從Linux源碼看Socket(TCP)Client端的Connect
從Linux源碼看Socket(TCP)Client端的Connect
前言
筆者一直覺得如果能知道從應用到框架再到操作系統的每一處代碼,是一件Exciting的事情。
今天筆者就來從Linux源碼的角度看下Client端的Socket在進行Connect的時候到底做了哪些事情。由於篇幅原因,關於Server端的Accept源碼講解留給下一篇博客。
(基於Linux 3.10內核)
一個最簡單的Connect例子
int clientSocket;
if((clientSocket = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
// 創建socket失敗失敗
return -1;
}
......
if(connect(clientSocket, (struct sockaddr *)&serverAddr, sizeof(serverAddr)) < 0) {
// connect 失敗
return -1;
}
.......
首先我們通過socket系統調用創建了一個socket,其中指定了SOCK_STREAM,而且最後一個參數為0,也就是建立了一個通常所有的TCP Socket。在這裡,我們直接給出TCP Socket所對應的ops也就是操作函數。
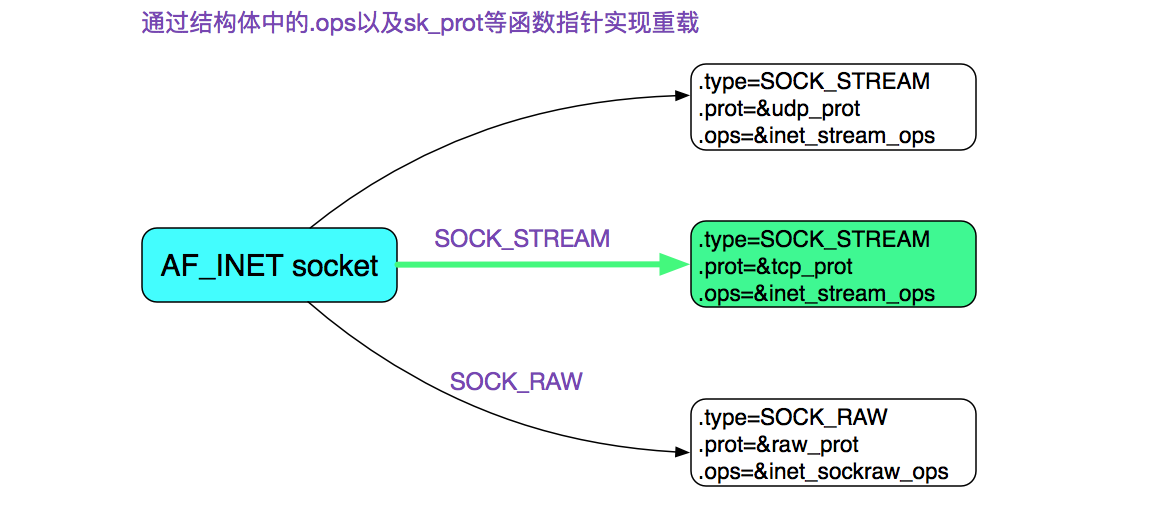
