《The Design of a Practical System for Fault-Tolerant Virtual Machines》論文總結
VM-FT 論文總結
說明:本文為論文 《The Design of a Practical System for Fault-Tolerant Virtual Machines》 的個人總結,難免有理解不到位之處,歡迎交流與指正 。
論文地址:VM-FT 論文
本文的總結包括論文內容以及 MIT6.824 Lec4 中的授課內容,其中包含了論文中沒有提及的一些細節 。
1. 前言
本論文主要介紹了一個用於提供 容錯虛擬機 (fault-tolerant virtual machine) 的企業級商業系統,該系統包含了兩台位於不同物理機的虛擬機,其中一台為 primary ,另一台為 backup ,backup 備份了 primary 的所有執行 。當 primary 出現故障時,backup 可以上線接管 primary 的工作,以此來提供容錯 。
2. 主/備份方法
實現容錯服務器的一種常見方法是 主/備份方法 。backup 狀態與 primary 保持相同,primary 故障時,使用 backup 進行接管。並且以這種方式將故障對於 client 隱藏,不會丟失任何數據 。
主/備份方法中保持狀態同步的方法有以下兩種:
State transfer:primary 持續地將所有狀態( 包括 CPU、內存和 I/O 設備 )變化發送給 backup 。這種方法所需帶寬非常大 。Replicated state machine:將服務器抽象為確定性狀態機 。讓 primary 和 backup 按照相同的順序執接收相同的輸入請求,對於不確定的操作使用額外的協調來保證主備狀態一致 。這種方法實現複雜,但是所需帶寬較小 。本文便是採用這種方法 。
確定性狀態機:多台狀態機從相同的初始狀態開始、按照相同的順序執行相同的操作,則它們的最終狀態是一致的 。
狀態機方法允許 primary 和 backup 進行更大的物理分離 。
3. 虛擬機的選擇
虛擬機 ( virtual machine ) 不是通過硬件來啟動操作系統,而是在硬件之上會調用一個 Hypervisor ,Hypervisor 的工作實際上就是在硬件上模擬多個虛擬計算機 。Hypervisor 上執行着 GuestOS ,再上面是應用程序 。

Hypervisor 即 virtual machine monitor ( VMM )
GuestOS 即運行在虛擬機中的操作系統,與之對應的是 HostOS ,指物理機里的操作系統 。
在物理機上確保確定性執行是困難的,因為其會接收到很多不確定輸入( 如定時器中斷 ),因此可以採用虛擬機,Hypervisor 對硬件進行模擬和控制,可以捕獲到這些不確定輸入的所有相關信息,使得 backup 可以重放這些不確定輸入 。
因為我們討論的故障主要是指服務器故障,因此不同的虛擬機要位於不同的物理機上,否則便失去了容錯的意義 。
4. 基本設計
4.1 基本架構
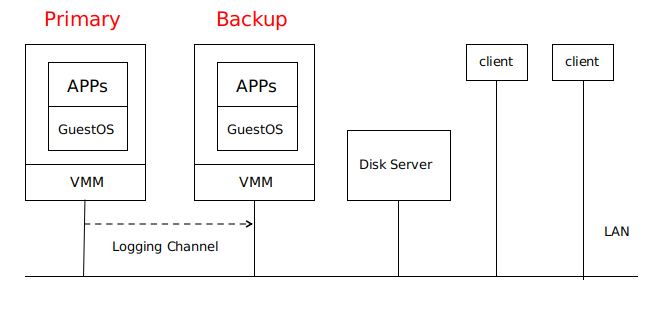
Primary VM 和 Backup VM 運行在同一網絡環境中的不同物理機上,兩者可以訪問同一個 Disk Server ,即論文當中的 Shared Disk 。
只有 Primary VM 向外界通知自己的存在,因此所有網絡輸入或其他輸入(磁盤、鼠標、鍵盤)都進入 Primary VM 。
Primary VM 接收的所有輸入都通一個稱為 Logging Channel 的網絡連接發送到 Backup VM ,以保證兩者狀態相同 。Backup VM 的指令執行結果與 Primary VM 的結果相同,但只有 Primary VM 返回給 client 結果,Backup VM 的結果會被 Hypervisor 丟棄 。
