JVM 學習筆記(五)
前言:
前面的文件介紹了JVM的內存模型以及各個區域存放了那些內容,本編文章將介紹JVM中的垃圾回收Garbage Collector,和大家一起探討一下。
如何確定一個對象是垃圾:
這裡介紹兩種方法:
-
引用計數法
-
可達性分析
垃圾回收算法:
-
標記-清除(Mark-Sweep)
-
標記
找出內存中需要回收的對象,並且把它們標記出來。此時堆中所有的對象都會被掃描一遍,從而才能確定需要回收的對象,比較耗時。
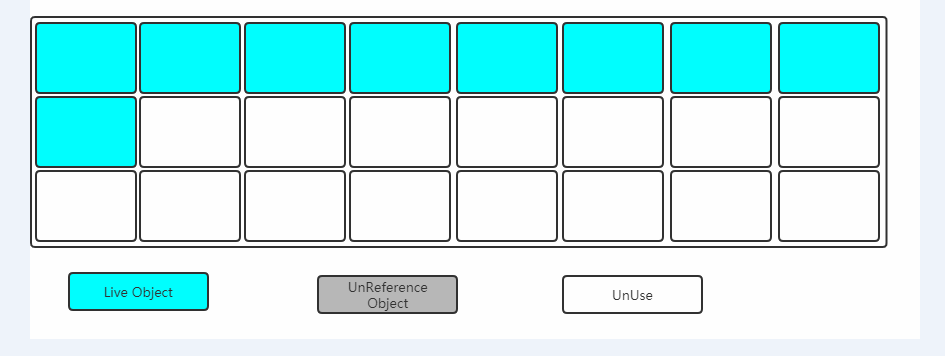
如圖:綠色的區域表示當前存活的對象,灰色表示垃圾對象,白色表示沒有用到的內存碎片。

2. 清除
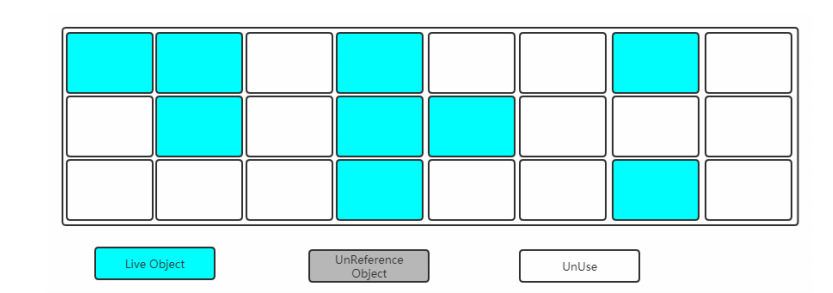
有以下缺點:
-
複製(Copying)
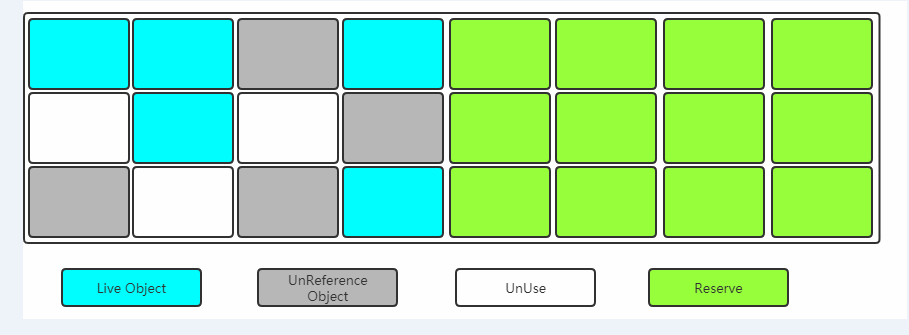
當其中一塊內存使用完了,就將還存活的對象複製到另外一塊上面,然後把已經使用過的內存空間一次清除掉。
下圖的清理過後的內存模型:
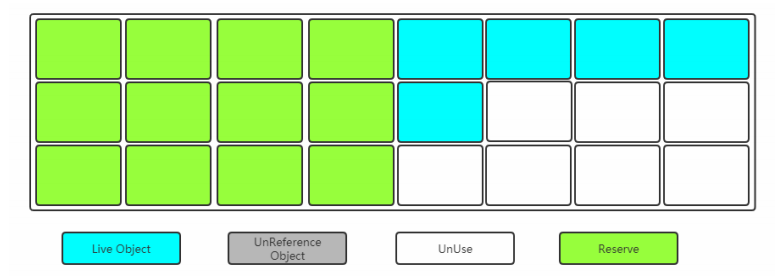
缺點:
因為這種方法保留的兩個大小一樣的內存區域,而同一時刻只會用到其中的一個,所以該方法內存的空間利用率比較低。
-
標記-整理(Mark-Compact)
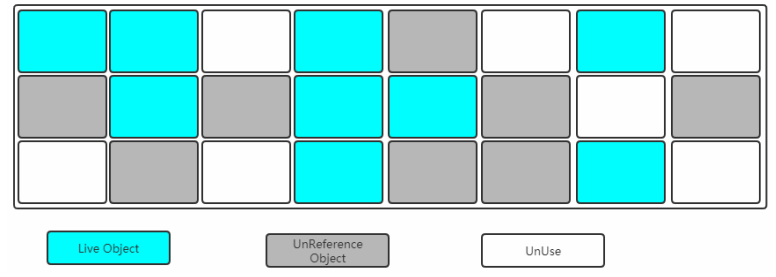
下圖是整理階段,該階段會將被標記的區域清除,並把存活的對象往一端移動,這樣內存區域就會連續化,不會有空間碎片。
分代收集算法:
垃圾收集器的介紹:
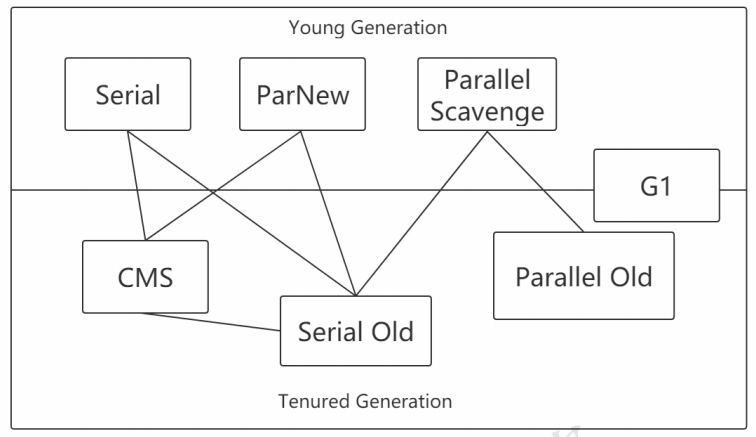
下面來介紹這幾種垃圾收集器:
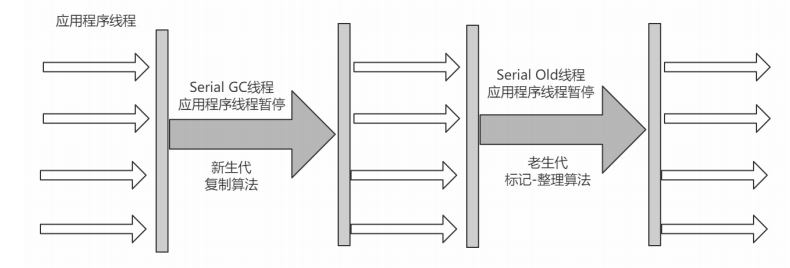