如果你想知道上圖中的結構是怎麼來的,可以看下筆者以前的博客:
//my.oschina.net/alchemystar/blog/1791017
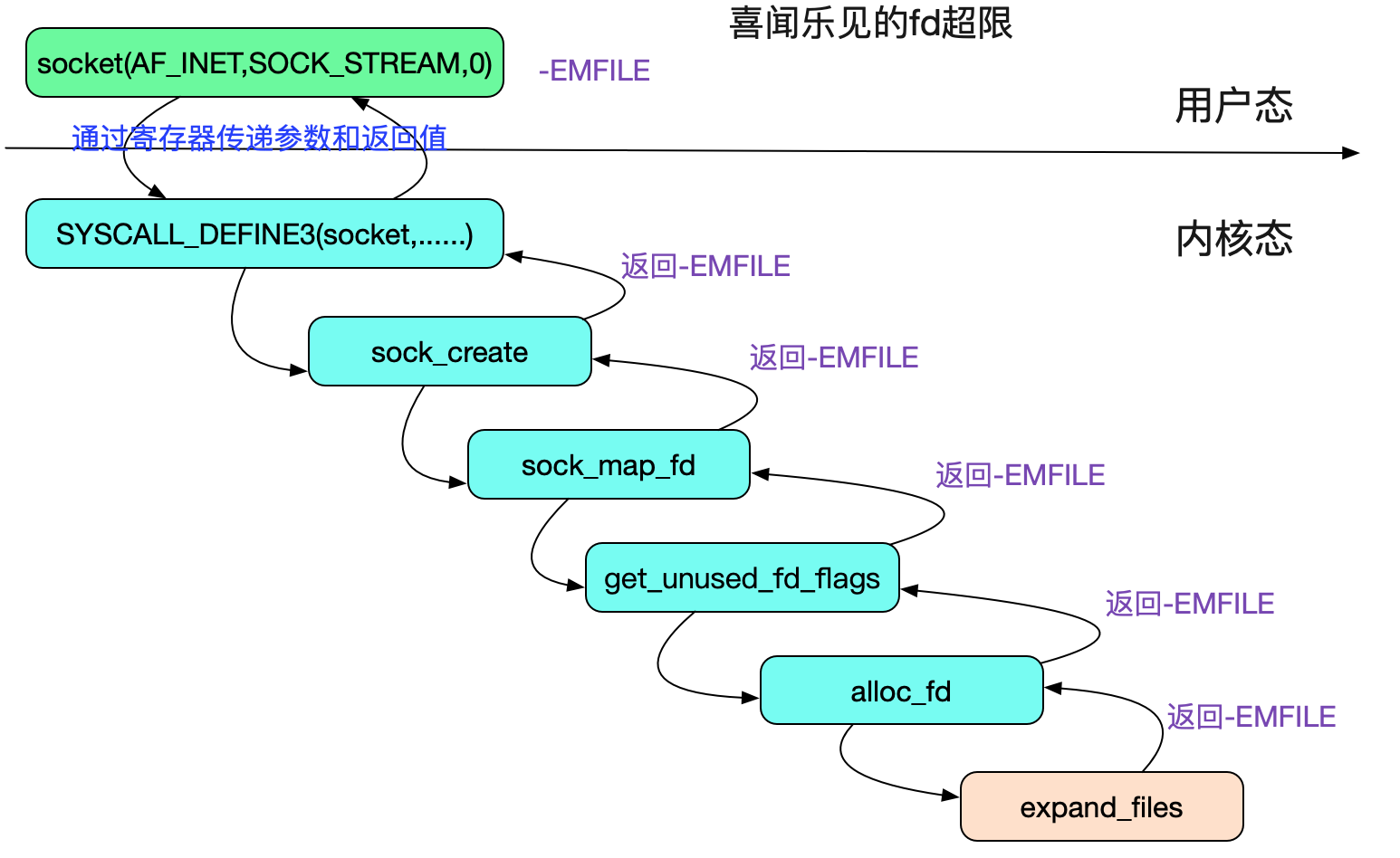
值得注意的是,由於socket系統調用操作做了如下兩個代碼的判斷
sock_map_fd
|->get_unused_fd_flags
|->alloc_fd
|->expand_files (ulimit)
|->sock_alloc_file
|->alloc_file
|->get_empty_filp (/proc/sys/fs/max_files)
第一個判斷,ulmit超限:
int expand_files(struct files_struct *files, int nr
{
......
if (nr >= current->signal->rlim[RLIMIT_NOFILE].rlim_cur)
return -EMFILE;
......
}
這邊的判斷即是ulimit的限制!在這裡返回-EMFILE對應的描述就是
“Too many open files”
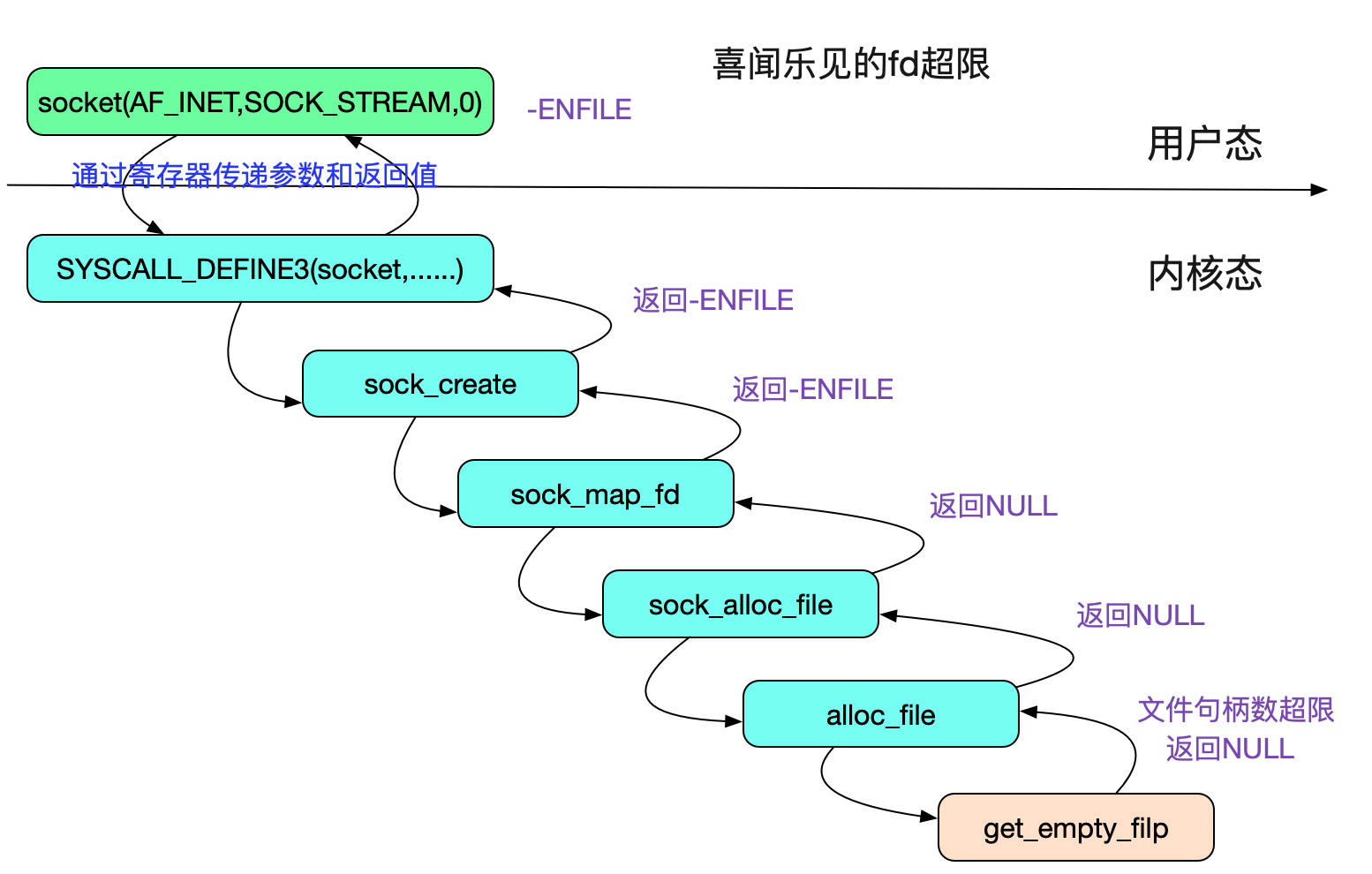
第二個判斷max_files超限
struct file *get_empty_filp(void)
{
......
