【JVM之內存與垃圾回收篇】執行引擎
執行引擎
執行引擎概述
執行引擎屬於 JVM 的下層,裏面包括 解釋器、及時編譯器、垃圾回收器
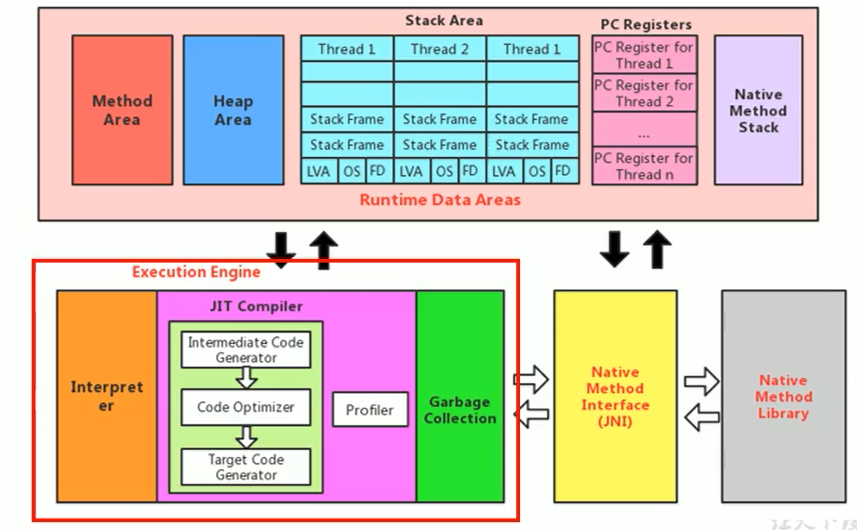
執行引擎是 Java 虛擬機核心的組成部分之一。
「虛擬機」是一個相對於「物理機」的概念,這兩種機器都有代碼執行能力,其區別是物理機的執行引擎是直接建立在處理器、緩存、指令集和操作系統層面上的,而虛擬機的執行引擎則是由軟件自行實現的,因此可以不受物理條件制約地定製指令集與執行引擎的結構體系,能夠執行那些不被硬件直接支持的指令集格式。
JVM 的主要任務是負責裝載位元組碼到其內部,但位元組碼並不能夠直接運行在操作系統之上,因為位元組碼指令並非等價於本地機器指令,它內部包含的僅僅只是一些能夠被 JVM 所識別的位元組碼指令、符號表,以及其他輔助信息。
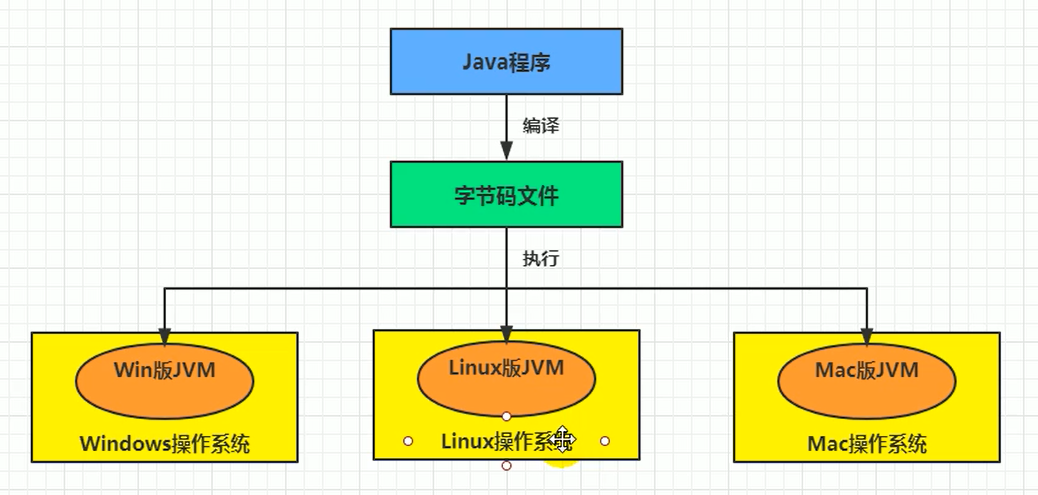
那麼,如果想要讓一個 Java 程序運行起來,執行引擎(Execution Engine)的任務就是將位元組碼指令解釋/編譯為對應平台上的本地機器指令才可以。簡單來說,JVM 中的執行引擎充當了將高級語言翻譯為機器語言的譯者。
中間那個是翻譯
執行引擎的工作流程
- 執行引擎在執行的過程中究竟需要執行什麼樣的位元組碼指令完全依賴於 PC 寄存器。
- 每當執行完一項指令操作後,PC 寄存器就會更新下一條需要被執行的指令地址。
- 當然方法在執行的過程中,執行引擎有可能會通過存儲在局部變量表中的對象引用準確定位到存儲在 Java 堆區中的對象實例信息,以及通過對象頭中的元數據指針定位到目標對象的類型信息。