系統使用 Primary VM 和 Backup VM 之間的心跳包和 Logging Channel 上的流量監控來檢測 Primary VM 或 Backup VM 是否是失效 。此外,必須確保 Primary VM 和 Backup VM 中只有一個接管執行 。
事實證明,這些主備虛擬機並不適用於本地磁盤,而是會和某些磁盤服務器進行通信。( 論文中並未提到這點 )
4.2 確定性重放
由上文可知,VM-FT 建模為確定性狀態機的複製 。對於一系列輸入,對 primary 的執行進行記錄並確保 backup 以相同方式執行的基本技術稱為 確定性重放 。
primary 的操作中包含了 確定性操作 和 不確定性操作 。確定性操作在 primary 和 backup 上的執行結果是相同的,不確定性操作包括:
- 來自 client 的輸入,這些輸入可能在任何時候到達
- 非確定性指令,如隨機數生成指令、在不同時間獲得時間的指令、生成設備唯一 ID 的指令等
- 多核並發,服務中的指令會在不同的核上何以某種方式交錯執行,執行順序不可預測( 本論文中的方法只針對單核處理器,不解決此問題 )
前兩種不確定性操作會在 Logging Channel 中傳送
確定性重放記錄 primary 的輸入和 primary 執行相關的所有可能的不確定性,記錄在 log entry 流中,發送給 backup 並使其重放 :
- 對於不確定的操作,將記錄足夠的信息,確保其在 backup 上重新執行能夠得到相同的狀態和輸出
- 對於不確定的事件,如定時器或 IO 完成中斷,事件發生的確切指令會被記錄下來,重放時,backup 會在指令流中相同的位置重放這些事件
log entry 中應該包含了:
- 事件發生時的指令號
- 類型,指明是網絡輸入還是其他指令
- 數據:數據包里的數據,若是不確定指令,則此數據是該指令在 primary 的執行結果,所以 backup 就可以對該指令提供與 primary 相同的執行結果
不確定性指令執行過程:
( 即使 primary 和 backup 在同一狀態,執行不確定性指令後也會產生不同結果 )
primary:
- Hypervisor 在 primary 執行指令時設置中斷
- Hypervisor 執行指令並記錄結果
- 發送結果和指令序號到 backup
backup:
- Hypervisor 讀 log entry ,在該指令序號處設置中斷
- Hypervisor 應用從 primary 執行得到的結果,自己產生的結果被丟棄,從而保證主備一致
4.3 輸出要求和規則
輸出要求:若 primary 發生故障後且 backup 接管後,backup 必須以一種與原 primary 已發送到外部的輸出完全一致的方式運行 。
只要滿足了輸出要求,故障轉移就不會丟失外部可見的狀態或數據,client 也不會注意到 server 服務中斷或有不一致 。
可能有一種特殊情況會發生:如果 primary 在執行輸出操作後立即故障,backup 在完成接管之前,可能還未執行到同樣的輸出操作,就被其他不確定事件所影響( 如計時中斷 ),這樣 backup 就無法以與 primary 發生故障時的相同狀態上線,為此提出了 輸出規則 。
輸出規則:primary 必須延後將輸出發送到外部世界的動作,直到 backup 已經接收並確認 與產生該輸出的操作相關 的 log entry 。
基於輸出規則,primary 和 backup 的交互如下圖所示:
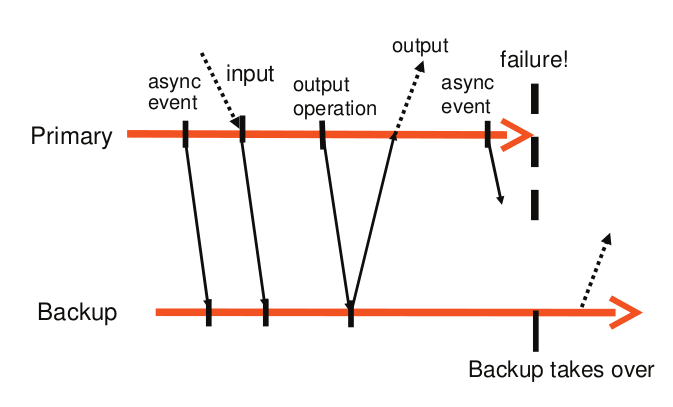
primary 等待來自 backup 的 ACK 時,不會停止執行,只需要延遲輸出的發送 ( 異步執行 )。
一些故障發生情況:
-
如果 primary 在收到 ACK 之前故障,它不會返回結果給 client ,由於 backup 的輸出會被丟棄,所以兩者在 client 看來是一致的,即未收到 server 回復 。
-
如果 primary 在發送輸出後故障,backup 在接管後也執行發送,client 會收到兩次輸出 。但是這種情況不會造成不良後果,因為對於 TCP 連接來說,它會處理重複的數據包;對於磁盤來說,會對同一塊存儲區覆蓋寫入 。