/*
* 由此可見,特權用戶可以無視文件數最大大小的限制!
*/
if (get_nr_files() >= files_stat.max_files && !capable(CAP_SYS_ADMIN)) {
/*
* percpu_counters are inaccurate. Do an expensive check before
* we go and fail.
*/
if (percpu_counter_sum_positive(&nr_files) >= files_stat.max_files)
goto over;
}
......
}
所以在文件描述符超過所有進程能打開的最大文件數量限制(/proc/sys/fs/file-max)的時候會返回-ENFILE,對應的描述就是”Too many open files in system”,但是特權用戶確可以無視這一限制,如下圖所示:
connect系統調用
我們再來看一下connect系統調用:
int connect(int sockfd,const struct sockaddr *serv_addr,socklen_t addrlen)
這個系統調用有三個參數,那麼依據規則,它肯定在內核中的源碼長下面這個樣子
SYSCALL_DEFINE3(connect, ......
筆者全文搜索了下,就找到了具體的實現:
socket.c
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
int, addrlen)
{
......
err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen,
sock->file->f_flags);
......
}
前面圖給出了在TCP下的sock->ops == inet_stream_ops,然後再陷入到更進一步的調用棧中,即下面的:
SYSCALL_DEFINE3(connect
|->inet_stream_ops
|->inet_stream_connect
|->tcp_v4_connect
|->tcp_set_state(sk, TCP_SYN_SENT);設置狀態為TCP_SYN_SENT
|->inet_hash_connect
|->tcp_connect
首先,我們來看一下inet_hash_connect這個函數,裏面有一個端口號的搜索過程,搜索不到可用端口號就會導致創建連接失敗!內核能夠建立一個連接也是跋涉了千山萬水的!我們先看一下搜索端口號的邏輯,如下圖所示:
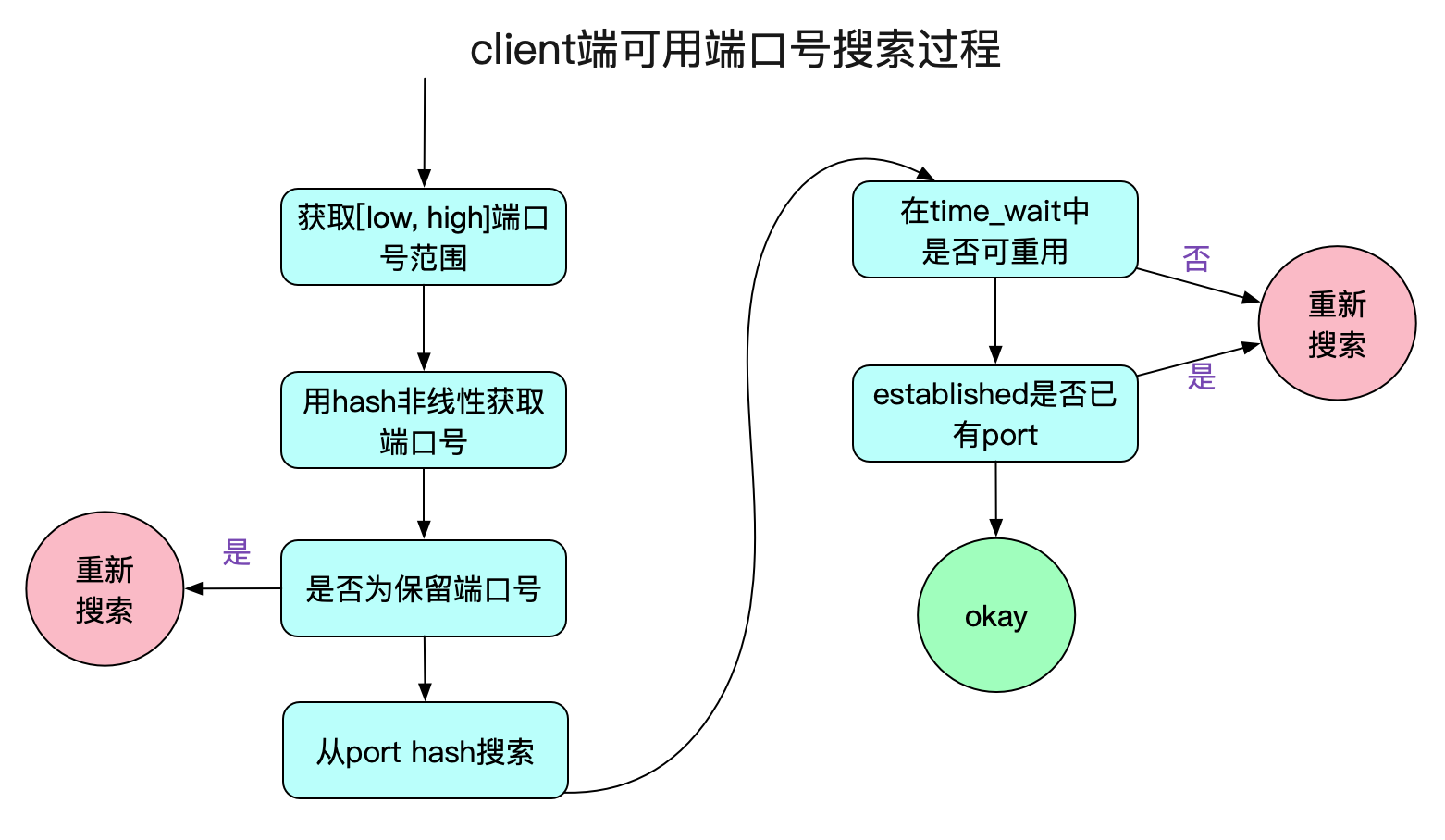
獲取端口號範圍
首先,我們從內核中獲取connect能夠使用的端口號範圍,在這裡採用了Linux中的順序鎖(seqlock)