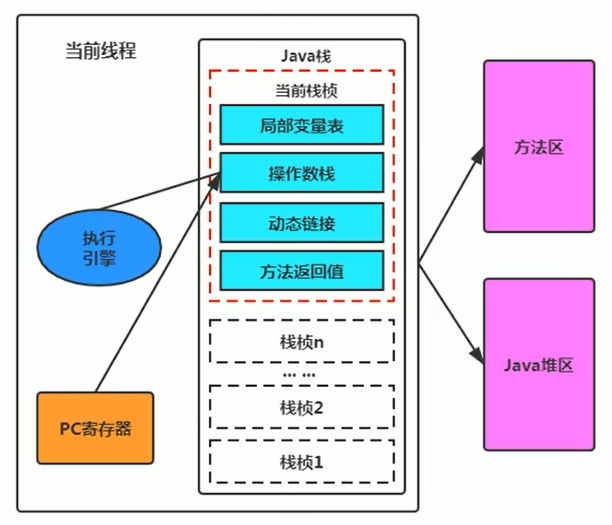
從外觀上來看,所有的 Java 虛擬機的執行引擎輸入,輸出都是一致的:輸入的是位元組碼二進制流,處理過程是位元組碼解析執行的等效過程,輸出的是執行過程。
Java 代碼編譯和執行過程
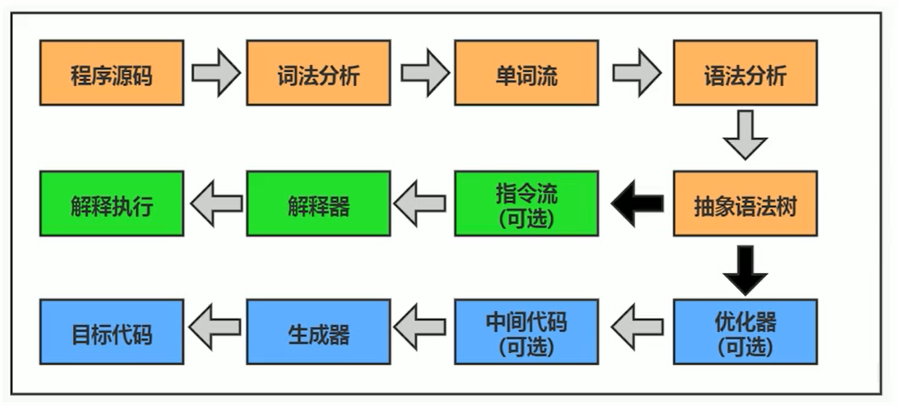
大部分的程序代碼轉換成物理機的目標代碼或虛擬機能執行的指令集之前,都需要經過上圖中的各個步驟
- 前面橙色部分是生成位元組碼文件的過程,和 JVM 無關
- 後面藍色和綠色才是 JVM 需要考慮的過程
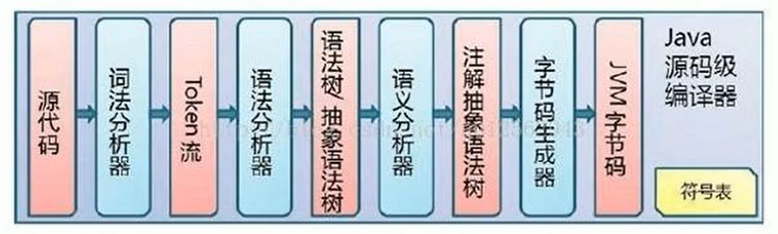
Java 代碼編譯是由 Java 源碼編譯器來完成,流程圖如下所示:
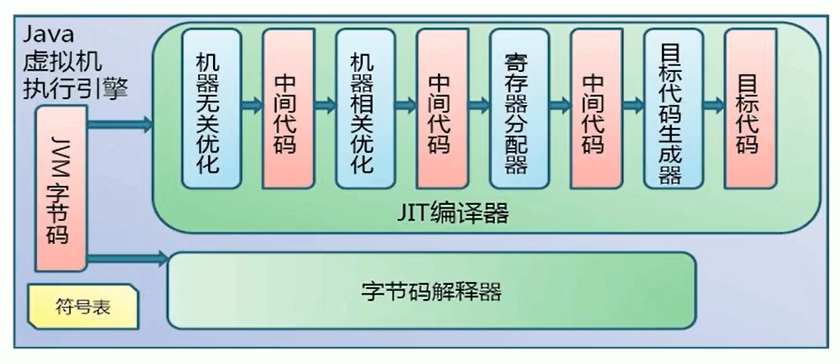
Java 位元組碼的執行是由 JVM 執行引擎來完成,流程圖如下所示
我們用一個總的圖,來說說解釋器和編譯器
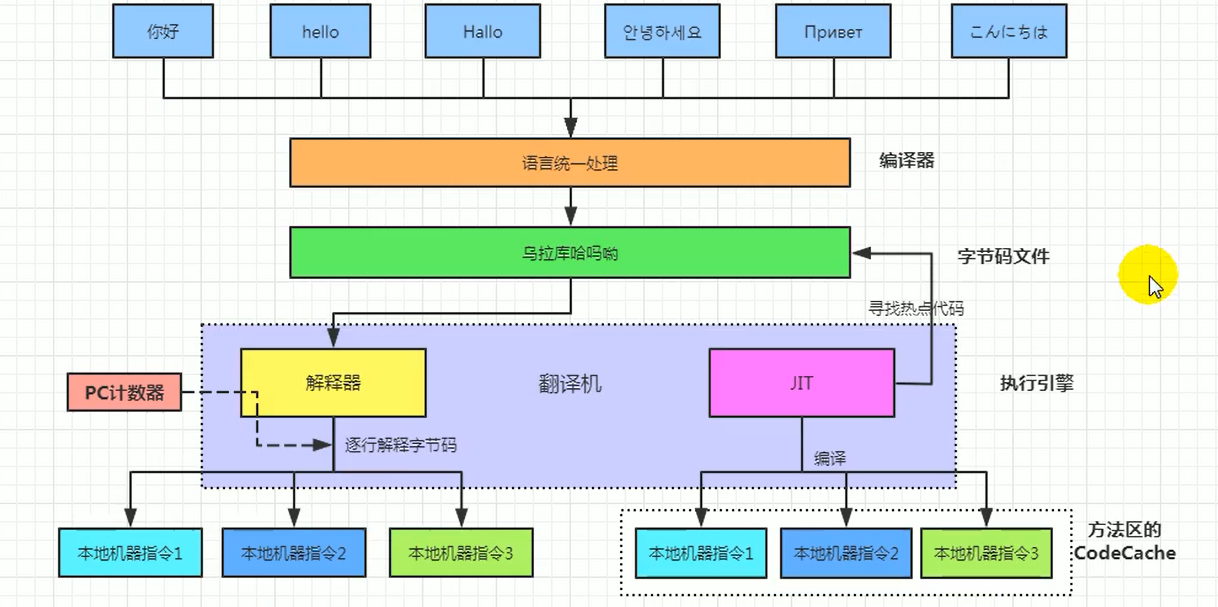
什麼是解釋器(Interpreter)
當 Java 虛擬機啟動時會根據預定義的規範對位元組碼採用逐行解釋的方式執行,將每條位元組碼文件中的內容「翻譯」為對應平台的本地機器指令執行。
什麼是JIT編譯器
JIT(Just In Time Compiler)編譯器:就是虛擬機將源代碼直接編譯成和本地機器平台相關的機器語言。
為什麼Java是半編譯半解釋型語言
JDK1.0 時代,將 Java 語言定位為「解釋執行」還是比較準確的。再後來,Java 也發展出可以直接生成本地代碼的編譯器。
