偽分佈式Spark + Hive on Spark搭建
- 2019 年 10 月 3 日
- 筆記
Spark大數據平台有使用一段時間了,但大部分都是用於實驗而搭建起來用的,搭建過Spark完全分佈式,也搭建過用於測試的偽分佈式。現在是寫一遍隨筆,記錄一下曾經搭建過的環境,免得以後自己忘記了。也給和初學者以及曾經挖過坑的人用作參考。
Hive on Spark是Hive跑在Spark上,用的是Spark執行引擎,而不是默認的MapReduce。
可以查閱官網的資源Hive on Spark: Getting Started。
一 、安裝基礎環境
1.1 Java1.8環境搭建
1) 下載jdk1.8並解壓:
# tar -zxvf jdk-8u201-linux-i586.tar.gz -C /usr/local
2) 添加Java環境變量,在/etc/profile中添加:
export JAVA_HOME=/usr/local/jdk1.8.0_201 export PATH=$PATH:$JAVA_HOME/bin export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
3) 保存後刷新環境變量:
# source /etc/profile
4) 檢查Java是否配置成功,成功配置會有如下圖所示。
# java -version

1.2 Scala環境搭建
1)下載Scala安裝包並解壓
# tar -zxf scala-2.11.12.tgz -C /usr/local
2) 添加Scala環境變量,在/etc/profile中添加:
export SCALA_HOME=/usr/local/scala-2.11.12 export PATH=${SCALA_HOME}/bin:$PATH
3) 保存後刷新環境變量
# source /etc/profile
4) 檢查Scala是否配置成功,成功配置會有如下圖所示。
# scala -version

1.3 Maven安裝
1)下載安裝Maven
# tar -zxf apache-maven-3.6.1-bin.tar.gz -C /usr/local
2)添加到環境變量中
export MAVEN_HOME=/usr/local/maven-3.6.1 export PATH=$JAVA_HOME/bin:$MAVEN_HOME/bin:$PATH
3) 保存後刷新環境變量
# source /etc/profile
4)檢查Maven是否配置成功,成功配置會有如下圖所示
# mvn -version

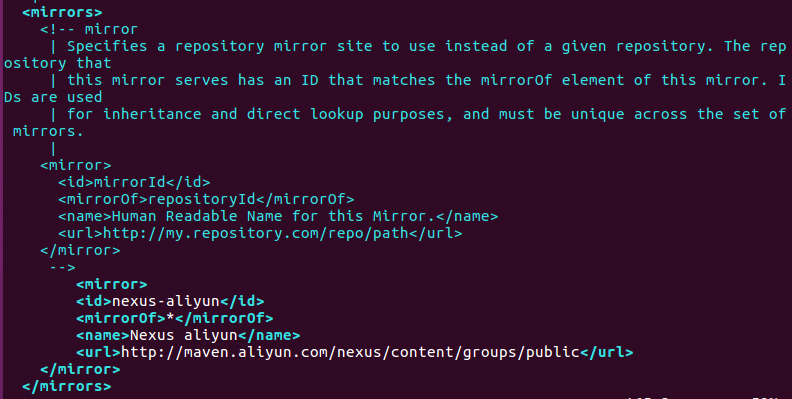
5)更換中央倉庫鏡像為阿里雲中央倉庫鏡像
# vim /usr/local/maven-3.6.1/conf/settings.xml
找到mirrors元素, 在它裏面添加子元素mirror:
<!-- 阿里雲中央倉庫 --> <mirror> <id>nexus-aliyun</id> <mirrorOf>*</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror>
添加結果如下:
二、Spark2.3.3源碼編譯
由官方文檔可知Hive on Spark只使用特定版本的Spark進行測試,所以給定版本的Hive只能保證使用特定版本的Spark。其他版本的Spark可能適用於給定版本的Hive,但這並不能保證。下面是Hive版本及其相應的兼容Spark版本的列表。