void inet_get_local_port_range(int *low, int *high)
{
unsigned int seq;
do {
// 順序鎖
seq = read_seqbegin(&sysctl_local_ports.lock);
*low = sysctl_local_ports.range[0];
*high = sysctl_local_ports.range[1];
} while (read_seqretry(&sysctl_local_ports.lock, seq));
}
順序鎖事實上就是結合內存屏障等機制的一種樂觀鎖,主要依靠一個序列計數器。在讀取數據之前和之後,序列號都被讀取,如果兩者的序列號相同,說明在讀操作的時候沒有被寫操作打斷過。
這也保證了上面的讀取變量都是一致的,也即low和high不會出現low是改前值而high是改後值得情況。low和high要麼都是改之前的,要麼都是改之後的!內核中修改的地方為:
cat /proc/sys/net/ipv4/ip_local_port_range
32768 61000
通過hash決定端口號起始搜索範圍
在Linux上進行connect,內核給其分配的端口號並不是線性增長的,但是也符合一定的規律。
先來看下代碼:
int __inet_hash_connect(...)
{
// 注意,這邊是static變量
static u32 hint;
// 這邊的port_offset是用對端ip:port hash的一個值
// 也就是說對端ip:port固定,port_offset固定
u32 offset = hint + port_offset;
for (i = 1; i <= remaining; i++) {
port = low + (i + offset) % remaining;
/* port是否佔用check */
....
goto ok;
}
.......
ok:
hint += i;
......
}
這裏面有幾個小細節,為了安全原因,Linux本身用對端ip:port做了一次hash作為搜索的初始offset,所以不同遠端ip:port初始搜索範圍可以基本是不同的!但同樣的對端ip:port初始搜索範圍是相同的!
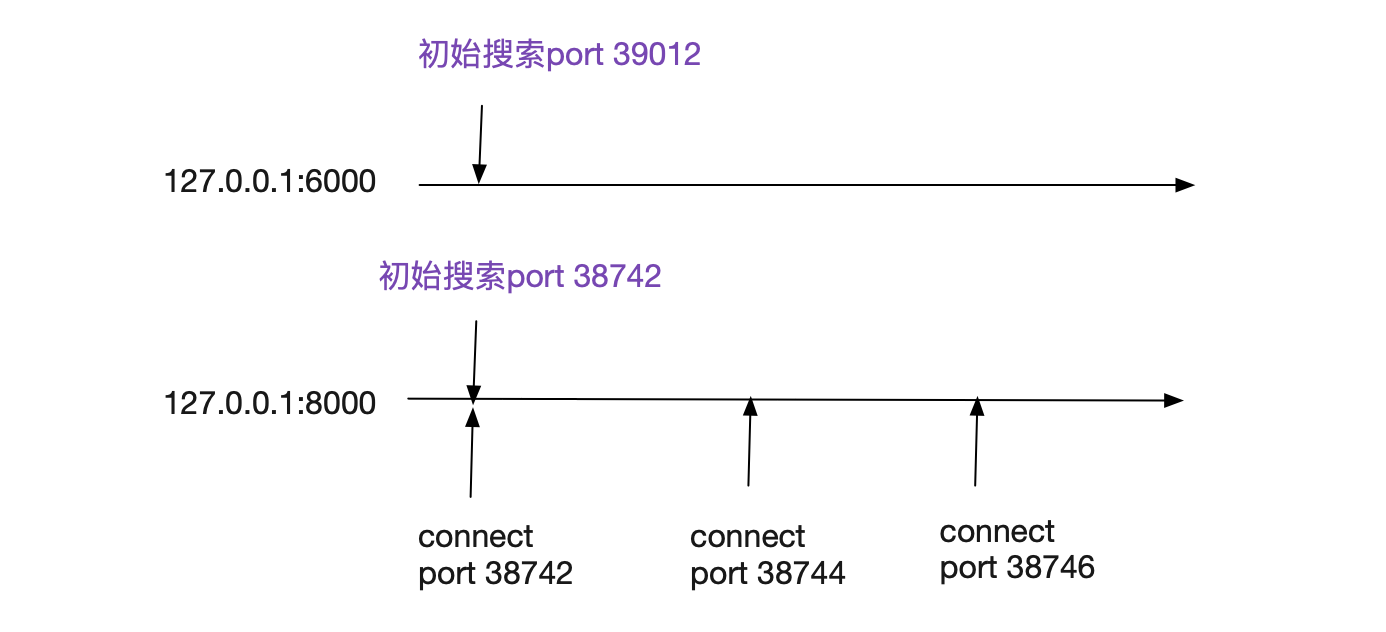
在筆者機器上,一個完全乾凈的內核裏面,不停的對同一個遠端ip:port,其以2進行穩定增長,也即38742->38744->38746,如果有其它的干擾,就會打破這個規律。
端口號範圍限制
由於我們指定了端口號返回ip_local_port_range是不是就意味着我們最多創建high-low+1個連接呢?當然不是,由於檢查端口號是否重複是將(網絡命名空間,對端ip,對端port,本端port,Socket綁定的dev)當做唯一鍵進行重複校驗,所以限制僅僅是在同一個網絡命名空間下,連接同一個對端ip:port的最大可用端口號數為high-low+1,當然可能還要減去ip_local_reserved_ports。如下圖所示:
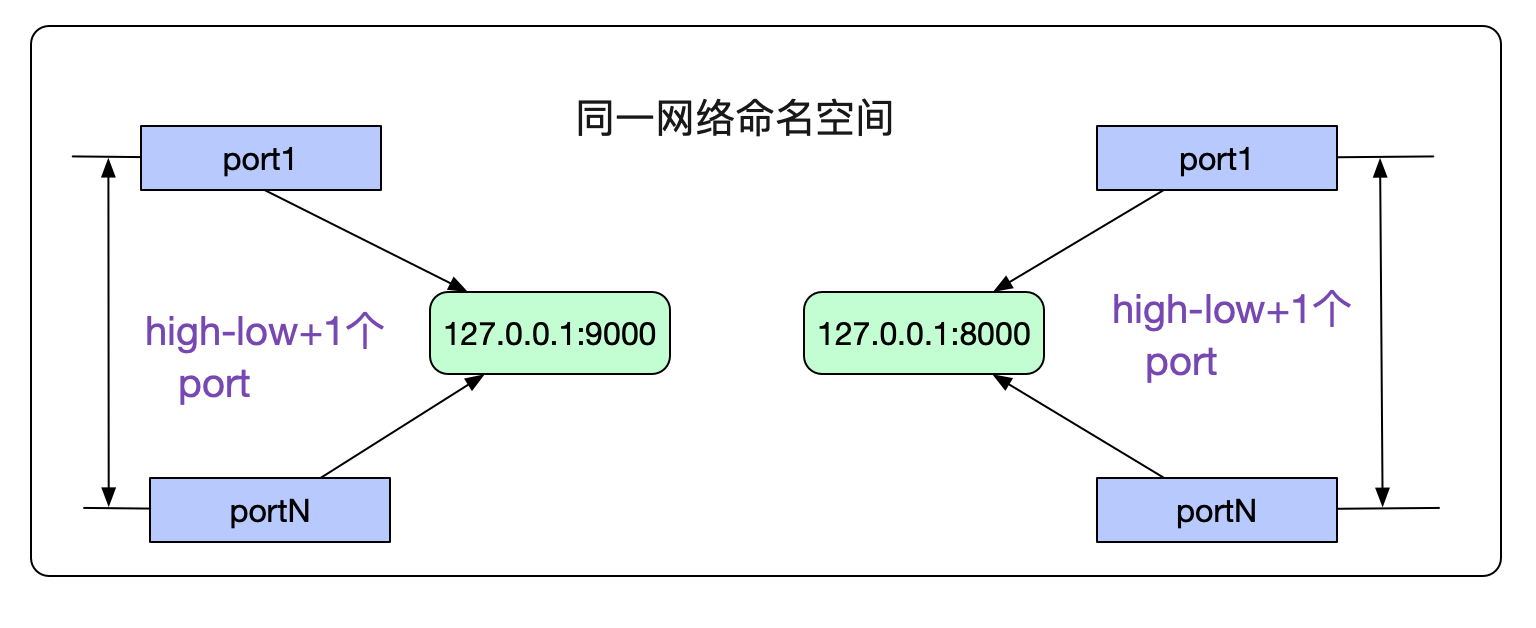
檢查端口號是否被佔用
端口號的佔用搜索分為兩個階段,一個是處於TIME_WAIT狀態的端口號搜索,另一個是其它狀態端口號搜索。
TIME_WAIT狀態端口號搜索
眾所周知,TIME_WAIT階段是TCP主動close必經的一個階段。如果Client採用短連接的方式和Server端進行交互,就會產生大量的TIME_WAIT狀態的Socket。而這些Socket由佔用端口號,所以當TIME_WAIT過多,打爆上面的端口號範圍之後,新的connect就會返回錯誤碼:
C語言connect返回錯誤碼為
-EADDRNOTAVAIL,對應描述為Cannot assign requested address
對應Java的異常為
java.net.NoRouteToHostException: Cannot assign requested address (Address not available)
ip_local_reserved_ports。如下圖所示:
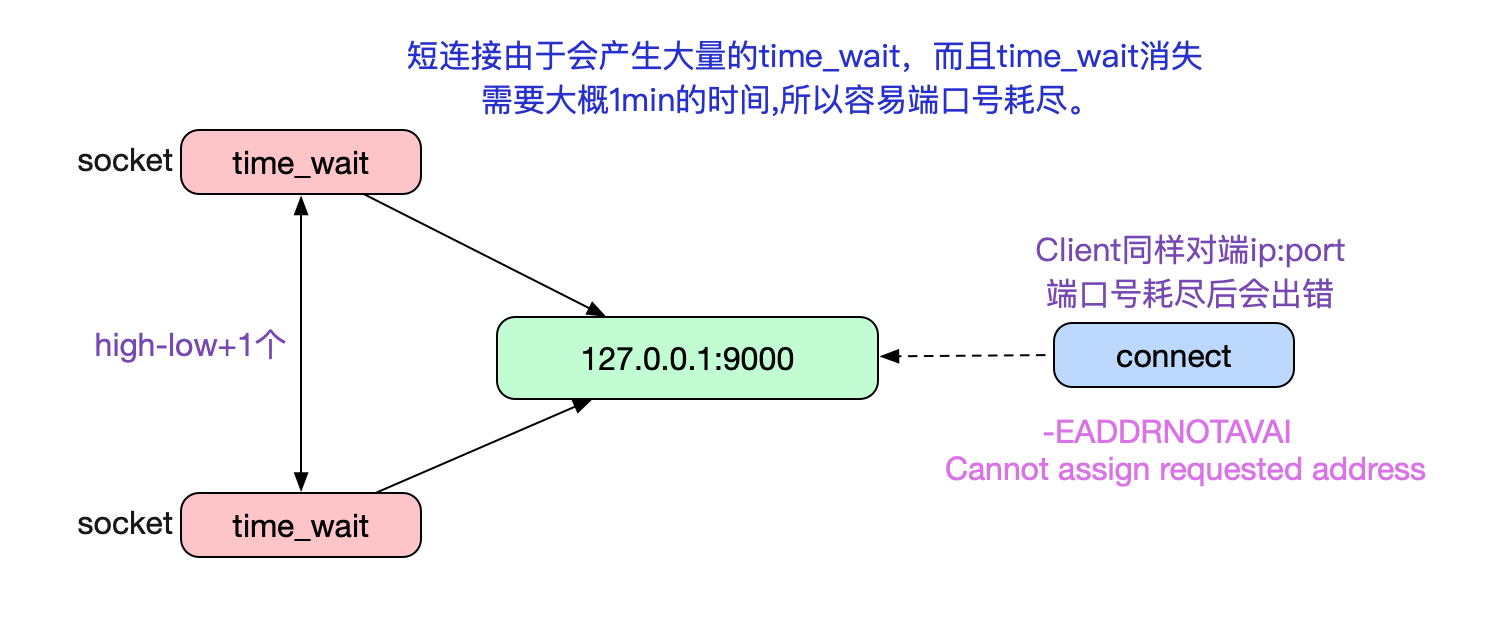
由於TIME_WAIT大概一分鐘左右才能消失,如果在一分鐘內Client端和Server建立大量的短連接請求就容易導致端口號耗盡。而這個一分鐘(TIME_WAIT的最大存活時間)是在內核(3.10)編譯階段就確定了的,無法通過內核參數調整。 如下代碼所示:
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT
* state, about 60 seconds */
Linux自然也考慮到了這種情況,所以提供了一個tcp_tw_reuse參數使得在搜索端口號時可以在某些情況下重用TIME_WAIT。代碼如下:
__inet_hash_connect
|->__inet_check_established
static int __inet_check_established(......)
{
......
/* Check TIME-WAIT sockets first. */
sk_nulls_for_each(sk2, node, &head->twchain) {
tw = inet_twsk(sk2);
// 如果在time_wait中找到一個match的port,就判斷是否可重用
if (INET_TW_MATCH(sk2, net, hash, acookie,
saddr, daddr, ports, dif)) {
if (twsk_unique(sk, sk2, twp))
goto unique;