現在 JVM 在執行 Java 代碼的時候,通常都會將解釋執行與編譯執行二者結合起來進行。
翻譯成本地代碼後,就可以做一個緩存操作,存儲在方法區中
機器碼、指令、彙編語言
機器碼
各種用二進制編碼方式表示的指令,叫做機器指令碼。開始,人們就用它采編寫程序,這就是機器語言。
機器語言雖然能夠被計算機理解和接受,但和人們的語言差別太大,不易被人們理解和記憶,並且用它編程容易出差錯。
用它編寫的程序一經輸入計算機,CPU 直接讀取運行,因此和其他語言編的程序相比,執行速度最快。
機器指令與 CPU 緊密相關,所以不同種類的 CPU 所對應的機器指令也就不同。
指令
由於機器碼是有 0 和 1 組成的二進制序列,可讀性實在太差,於是人們發明了指令。
指令就是把機器碼中特定的 0 和 1 序列,簡化成對應的指令(一般為英文簡寫,如 mov,inc等),可讀性稍好
由於不同的硬件平台,執行同一個操作,對應的機器碼可能不同,所以不同的硬件平台的同一種指令(比如 mov),對應的機器碼也可能不同。
指令集
不同的硬件平台,各自支持的指令,是有差別的。因此每個平台所支持的指令,稱之為對應平台的指令集。
如常見的
- x86 指令集,對應的是 x86 架構的平台
- ARM 指令集,對應的是 ARM 架構的平台
彙編語言
由於指令的可讀性還是太差,於是人們又發明了彙編語言。
在彙編語言中,用助記符(Mnemonics)代替機器指令的操作碼,用地址符號(Symbol)或標號(Label)代替指令或操作數的地址。
在不同的硬件平台,彙編語言對應着不同的機器語言指令集,通過彙編過程轉換成機器指令。
- 由於計算機只認識指令碼,所以用彙編語言編寫的程序還必須翻譯成機器指令碼,計算機才能識別和執行。
高級語言