在本文中,小編搭建的版本為:Hive 3.1.1,Spark 2.3.3,在這裡默認Hive已經成功安裝好。
1)下載並解壓Spark源碼
# wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.3.3/spark-2.3.3.tgz # tar -zxf spark-2.3.3.tgz
2)編譯Spark源碼
下面是參考Spark官方文檔給出的教程而定製的命令,因為Spark要結合Hadoop(偽分佈式Hadoop部署可以參考我之前的文檔)與Hive一起使用,下面命令是Spark自帶的Maven編譯的腳本:
# ./dev/make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.7"
也可以直接通過Maven命令進行編譯:
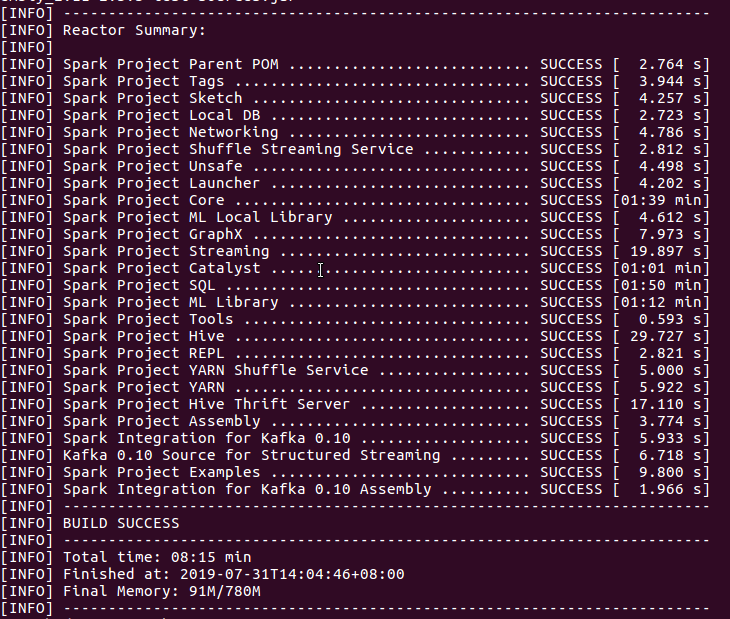
# ./build/mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.3 -DskipTests clean package
出現下圖所示也就代表着編譯成功:
將編譯後的Spark壓縮包解壓到/usr/local路徑並改名:
# tar -zxf spark-2.3.3-bin-hadoop2-without-hive.tgz -C /usr/local
# mv spark-2.3.3-bin-hadoop2-without-hive spark-2.3.3
3)配置偽分佈式Spark
配置SPARK_HOME環境變量後並刷新:
export SPARK_HOME=/usr/local/spark-2.3.3 export PATH=$PATH:$SPARK_HOME/bin
進入Spark根目錄下conf目錄並生成slaves文件:
# cd $SPARK_HOME/conf # cp slaves.template slaves //複製模板生成slaves文件,偽分佈式不用修改該文件
接下來修改spark-env.sh文件,修改前先複製後重命名:
# cp spark-env.sh.template spark-env.sh # vim spark-env.sh
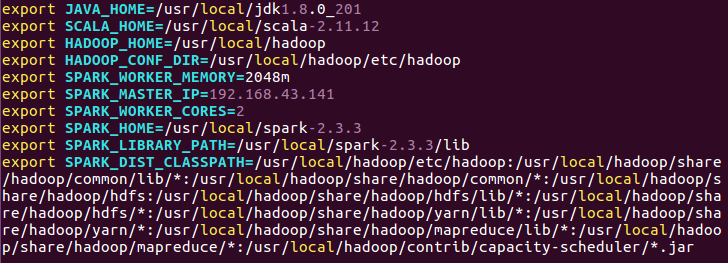
添加如下內容:
export JAVA_HOME=/usr/local/jdk1.8.0_201 export SCALA_HOME=/usr/local/scala-2.11.12 export HADOOP_HOME=/usr/local/hadoop export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop export SPARK_WORKER_MEMORY=2048m export SPARK_MASTER_IP=hadoop export SPARK_WORKER_CORES=2 export SPARK_HOME=/usr/local/spark-2.3.3 export SPARK_LIBRARY_PATH=/usr/local/spark-2.3.3/lib
export SPARK_DIST_CLASSPATH=${hadoop classpath} //hadoop classpath在終端上輸入即可查看
4)啟動Spark
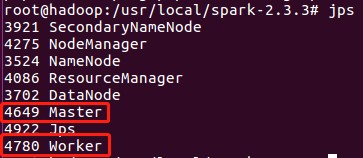
第一步,啟動之前要保證Hadoop啟動成功,先使用jps看下進程信息:
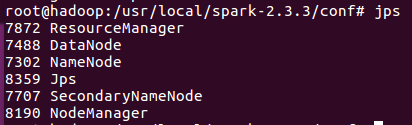
五個進程都啟動並沒有自動斷開,說明Hadoop啟動成功。
第二步,啟動Spark:
進入Spark的sbin目錄下執行start-all.sh啟動Spark,啟動後,通過jps查看最新的進程信息:
訪問http://ip:8080

從頁面可以看到一個Worker節點信息。
通過訪問http://ip:4040進入spark-shell web控制台頁面(需先使用命令./bin/spark-shell啟動SparkContext),出現下面的Web界面信息:

如果某台機器上運行多個SparkContext,它的Web端口會自動連續加一,例如4041,4042,4043等。為了瀏覽持久的事件日誌,設置spark.eventLog.enabled就可以了。
5)驗證Spark是否配置成功
注意:在啟動Spark之前,要確保Hadoop集群和YARN均已啟動
-
- 在$SPARK_HOME目錄下啟動Spark:
# $SPARK_HOME/sbin/start-all.sh
-
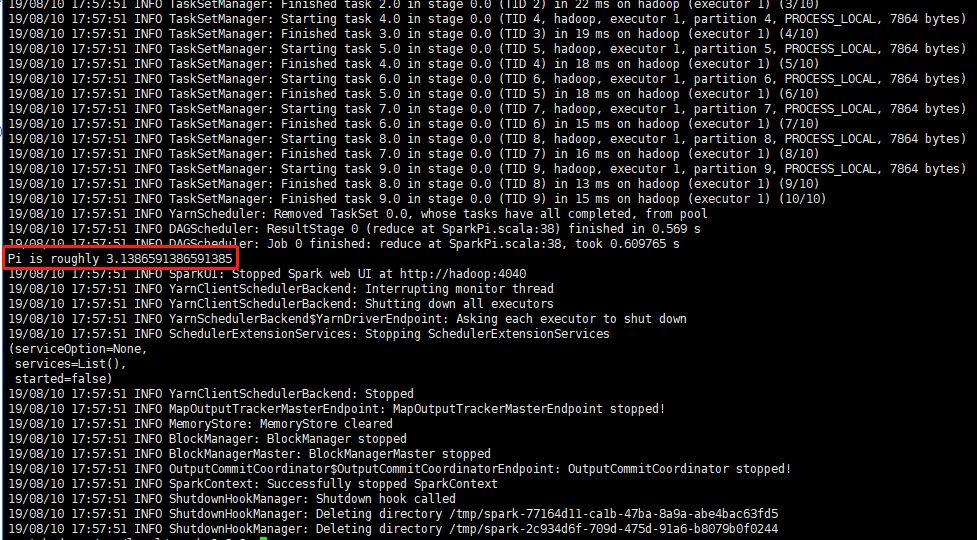
- 在$SPARK_HOME目錄下,提交計算Pi的任務,驗證Spark是否能正常工作,運行如下命令:
# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.3.3.jar 10
若無報錯,並且算出Pi的值,說明Spark集群能正常工作。
6)關閉Spark
進入Spark目錄,執行:
# cd $SPARK_HOME
# ./sbin/stop-all.sh
7)關閉Hadoop
進入Hadoop目錄,執行:
# cd $HADOOP_HOME # ./sbin/stop-yarn.sh # ./sbin/stop-dfs.sh
(./sbin/stop-all.sh也可以執行上述的操作,但有警告該命令已被丟棄,應使用上面的兩個命令代替)
三、Hive on Spark
1)將編譯好的Spark依賴添加到$HIVE_HOME/lib目錄下
# cp $SPARK_HOME/jars/* $HIVE_HOME/lib
2)配置hive-site.xml
配置的內容與spark-defaults.conf相同,只是形式不一樣,以下內容是追加到hive-site.xml文件中的,並且注意前兩個配置,如果不設置hive的spark引擎用不了,在後面會有詳細的錯誤說明。
<property> <name>hive.execution.engine</name> <value>spark</value> </property> <property> <name>hive.enable.spark.execution.engine</name> <value>true</value> </property>
<property> <name>spark.home</name> <value>/usr/local/spark-2.3.3</value> </property> <property> <name>spark.master</name> <value>yarn-client</value> </property> <property> <name>spark.eventLog.enabled</name> <value>true</value> </property> <property> <name>spark.eventLog.dir</name> <value>hdfs://hadoop:8020/spark-log</value> </property> <property> <name>spark.serializer</name> <value>org.apache.spark.serializer.KryoSerializer</value> </property> <property> <name>spark.executor.memeory</name> <value>1g</value> </property> <property> <name>spark.driver.memeory</name> <value>1g</value> </property> <property> <name>spark.executor.extraJavaOptions</name> <value>-XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"</value> </property>
3)驗證Hive on Spark是否可用
命令行輸入hive,進入hive CLI:

set hive.execution.engine=spark; (將執行引擎設為Spark,默認是mr,退出hive CLI後,會回滾到默認設置。若想讓執行引擎默認為Spark,需要在hive-site.xml里設置)
接下來執行一條創建測試表語句:
hive> create table test(ts BIGINT,line STRING);
然後執行一條查詢語句:
hive> select count(*) from test;

