過程不僅會佔用雙倍內存,還需要消耗 CPU 等資源,會降低整體性能。
-
臟讀問題
由於 CopyOnWrite 容器的修改是先修改副本,所以這次修改對於其他線程來說,並不是實時能看到的,只有在修改完之後才能體現出來。如果你希望寫入的的數據馬上能被其他線程看到,CopyOnWrite 容器是不適用的。
源碼分析
-
數據結構
1 /** 可重入鎖對象 */ 2 final transient ReentrantLock lock = new ReentrantLock(); 3 4 /** CopyOnWriteArrayList底層由數組實現,volatile修飾,保證數組的可見性 */ 5 private transient volatile Object[] array; 6 7 /** 8 * 得到數組 9 */ 10 final Object[] getArray() { 11 return array; 12 } 13 14 /** 15 * 設置數組 16 */ 17 final void setArray(Object[] a) { 18 array = a; 19 } 20 21 /** 22 * 初始化CopyOnWriteArrayList相當於初始化數組 23 */ 24 public CopyOnWriteArrayList() { 25 setArray(new Object[0]); 26 }
在這個類中首先會有一個 ReentrantLock 鎖,用來保證修改操作的線程安全。下面被命名為 array 的 Object[] 數組是被 volatile 修飾的,可以保證數組的可見性,這正是存儲元素的數組,同樣,我們可以從 getArray()、setArray 以及它的構造方法看出,CopyOnWriteArrayList 的底層正是利用數組實現的,這也符合它的名字。
-
add方法
1 public boolean add(E e) { 2 3 // 加鎖 4 final ReentrantLock lock = this.lock; 5 lock.lock(); 6 try { 7 8 // 得到原數組的長度和元素 9 Object[] elements = getArray(); 10 int len = elements.length; 11 12 // 複製出一個新數組 13 Object[] newElements = Arrays.copyOf(elements, len + 1); 14 15 // 添加時,將新元素添加到新數組中 16 newElements[len] = e; 17 18 // 將volatile Object[] array 的指向替換成新數組 19 setArray(newElements); 20 return true; 21 } finally { 22 lock.unlock(); 23 } 24 }
上面的步驟實現了 CopyOnWrite 的思想:寫操作是在原來容器的拷貝上進行的,並且在讀取數據的時候不會鎖住 list。而且可以看到,如果對容器拷貝操作的過程中有新的讀線程進來,那麼讀到的還是舊的數據,因為在那個時候對象的引用還沒有被更改。
-
get方法
1 public E get(int index) { 2 return get(getArray(), index); 3 } 4 final Object[] getArray() { 5 return array; 6 } 7 private E get(Object[] a, int index) { 8 return (E) a[index]; 9 }
get方法十分普通,沒有任何鎖相關內容,主要是保證讀取效率;
-
迭代器 COWIterator 類
這個迭代器有兩個重要的屬性,分別是 Object[] snapshot 和 int cursor。其中 snapshot 代表數組的快照,也就是創建迭代器那個時刻的數組情況,而 cursor 則是迭代器的游標。迭代器的構造方法如下:
1 private COWIterator(Object[] elements, int initialCursor) { 2 cursor = initialCursor; 3 snapshot = elements; 4 }
可以看出,迭代器在被構建的時候,會把當時的 elements 賦值給 snapshot,而之後的迭代器所有的操作都基於 snapshot 數組進行的,比如:
1 public E next() { 2 if (! hasNext()) 3 throw new NoSuchElementException(); 4 return (E) snapshot[cursor++]; 5 }
在 next 方法中可以看到,返回的內容是 snapshot 對象,所以,後續就算原數組被修改,這個 snapshot 既不會感知到,也不會影響執行;
下期預告:BlockingQueue