為了使計算機用戶編程序更容易些,後來就出現了各種高級計算機語言。
高級語言比機器語言、彙編語言更接近人的語言。
當計算機執行高級語言編寫的程序時,仍然需要把程序解釋和編譯成機器的指令碼。完成這個過程的程序就叫做解釋程序或編譯程序。
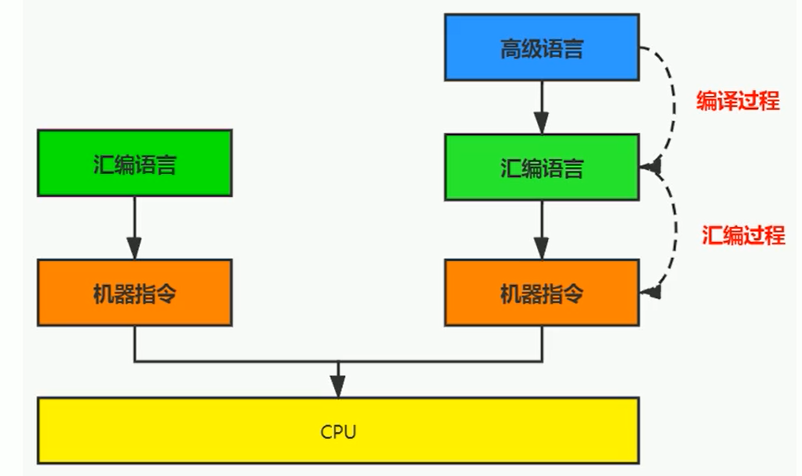
高級語言也不是直接翻譯成機器指令,而是翻譯成彙編語言嗎,如下面說的 C 和 C++
C、C++ 源程序執行過程
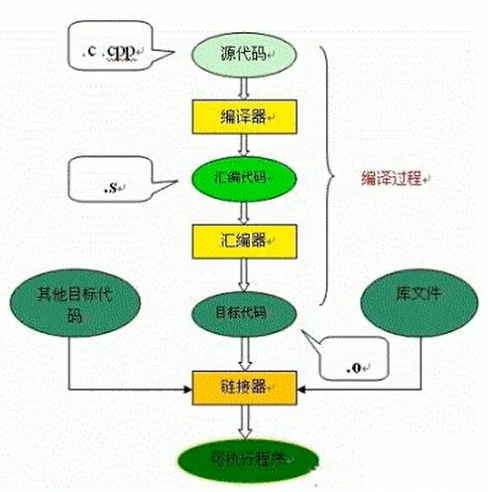
編譯過程又可以分成兩個階段:編譯和彙編。
編譯過程:是讀取源程序(字符流),對之進行詞法和語法的分析,將高級語言指令轉換為功能等效的彙編代碼
彙編過程:實際上指把彙編語言代碼翻譯成目標機器指令的過程。
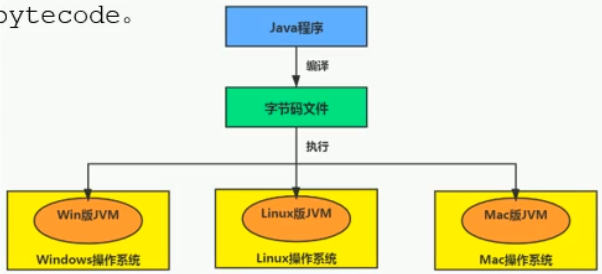
位元組碼
位元組碼是一種中間狀態(中間碼)的二進制代碼(文件),它比機器碼更抽象,需要直譯器轉譯後才能成為機器碼
位元組碼主要為了實現特定軟件運行和軟件環境、與硬件環境無關。
位元組碼的實現方式是通過編譯器和虛擬機器。編譯器將源碼編譯成位元組碼,特定平台上的虛擬機器將位元組碼轉譯為可以直接執行的指令。
- 位元組碼典型的應用為:Java bytecode
解釋器
JVM 設計者們的初衷僅僅只是單純地為了滿足 Java 程序實現跨平台特性,因此避免採用靜態編譯的方式直接生成本地機器指令,從而誕生了實現解釋器在運行時採用逐行解釋位元組碼執行程序的想法。
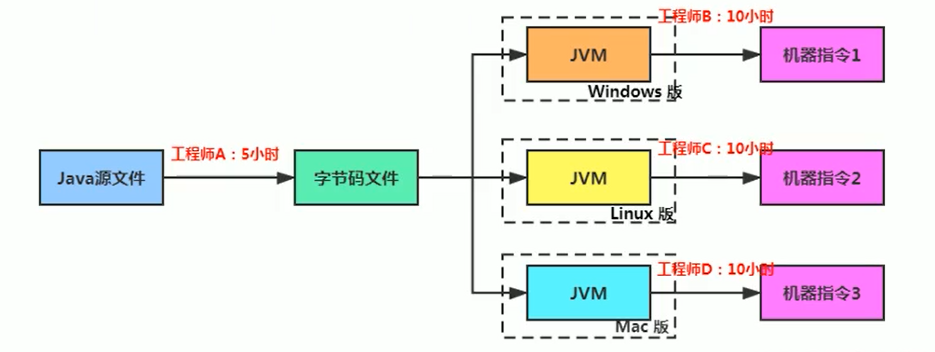
為什麼 Java 源文件不直接翻譯成機器指令,而是翻譯成位元組碼文件?