若上述整個過程都沒有報錯,並出現正確結果,則Hive on Spark搭建成功。
四、遇到的問題
1. get rid of POM not found warning for org.eclipse.m2e:lifecycle-mapping
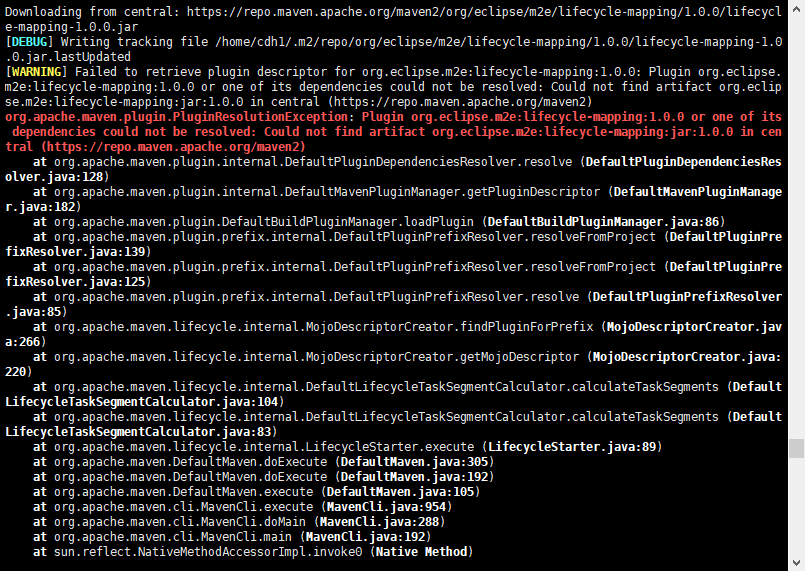
stackoverflow印度阿三們的解決方案已成功解決上述的問題:參考網址:https://stackoverflow.com/questions/7905501/get-rid-of-pom-not-found-warning-for-org-eclipse-m2elifecycle-mapping/
2. Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.2:testCompile
這報錯主要出現在Spark-SQL編譯出錯,原因在maven本地倉庫中scala依賴衝突,第一次編譯的時候沒有配置scala版本,默認用了2.10版本,這次是編譯成功的,但後面再編譯的時候,我選擇了2.11版本,然後在spark-sql模塊編譯失敗,然後去google找解決方案,鏈接如下所示: https://github.com/davidB/scala-maven-plugin/issues/215
通過以下命令刪除maven本地倉庫(默認路徑)的scala依賴:
# rm -r ~/.m2/repository/org/scala-lang/scala-reflect/2.1*
如果編譯還無法成功,則在源碼根目錄pom.xml文件添加依賴:
<dependency> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> </dependency>
3. Error: A JNI error has occurred, please check your installation and try again
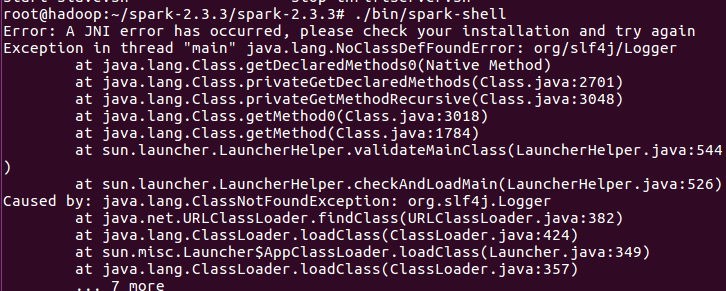
原因:啟動編譯好的Spark,出現如上的錯誤,是因為沒有在spark-env.sh導入hadoop classpath
解決方案:在shell終端上輸入hadoop classpath:

然後再spark-env.sh添加上去:

4. 啟動Hive時報錯,缺少spark-assembly-*.jar
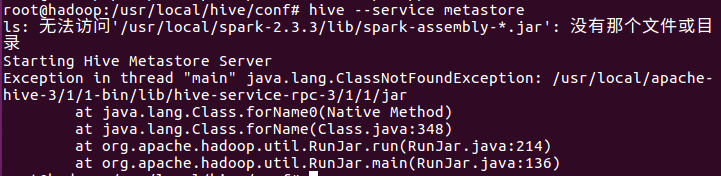
其主要的原因是:在hive.sh的文件中,發現了這樣的命令,原來初始當spark存在的時候,進行spark中相關的JAR包的加載。而自從spark升級到2.0.0之後,原有的lib的整個大JAR包已經被分散的小JAR包的替代,所以肯定沒有辦法找到這個spark-assembly的JAR包。這就是問題所在。

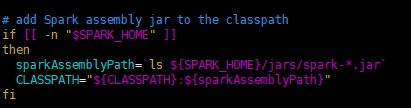
解決方案:將這個spark-assembly-*.jar`替換成jars/*.jar,就不會出現這樣的問題。
參考資料:http://spark.apache.org/docs/2.3.3/building-spark.html
https://www.cnblogs.com/xinfang520/p/7763328.html
https://blog.csdn.net/m0_37065162/article/details/81015096
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
