如何進行算法的複雜度分析?

前言
本篇文章收錄於專輯://dwz.win/HjK
你好,我是彤哥,一個每天爬二十六層樓還不忘讀源碼的硬核男人。
大家都知道,數據結構與算法解決的主要問題就是「快」和「省」的問題,即如何讓代碼運行得更快, 如何讓代碼更節省存儲空間。
所以,「快」和「省」是衡量一個算法非常重要的兩項指標,也就是我們經常聽到的時間複雜度和空間複雜度分析。
那麼,為什麼需要複雜度分析呢?複雜度分析的方法論是什麼呢?
這就是我們本節要解決的問題。
好了,進入今天的學習吧。
為什麼需要複雜度分析?
首先,我們來思考一個問題:對於兩個算法,我們如何評判誰運行得更快,誰運行時更節省內存?
你可能會說,這還不簡單,把這兩個算法運行一遍,統計下運行時間和佔用內存不就可以了嗎?
沒錯,這確實是一種不錯的方法,而且它還有個非常形象的名字:事後統計法。
但是,這種統計方法具有非常明顯的問題:
-
不同的輸入對結果影響很大
對於一些輸入,可能算法A執行得更快;對於另外一些輸入,可能算法B執行得更快。比如,我們後面要學習的排序算法,輸入的有序性對於不同的排序算法的影響是完全不同的。
-
不同的機器對結果影響很大
對於同樣的輸入,可能在一台機器上算法A更快,而在另外一台機器上算法B更快。比如,算法A可以利用多核而算法B不能,那麼CPU的核數對這兩個算法的影響將截然不同。
-
數據規模對結果影響很大
當數據規模小時,可能算法A更快,而數據規模變大時,可能算法B更快。比如,我們後面要學習的排序算法,當數據規模比較小時,插入排序反而比歸併排序更快。
所以,我們需要一種可以不用實際運行算法,就可以估計算法執行效率的方法。
這也就是我們所說的複雜度分析。
那麼,怎麼進行複雜度分析呢?有沒有什麼方法論呢?
還真有,這個方法論叫作漸近分析法。
什麼是漸近分析法?
漸近分析法,是指將算法執行的效率與輸入的規模進行掛鈎,隨着輸入規模的增大,算法執行所需要的時間(或空間)將呈現一種什麼樣的趨勢,這種趨勢就叫作漸近,而這種方法就叫作漸近分析法。
概念可能比較拗口,我舉個簡單的例子,對於給定的一個有序數組,我要查找其中某個值所在的位置,比如,查找8這個元素,有哪些方法呢?

簡單暴力點的方法,從頭遍歷,查找到該元素即返回。
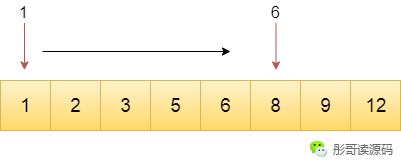
更友好一點的方法,採用二分法,每次定位到數據的中間位置,看其值與目標值的大小,判斷是在左邊還是右邊繼續以二分的方式查找。
上面我們舉的例子的輸入規模是8個元素的有序數組,目標值為8,使用第二種方法明顯比第一種方法要快很多。
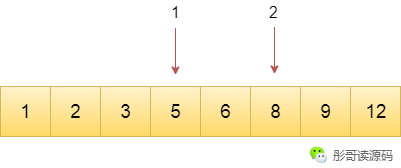
但是,如果查找的目標是1呢?
對於第一種方法,查找一次足矣。
對於第二種方法,需要查找3次。
此時,第二種方法又次於第一種方法了。
所以,比較兩個算法的執行效率,不能只考慮到個別元素,而應該顧及到所有元素的感受。
我們以數學的方法來統計兩種方法的平均執行效率,假設輸入規模擴展到n。
對於第一種方法,1號元素查找一次,2號元素查找兩次,3號元素查找三次……,而查找每個元素的概率都是1/n。
所以,它的執行效率為:1×1/n + 2×1/n + 3×1/n + … nx1/n = nx(n+1)/2/n = (n+1)/2。
對於第二種方法,中間的元素有一個,查找一次,次中間的元素有兩個,查找兩次,次次中間的元素有四個,查找三次…,每次查找的規模都縮小一半,而查找每個元素的概率都是1/n。
所以,它的執行效率為:1x1x1/n + 2x2x1/n + 4x3x1/n + … + 2^(log2(n)-2) x (log2(n)-1) x 1/n+ 2^(log2(n)-1) x log2(n) x 1/n = ?
我了個去,這個結果等於多少?
是時候展現真正的實力了:

你可能要罵娘了,對於我一個小學畢業的,難道我沒辦法學習數據結構與算法了?
No,No,No,肯定不能這麼玩,那麼,應該怎麼玩呢?我們下一節接着講。
後記
本節,我們從算法執行效率方面闡述了為什麼需要複雜度分析,並介紹了複雜度分析的方法,即漸近分析法,如果嚴格地遵循漸近分析法,需要大量的數學知識,這無疑增加了我們分析算法的難度,那麼,有沒有什麼更省心地計算複雜度的方法呢?
關注公眾號「彤哥讀源碼」,解鎖更多源碼、基礎、架構知識!