可能是因為直接翻譯的代價是比較大的,有一個中間文件進行緩衝,可以節省一部分移植到平台後翻譯的時間。
解釋器真正意義上所承擔的角色就是一個運行時「翻譯者」,將位元組碼文件中的內容「翻譯」為對應平台的本地機器指令執行。
當一條位元組碼指令被解釋執行完成後,接着再根據PC寄存器中記錄的下一條需要被執行的位元組碼指令執行解釋操作。
解釋器分類
在 Java 的發展歷史裏,一共有兩套解釋執行器,即古老的位元組碼解釋器、現在普遍使用的模板解釋器。
位元組碼解釋器在執行時通過純軟件代碼模擬位元組碼的執行,效率非常低下。
而模板解釋器將每一條位元組碼和一個模板函數相關聯,模板函數中直接產生這條位元組碼執行時的機器碼,從而很大程度上提高了解釋器的性能。
- 在 HotSpot VM 中,解釋器主要由 Interpreter 模塊和 Code 模塊構成。
- Interpreter 模塊:實現了解釋器的核心功能
- Code 模塊:用於管理 HotSpot VM 在運行時生成的本地機器指令
現狀
由於解釋器在設計和實現上非常簡單,因此除了 Java 語言之外,還有許多高級語言同樣也是基於解釋器執行的,比如 Python、Perl、Ruby等。但是在今天,基於解釋器執行已經淪落為低效的代名詞,並且時常被一些 C/C++ 程序員所調侃。
為了解決這個問題,JVM 平台支持一種叫作即時編譯的技術。即時編譯的目的是避免函數被解釋執行,而是將整個函數體編譯成為機器碼,每次函數執行時,只執行編譯後的機器碼即可,這種方式可以使執行效率大幅度提升。
不過無論如何,基於解釋器的執行模式仍然為中間語言的發展做出了不可磨滅的貢獻。
JIT 編譯器
Java 代碼的執行分類
第一種是將源代碼編譯成位元組碼文件,然後在運行時通過解釋器將位元組碼文件轉為機器碼執行
第二種是編譯執行(直接編譯成機器碼)。現代虛擬機為了提高執行效率,會使用即時編譯技術(JIT,Just In Time)將方法編譯成機器碼後再執行
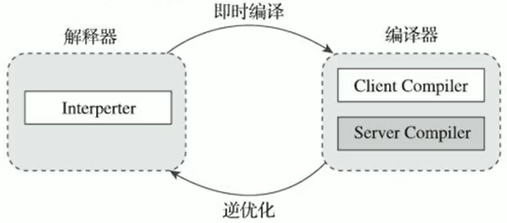
HotSpot VM 是目前市面上高性能虛擬機的代表作之一。它採用解釋器與即時編譯器並存的架構。在 Java 虛擬機運行時,解釋器和即時編譯器能夠相互協作,各自取長補短,儘力去選擇最合適的方式來權衡編譯本地代碼的時間和直接解釋執行代碼的時間。
在今天,Java 程序的運行性能早已脫胎換骨,已經達到了可以和 C/C++ 程序一較高下的地步。
問題來了
有些開發人員會感覺到詫異,既然 HotSpot VM 中已經內置 JIT 編譯器了,那麼為什麼還需要再使用解釋器來「拖累」程序的執行性能呢?比如 JRockit VM 內部就不包含解釋器,位元組碼全部都依靠即時編譯器編譯後執行。
- JRockit 虛擬機是砍掉了解釋器,也就是只採及時編譯器。那是因為呢 JRockit 只部署在服務器上,一般已經有時間讓他進行指令編譯的過程了,對於響應來說要求不高,等及時編譯器的編譯完成後,就會提供更好的性能
首先明確:
當程序啟動後,解釋器可以馬上發揮作用,省去編譯的時間,立即執行。
編譯器要想發揮作用,把代碼編譯成本地代碼,需要一定的執行時間。但編譯為本地代碼後,執行效率高。
所以:
儘管 JRockit VM 中程序的執行性能會非常高效,但程序在啟動時必然需要花費更長的時間來進行編譯。對於服務端應用來說,啟動時間並非是關注重點,但對於那些看中啟動時間的應用場景而言,或許就需要採用解釋器與即時編譯器並存的架構來換取一個平衡點。
在此模式下,當 Java 虛擬器啟動時,解釋器可以首先發揮作用,而不必等待即時編譯器全部編譯完成後再執行,這樣可以省去許多不必要的編譯時間。隨着時間的推移,編譯器發揮作用,把越來越多的代碼編譯成本地代碼,獲得更高的執行效率。
同時,解釋執行在編譯器進行激進優化不成立的時候,作為編譯器的「逃生門」。
HotSpot JVM 執行方式
當虛擬機啟動的時候,解釋器可以首先發揮作用,而不必等待即時編譯器全部編譯完成再執行,這樣可以省去許多不必要的編譯時間。並且隨着程序運行時間的推移,即時編譯器逐漸發揮作用,根據熱點探測功能,將有價值的位元組碼編譯為本地機器指令,以換取更高的程序執行效率。
案例
注意解釋執行與編譯執行在線上環境微妙的辯證關係。機器在熱機狀態可以承受的負載要大於冷機狀態。如果以熱機狀態時的流量進行切流,可能使處於冷機狀態的服務器因無法承載流量而假死。
在生產環境發佈過程中,以分批的方式進行發佈,根據機器數量劃分成多個批次,每個批次的機器數至多佔到整個集群的 1/8。曾經有這樣的故障案例:某程序員在發佈平台進行分批發佈,在輸入發佈總批數時,誤填寫成分為兩批發佈。如果是熱機狀態,在正常情況下一半的機器可以勉強承載流量,但由於剛啟動的 JVM 均是解釋執行,還沒有進行熱點代碼統計和JIT動態編譯,導致機器啟動之後,當前 1/2 發佈成功的服務器馬上全部宕機,此故障說明了 JIT 的存在。——阿里團隊
概念解釋
- Java 語言的「編譯期」其實是一段「不確定」的操作過程,因為它可能是指一個前端編譯器(其實叫「編譯器的前端」更準確一些)把.java文件轉變成.class文件的過程;
- 也可能是指虛擬機的後端運行期編譯器(JIT編譯器,Just In Time Compiler)把位元組碼轉變成機器碼的過程。
- 還可能是指使用靜態提前編譯器(AOT編譯器,Ahead of Time Compiler)直接把 .java 文件編譯成本地機器代碼的過程。
前端編譯器:Sun 的 Javac、Eclipse JDT 中的增量式編譯器(ECJ)。
JIT 編譯器:HotSpot VM 的 C1、C2 編譯器。
AOT 編譯器:GNU Compiler for the Java(GCJ)、Excelsior JET。
如何選擇熱點代碼及其探測方式
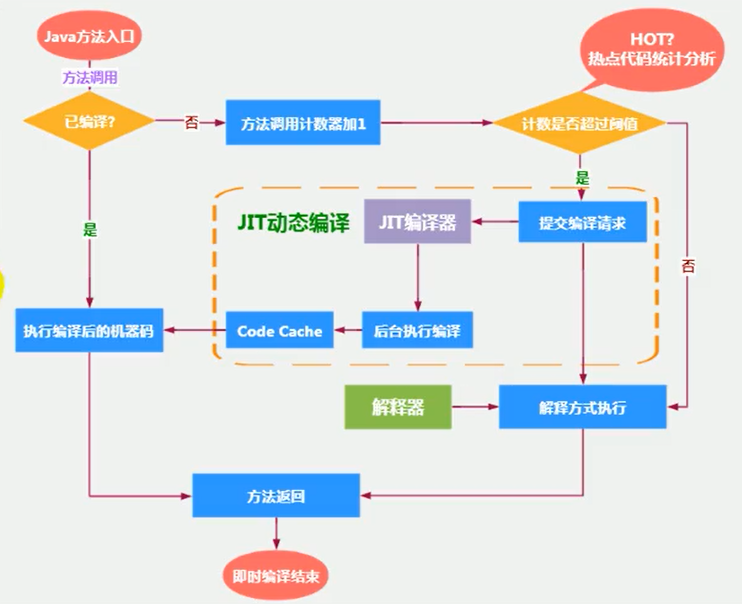
當然,是否需要啟動 JIT 編譯器將位元組碼直接編譯為對應平台的本地機器指令,則需要根據代碼被調用執行的頻率而定。關於那些需要被編譯為本地代碼的位元組碼,也被稱之為「熱點代碼」,JIT 編譯器在運行時會針對那些頻繁被調用的「熱點代碼」做出深度優化,將其直接編譯為對應平台的本地機器指令,以此提升 Java 程序的執行性能。
熱點代碼及探測方式
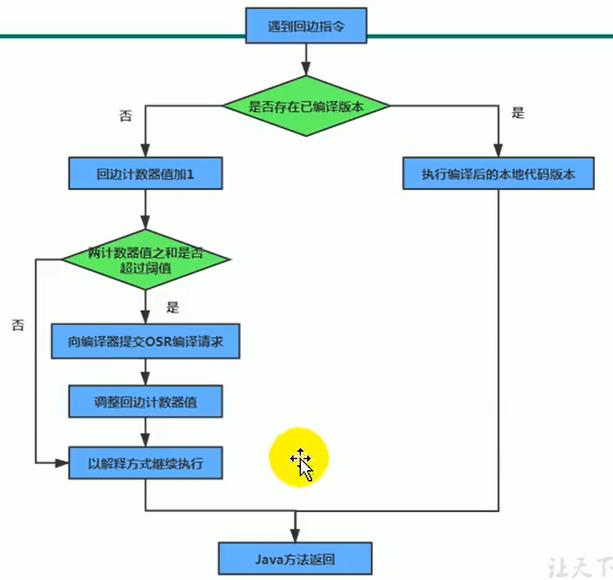
一個被多次調用的方法,或者是一個方法體內部循環次數較多的循環體都可以被稱之為「熱點代碼」,因此都可以通過 JIT 編譯器編譯為本地機器指令。由於這種編譯方式發生在方法的執行過程中,因此被稱之為棧上替換,或簡稱為 OSR(On Stack Replacement)編譯。