else
goto not_unique;
}
}
......
}
如上面代碼中寫的那樣,如果在一堆TIME-WAIT狀態的Socket裏面能夠有當前要搜索的port,則判斷是否這個port可以重複利用。如果是TCP的話這個twsk_unique的實現函數是:
int tcp_twsk_unique(......)
{
......
if (tcptw->tw_ts_recent_stamp &&
(twp == NULL || (sysctl_tcp_tw_reuse &&
get_seconds() - tcptw->tw_ts_recent_stamp > 1))) {
tp->write_seq = tcptw->tw_snd_nxt + 65535 + 2
......
return 1;
}
return 0;
}
上面這段代碼邏輯如下所示:

在開啟了tcp_timestamp以及tcp_tw_reuse的情況下,在Connect搜索port時只要比之前用這個port的TIME_WAIT狀態的Socket記錄的最近時間戳>1s,就可以重用此port,即將之前的1分鐘縮短到1s。同時為了防止潛在的序列號衝突,直接將write_seq加上在65537,這樣,在單Socket傳輸速率小於80Mbit/s的情況下,不會造成序列號衝突。
同時這個tw_ts_recent_stamp設置的時機如下圖所示:
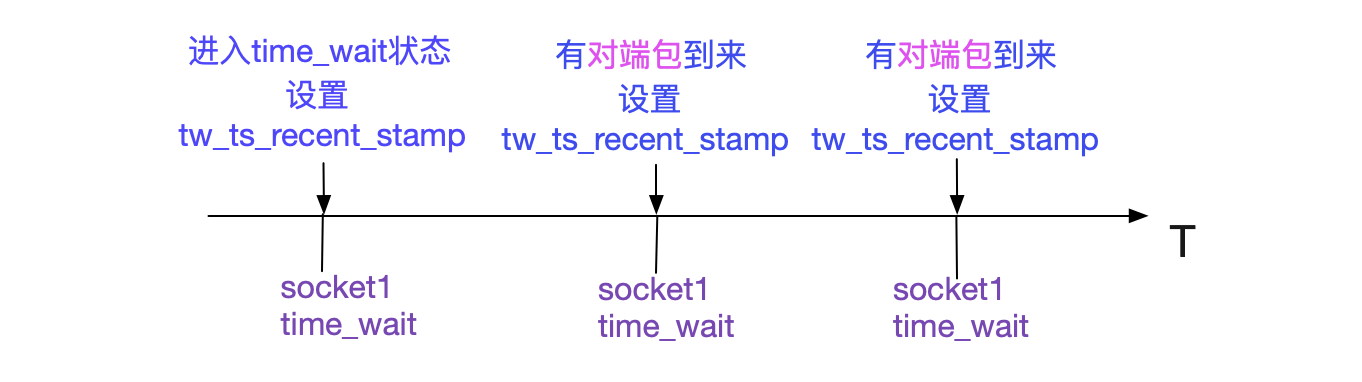
所以如果Socket進入TIME_WAIT狀態後,如果一直有對應的包發過來,那麼會影響此TIME_WAIT對應的port是否可用的時間。我們可以通過下面命令開始tcp_tw_reuse:
echo '1' > /proc/sys/net/ipv4/tcp_tw_reuse
ESTABLISHED狀態端口號搜索
ESTABLISHED的端口號搜索就簡單了許多
/* And established part... */
sk_nulls_for_each(sk2, node, &head->chain) {
if (INET_MATCH(sk2, net, hash, acookie,
saddr, daddr, ports, dif))
goto not_unique;
}
以(網絡命名空間,對端ip,對端port,本端port,Socket綁定的dev)當做唯一鍵進行匹配,如果匹配成功,表明此端口無法重用。
端口號迭代搜索
Linux內核在[low,high]範圍按照上述邏輯進行port的搜索,如果沒有搜索到port,即port耗盡,就會返回-EADDRNOTAVAIL,也即Cannot assign requested address。但還有一個細節,如果是重用TIME_WAIT狀態的Socket的端口的話,就會將對應的TIME_WAIT狀態的Socket給銷毀。
