整取零存_字段級遷移工具
- 2020 年 7 月 6 日
- 筆記
6月份的大部分時間在完成一個特殊的數據遷移工具,將文件中的標籤整合到關係型數據庫的表字段中。從近幾年的技術趨勢和參與的項目看,基本都是從關係型數據庫往大數據組件遷移。在這個項目中,主要是客戶和相關應用的供應商依賴於PostgreSQL的GIS插件。因此我也有幸使用了一次PostgreSQL數據庫。本文簡要講解了工具開發的背景和難點,並給出了程序邏輯和源代碼鏈接。
01 需求和背景
a). 為什麼說這是一個字段級別的遷移?
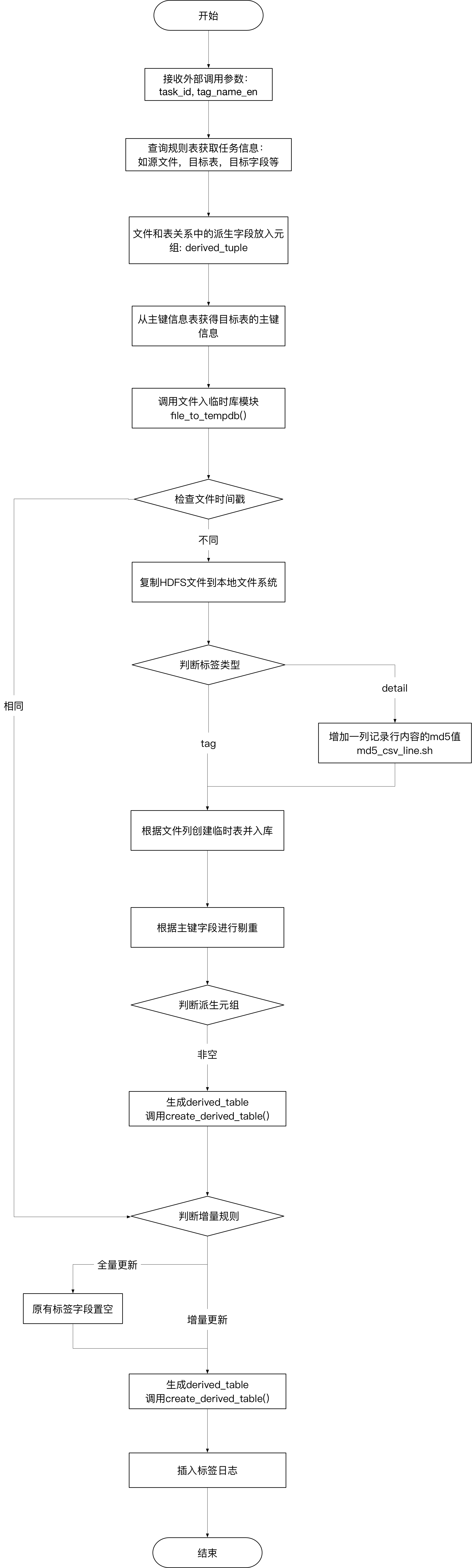
作為數據源的標籤文件數量非常多,根據標籤的分類和加工的便利程度,有大量含有各位數據標籤列的文件。而同時在PG庫表中,為了減少join,提升數據庫查詢速度,大量標籤字段又合在一張表中。結果就是存在,一個文件的不同列可能映射到不同的表中,一張表的不同字段來自於不同的文件。文件和表存在的是多對多的關係。這就造成不能簡單地做出某個文件到某張表的映射關係,然後使用導入工具導入即可。
同時,對於客戶和使用者而言,他們希望看到的是就是標籤值(即對應數據庫中的字段)。通過展示標籤級別的映射關係,最終用戶可以知曉每個標籤的業務含義和數據來源;通過展示每個標籤的加工狀態,管理員可以快速獲取整體標籤的可用性。
最後,數據源結構上是半結構化的csv文件,列的數量和存放順序可能發生改變。文件和表的將是動態的,維護起來的工作量也過於巨大。
b). 開發中依賴的一些業務說明
首先,對於標籤類數據的存放表,認為是有業務主鍵的,這些主鍵也是其他應用查詢數據時的條件。程序中使用這些主鍵來完成新標籤數據的插入和舊標籤數據的更新。
對於明細類數據,數據源的定義認為是沒有主鍵的日誌類數據,只有插入的操作無更新的操作。
同時,標籤的更新方式還分為增量和全量。增量即常規的merge操作,而全量方式需要將表中的指定標籤字段置空後再進行merge操作。
02 遇到的問題和解決方法
a). 文件的導入和並發控制
雖然每一個任務都是字段級別操作的,但是對於數據源文件的導入存在多個標籤對應同一源文件的情況,所以在文件導入操作上有一個專門的狀態表記錄文件導入的狀態。如果有其它標籤任務在執行相同的文件導入了,狀態就會變成processing。作為一個後來的任務,必須等待狀態為success或者fail時才能進行文件的再次導入。
同時為了避免文件的再次導入,每次導入還會比較HDFS中文件的時間戳和狀態表中的時間戳,如果時間戳一致,則直接使用已導入的文件即可。
b). 文件的動態入庫
csv文件的首行列名作為字段名,文件名作為表明在臨時庫創建一張臨時表,然後使用copy_expert函數避免雙引號分界符內容中存在逗號的問題。
c). 明細和標籤的整合
為了讓兩者使用同一套字段級別的merge方法,對於明細的數據在傳到本地文件系統後,調用shell命令根據每一行的內容加行號md5 hash之後作為一行明細的主鍵。從而每一行數據都是唯一的,保證了數據在調用merge操作時只有insert行為。
d). 派生字段的處理
這裡的派生字段是指,在原文件的列名中包含了一層數據,比如說同一個文件存在一列名「甲品牌_銷售額」和「乙品牌_銷售額」,而最終的標籤需求為「銷售額」,「品牌」。即一列將變成兩列,同時數據行數將變成原有行數的(品牌枚舉值個數)倍。
這個擴展的操作,是在源文件入臨時庫之後,通過遍歷「品牌」枚舉值,將其它列數據進行union all操作實現。
e). 字段類型轉換
因為原始文件導入都是以文本形式入庫,實際標籤值可能有數字、布爾、地理坐標等類型,需要有一個專門的函數對標籤值進行類型轉換操作。
f). PostgreSQL中的merge操作
在PostgreSQL中,merge操作通過insert into on conflict () do update set = excluded.實現。
工具的處理邏輯
代碼和遺留問題
代碼github鏈接github
遺留問題:
- 對於主鍵的要求的強制的,但是程序沒有主動去目標表中增加主鍵;
- 對於派生字段只能提供增加一個字段,不支持多個;
- 在幾千條數據源情況下,單個標籤導入的時間為2秒左右,未對千萬級數據源做性能測試;
- 未提供多標籤同時導入的接口
- 執行信息用了print()打印在屏幕,需要使用log模塊優化輸出和分類。
總結
本文分享近期開發的一個標籤/字段級別數據遷移的工具,通過Python實現。介紹了工具的一些背景和實現的一些難點。同時分享了工具的核心代碼,拋磚引玉,希望跟有興趣的同學共同探討更高效的實現方式。
歡迎掃描二維碼關注公眾號