一個方法究竟要被調用多少次,或者一個循環體究竟需要執行多少次循環才可以達到這個標準?必然需要一個明確的閾值,JIT 編譯器才會將這些「熱點代碼」編譯為本地機器指令執行。這裡主要依靠熱點探測功能。
目前 HotSpot VM 所採用的熱點探測方式是基於計數器的熱點探測。
採用基於計數器的熱點探測,HotSpot 將會為每一個方法都建立 2 個不同類型的計數器,分別為方法調用計數器(Invocation Counter)和回邊計數器(Back Edge Counter)。
- 方法調用計數器用於統計方法的調用次數
- 回邊計數器則用於統計循環體執行的循環次數
方法調用計數器
這個計數器就用於統計方法被調用的次數,它的默認閥值在 Client 模式下是 1500 次,在 Server 模式下是 10000 次。超過這個閾值,就會觸發 JIT 編譯。
這個閥值可以通過虛擬機參數 -XX:CompileThreshold 來人為設定。
當一個方法被調用時,會先檢查該方法是否存在被 JIT 編譯過的版本,如果存在,則優先使用編譯後的本地代碼來執行。如果不存在已被編譯過的版本,則將此方法的調用計數器值加 1,然後判斷方法調用計數器與回邊計數器值之和是否超過方法調用計數器的閥值。如果已超過閾值,那麼將會向即時編譯器提交一個該方法的代碼編譯請求。
熱點衰減
如果不做任何設置,方法調用計數器統計的並不是方法被調用的絕對次數,而是一個相對的執行頻率,即 一段時間之內方法被調用的次數。當超過一定的時間限度,如果方法的調用次數仍然不足以讓它提交給即時編譯器編譯,那這個方法的調用計數器就會被減少一半,這個過程稱為方法調用計數器熱度的衰減(Counter Decay),而這段時間就稱為此方法統計的半衰周期(Counter Half Life Time)
- 半衰周期是化學中的概念,比如出土的文物通過查看C60來獲得文物的年齡
進行熱度衰減的動作是在虛擬機進行垃圾收集時順便進行的,可以使用虛擬機參數
-XX:-UseCounterDecay來關閉熱度衰減,讓方法計數器統計方法調用的絕對次數,這樣,只要系統運行時間足夠長,絕大部分方法都會被編譯成本地代碼。
另外,可以使用 -XX:CounterHalfLifeTime 參數設置半衰周期的時間,單位是秒。
回邊計數器
它的作用是統計一個方法中循環體代碼執行的次數,在位元組碼中遇到控制流向後跳轉的指令稱為「回邊」(Back Edge)。顯然,建立回邊計數器統計的目的就是為了觸發 OSR 編譯。
HotSpotVM 可以設置程序執行方式
缺省情況下 HotSpot VM 是採用解釋器與即時編譯器並存的架構,當然開發人員可以根據具體的應用場景,通過命令顯式地為 Java 虛擬機指定在運行時到底是完全採用解釋器執行,還是完全採用即時編譯器執行。如下所示:
-Xint:完全採用解釋器模式執行程序;-Xcomp:完全採用即時編譯器模式執行程序。如果即時編譯出現問題,解釋器會介入執行-Xmixed:採用解釋器+即時編譯器的混合模式共同執行程序。

HotSpotVM中 JIT 分類
JIT 的編譯器還分為了兩種,分別是 C1 和 C2,在 HotSpot VM 中內嵌有兩個 JIT 編譯器,分別為 Client Compiler 和 Server Compiler,但大多數情況下我們簡稱為 C1 編譯器和 C2 編譯器。開發人員可以通過如下命令顯式指定 Java 虛擬機在運行時到底使用哪一種即時編譯器,如下所示:
-client:指定 Java 虛擬機運行在 Client 模式下,並使用 C1 編譯器;- C1 編譯器會對位元組碼進行簡單和可靠的優化,耗時短。以達到更快的編譯速度。
-server:指定 Java 虛擬機運行在 server 模式下,並使用C2編譯器。- C2 進行耗時較長的優化,以及激進優化。但優化的代碼執行效率更高。(使用 C++)
C1 和 C2 編譯器不同的優化策略
在不同的編譯器上有不同的優化策略,C1 編譯器上主要有方法內聯,去虛擬化、元余消除。
- 方法內聯:將引用的函數代碼編譯到引用點處,這樣可以減少棧幀的生成,減少參數傳遞以及跳轉過程
- 去虛擬化:對唯一的實現樊進行內聯
- 冗餘消除:在運行期間把一些不會執行的代碼摺疊掉
C2 的優化主要是在全局層面,逃逸分析是優化的基礎。基於逃逸分析在 C2 上有如下幾種優化:
- 標量替換:用標量值代替聚合對象的屬性值
- 棧上分配:對於未逃逸的對象分配對象在棧而不是堆
- 同步消除:清除同步操作,通常指 synchronized
分層編譯策略
分層編譯(Tiered Compilation)策略:程序解釋執行(不開啟性能監控)可以觸發 C1 編譯,將位元組碼編譯成機器碼,可以進行簡單優化,也可以加上性能監控,C2 編譯會根據性能監控信息進行激進優化。
不過在 Java7 版本之後,一旦開發人員在程序中顯式指定命令「-server”時,默認將會開啟分層編譯策略,由 C1 編譯器和 C2 編譯器相互協作共同來執行編譯任務。
總結
- 一般來講,JIT 編譯出來的機器碼性能比解釋器搞
- C2 編譯器啟動時長比 C1 慢,系統穩定執行以後,C2 編譯器執行速度遠快於 C1 編譯器
寫到最後
- 自 JDK10 起,HotSpot 又加入了一個全新的及時編譯器:Graal 編譯器
- 編譯效果短短几年時間就追評了 G2 編譯器,未來可期
- 目前,帶着實驗狀態標籤,需要使用開關參數
-XX:+UnlockExperimentalvMOptions -XX:+UseJVMCICompiler去激活才能使用
AOT編譯器
jdk9 引入了 AOT 編譯器(靜態提前編譯器,Ahead Of Time Compiler)
Java 9 引入了實驗性 AOT 編譯工具 jaotc。它藉助了 Graal 編譯器,將所輸入的 Java 類文件轉換為機器碼,並存放至生成的動態共享庫之中。
所謂 AOT 編譯,是與即時編譯相對立的一個概念。我們知道,即時編譯指的是在程序的運行過程中,將位元組碼轉換為可在硬件上直接運行的機器碼,並部署至託管環境中的過程。而 AOT 編譯指的則是,在程序運行之前,便將位元組碼轉換為機器碼的過程。
- .java -> .class -> (使用jaotc) -> .so
最大的好處:Java 虛擬機加載已經預編譯成二進制庫,可以直接執行。不必等待及時編譯器的預熱,減少 Java 應用給人帶來「第一次運行慢」的不良體驗
缺點:
- 破壞了 java 「 一次編譯,到處運行」,必須為每個不同的硬件,OS 編譯對應的發行包
- 降低了 Java 鏈接過程的動態性,加載的代碼在編譯器就必須全部已知。
- 還需要繼續優化中,最初只支持 Linux X64 java base