__inet_hash_connect(......)
{
......
if (tw) {
inet_twsk_deschedule(tw, death_row);
inet_twsk_put(tw);
}
......
}
尋找路由表
在我們找到一個可用端口號port後,就會進入搜尋路由階段:
ip_route_newports
|->ip_route_output_flow
|->__ip_route_output_key
|->ip_route_output_slow
|->fib_lookup
這也是一個非常複雜的過程,限於篇幅,就不做詳細闡述了。如果搜索不到路由信息的話,會返回。
-ENETUNREACH,對應描述為Network is unreachable
Client端的三次握手
在前面一大堆前置條件就緒後,才進入到真正的三次握手階段。
tcp_connect
|->tcp_connect_init 初始化tcp socket
|->tcp_transmit_skb 發送SYN包
|->inet_csk_reset_xmit_timer 設置SYN重傳定時器
tcp_connect_init初始化了一大堆TCP相關的設置,例如mss_cache/rcv_mss等一大堆。而且如果開啟了TCP窗口擴大選項的話,其窗口擴大因子也在此函數里進行計算:
tcp_connect_init
|->tcp_select_initial_window
int tcp_select_initial_window(...)
{
......
(*rcv_wscale) = 0;
if (wscale_ok) {
/* Set window scaling on max possible window
* See RFC1323 for an explanation of the limit to 14
*/
space = max_t(u32, sysctl_tcp_rmem[2], sysctl_rmem_max);
space = min_t(u32, space, *window_clamp);
while (space > 65535 && (*rcv_wscale) < 14) {
space >>= 1;
(*rcv_wscale)++;
}
}
......
}
如上面代碼所示,窗口擴大因子取決於Socket最大可允許的讀緩衝大小和window_clamp(最大允許滑動窗口大小,動態調整)。搞完了一票初始信息設置後,才開始真正的三次握手。
在tcp_transmit_skb中才真正發送SYN包,同時在緊接着的inet_csk_reset_xmit_timer里設置了SYN超時定時器。如果對端一直不發送SYN_ACK,將會返回-ETIMEDOUT。
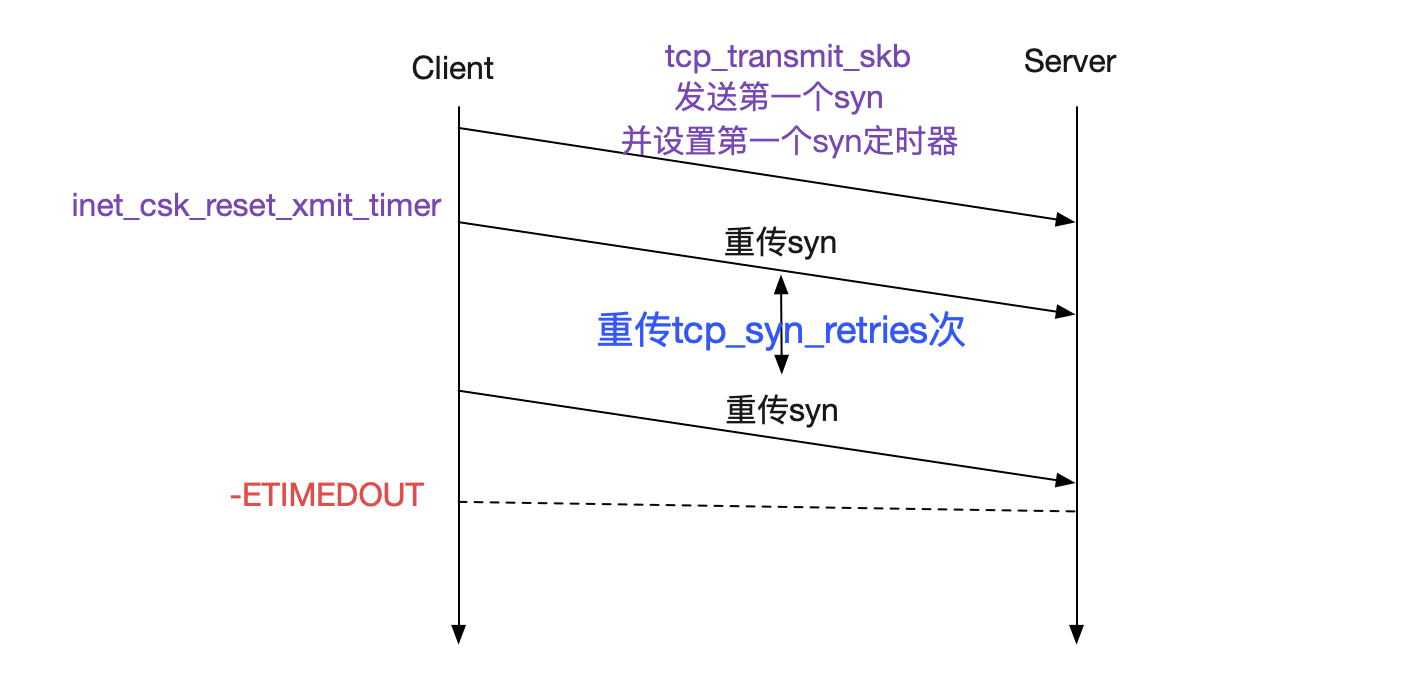
重傳的超時時間和