1.Serial收集器
優點:簡單高效,擁有很高的單線程收集效率
缺點:收集過程需要暫停所有線程
算法:複製算法
適用範圍:新生代
應用:Client模式下的默認新生代收集器
下圖是該模式下的應用線程狀態圖:

2. ParNew收集器
簡單理解為是Serial收集器的多線程版本。
簡單總結一下該收集器:
優點:在多CPU時,比Serial效率高。
缺點:收集過程暫停所有應用程序線程,單CPU時比Serial效率差。
算法:複製算法
適用範圍:新生代
應用:運行在Server模式下的虛擬機中首選的新生代收集器
3. Parallel Scavenge收集器
這裡解釋一下什麼是吞吐量:
4. Serial Old收集器
下圖是該模式下的應用線程狀態圖:
5. Parallel Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多線程和”標記-整理算法”進行垃圾回收。
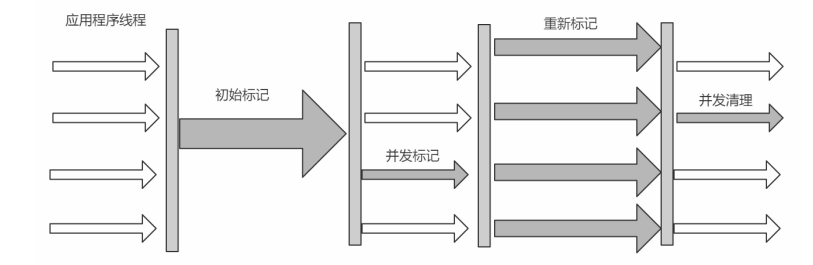
6. CMS收集器
7. G1收集器
G1 (Garbage-First)是一款面向服務器的垃圾收集器,主要針對配備多顆處理器及大容量內存的機器. 以極高概率滿足GC停頓時間要求的同時,還具備高吞吐量性能特徵. 在Oracle JDK 7 update 4 及以上版本中得到完全支持, 專為以下應用程序設計:
- 可以像CMS收集器一樣,GC操作與應用的線程一起並發執行
- 緊湊的空閑內存區間且沒有很長的GC停頓時間.
- 需要可預測的GC暫停耗時.
- 不想犧牲太多吞吐量性能.
- 啟動後不需要請求更大的Java堆.
G1的長期目標是取代CMS(Concurrent Mark-Sweep Collector, 並發標記-清除). 因為特性的不同使G1成為比CMS更好的解決方案. 一個區別是,G1是一款壓縮型的收集器.G1通過有效的壓縮完全避免了對細微空閑內存空間的分配,不用依賴於regions,這不僅大大簡化了收集器,而且還消除了潛在的內存碎片問題。除壓縮以外,G1的垃圾收集停頓也比CMS容易估計,也允許用戶自定義所希望的停頓參數(pause targets)
歸納總結一下G1收集器的特點:
1.並行與並發
2.分代收集(仍然保留了分代的概念)
3.空間整合(整體上屬於「標記-整理」算法,不會導致空間碎片)
4.可預測的停頓(比CMS更先進的地方在於能讓使用者明確指定一個長度為M毫秒的時間片段內,消耗在垃圾收集 上的時間不得超過N毫秒)。
初始標記(Initial Marking) 標記一下GC Roots能夠關聯的對象,並且修改TAMS的值,需要暫 停用戶線程
並發標記(Concurrent Marking) 從GC Roots進行可達性分析,找出存活的對象,與用戶線程並發 執行
最終標記(Final Marking) 修正在並發標記階段因為用戶程序的並發執行導致變動的數據,需 暫停用戶線程
篩選回收(Live Data Counting and Evacuation) 對各個Region的回收價值和成本進行排序,根據 用戶所期望的GC停頓時間制定回收計劃
垃圾收集器分類:
串行收集器->Serial和Serial Old
並行收集器[吞吐量優先]->Parallel Scanvenge、Parallel Old
並發收集器[停頓時間優先]->CMS、G1
理解吞吐量和停頓時間:
如何選擇合適的垃圾收集器:
首先我們了解一下官網是如何建議的:

簡單翻譯一下就是:
1.優先調整堆的大小讓服務器自己來選擇
2.如果內存小於100M,使用串行收集器
3.如果是單核,並且沒有停頓時間要求,使用串行或JVM自己選
4.如果允許停頓時間超過1秒,選擇並行或JVM自己選
5.如果響應時間最重要,並且不能超過1秒,使用並發收集器