/proc/sys/net/ipv4/tcp_syn_retries
息息相關,Linux默認設置為5,建議設置成3,下面是不同設置的超時時間參照圖。
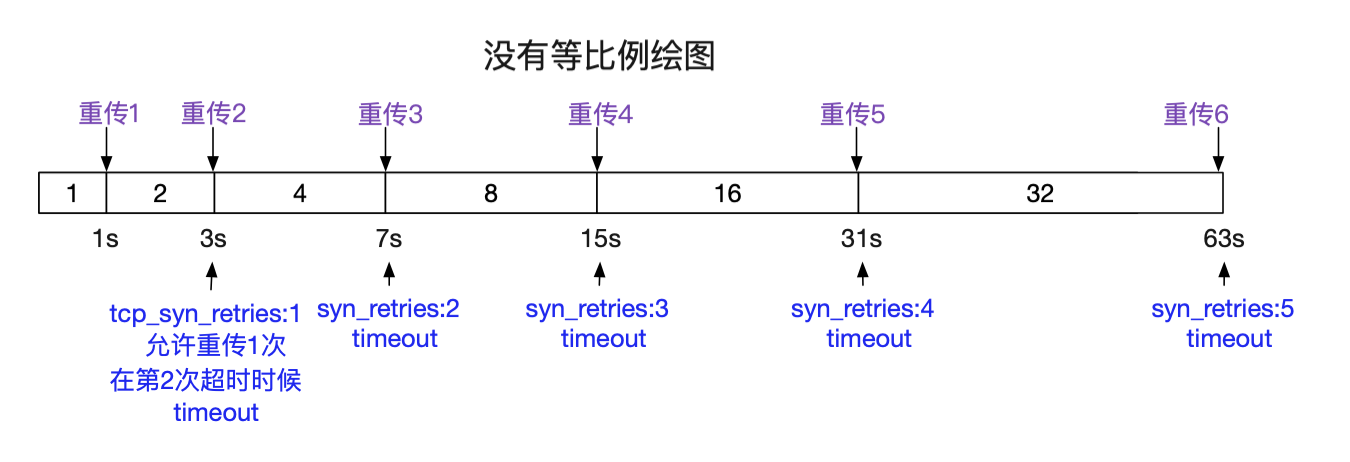
在設置了SYN超時重傳定時器後,tcp_connnect就返回,並一路返回到最初始的inet_stream_connect。在這裡我們就等待對端返回SYN_ACK或者SYN定時器超時。
int __inet_stream_connect(struct socket *sock,...,)
{
// 如果設置了O_NONBLOCK則timeo為0
timeo = sock_sndtimeo(sk, flags & O_NONBLOCK);
......
// 如果timeo=0即O_NONBLOCK會立刻返回
// 否則等待timeo時間
if (!timeo || !inet_wait_for_connect(sk, timeo, writebias))
goto out;
}
Linux本身提供一個SO_SNDTIMEO來控制對connect的超時,不過Java並沒有採用這個選項。而是採用別的方式進行connect的超時控制。僅僅就C語言的connect系統調用而言,不設置SO_SNDTIMEO,就會將對應用戶進程進行睡眠,直到SYN_ACK到達或者超時定時器超時才將次用戶進程喚醒。

如果是NON_BLOCK的話,則是通過select/epoll等多路復用機制去捕獲超時或者連接成功事件。
對端SYN_ACK到達
在Server端SYN_ACK到達之後會按照下面的代碼路徑傳遞,並喚醒用戶態進程:
tcp_v4_rcv
|->tcp_v4_do_rcv
|->tcp_rcv_state_process
|->tcp_rcv_synsent_state_process
|->tcp_finish_connect
|->tcp_init_metrics 初始化度量統計
|->tcp_init_congestion_control 初始化擁塞控制
|->tcp_init_buffer_space 初始化buffer空間
|->inet_csk_reset_keepalive_timer 開啟包活定時器
|->sk_state_change(sock_def_wakeup) 喚醒用戶態進程
|->tcp_send_ack 發送三次握手的最後一次握手給Server端
|->tcp_set_state(sk, TCP_ESTABLISHED) 設置為ESTABLISHED狀態
公眾號
關注筆者公眾號,獲取更多乾貨文章

總結
Client(TCP)端進行Connect的過程真是跋山涉水,從一開始文件描述符的限制到端口號的搜索再到路由表的搜索再到最後的三次握手,任何一個環節有問題就會導致創建連接失敗,筆者詳細的描述了這些機制的源碼實現。希望本篇文章可以對讀者在以後遇到Connect失敗問題時候有所幫助。