4.4 檢測和響應故障
兩種 VM 都有可能發生故障:
- 如果是 backup 故障,primary 將停止在 logging channel 上發送 log entry ,並繼續執行
- 如果是 primary 故障,backup 會繼續重放 log entries ,重放結束後 上線 成為 primary ,此時,它可以向外界生成輸出 。
VM-FT 檢測故障的方式有 UDP 心跳檢測和監控 logging channel 中的流量以及 backup 發送給 primary 的 ACK 。若心跳或日誌流量停止的時間超過了特定超時時間( 大約幾秒 ),就會聲明故障 。
這樣的故障檢測方法,在有網絡故障時,容易遇到 split-brain 問題:即 primary 和 backup 之間通信斷開,但此時 primary 還在運行,若 backup 此時上線,會造成兩者同時執行的問題,可能會導致數據損壞 。
為解決 split-brain 問題,使 Disk Server 支持 atomic test-and-set 測試,即在 Disk Server 上維護一個 flag ,第一個訪問此 flag 的 VM 會成為 primary ,第二個訪問此 flag 的 VM 不會上線 。( 類似於鎖 )
4.5 恢復冗餘
primary 發生故障,backup 上線時,在新的物理機上建立 backup ,恢復冗餘,繼續進入到容錯狀態 。
VM vSephere 實現了一個集群服務,用於維護管理和資源信息。當發生故障時,集群服務根據資源使用情況和其他約束來確定新的 backup 的最佳服務器,並將其複製成為 backup 。其結果是,VM-FT 通常可以在服務器發生故障後幾分鐘內重新建立冗餘,而在執行容錯轉移時不會產生任何明顯的中斷 。
4.6 管理日誌通道
Hypervisor 為 primary 和 backup 分別維護了一個 log buffer ,如下圖所示:
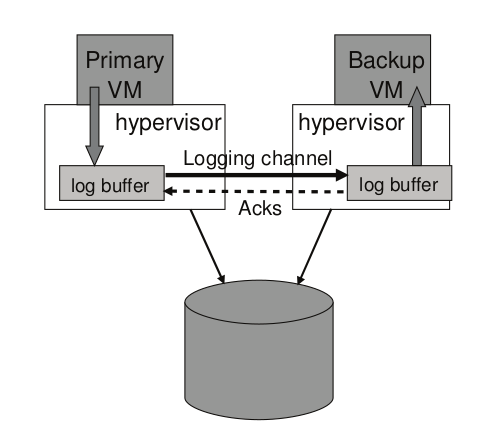
- primary 執行時,會將 log entry 生成到 log buffer 當中
- primary 的 log buffer 會儘快將內容清除到 logging channel
- log entry 一到達 logging channel 就會被讀到 backup 的 log buffer
- backup 發送 ACK 給 primary
若 primary 的 log buffer 已滿,primary 會等待;若 backup 的 log buffer 已空,backup 會等待 。
另外,為了防止 backup 的重放落後太多,在發送和確認 log entry 的協議中,會發送附加信息來確定 primary 和 backup 之間的 實時執行延遲 ,通常小於 100ms 。若 backup 出現明顯的延遲,VM-FT 會通知調度器給它分配更少的 CPU 資源,從而降低 primary 的速度;若 backup 追起來了,逐漸增加 primary 的速度 。
4.7 磁盤的內存訪問競爭
磁盤操作可能和 VM 中的應用程序或 OS 存在內存訪問競爭 。
這種競爭在網絡數據包或磁盤塊到達 primary 時產生 。在沒有 VM-FT 的情況下,相關硬件會通過 DMA 將該數據複製到內存中 。若 APP/OS 也在同時讀取這塊內存。那麼對於 primary 和 backup ,由於時間上的微小差異,可能一個在 DMA 之前讀取,一個在 DMA 之後讀取,就導致了不一致 。
解決方法是使用 bounce buffer ,它的大小與磁盤操作訪問的內存大小相同 。primary 的 Hypervisor 首先複製網絡數據或磁盤塊到 bounce buffer ,此時 primary 無法訪問它 ,Hyperbisor 中斷 primary 使其暫停執行,並記錄中斷的指令 。然後 Hypervisor 將 bounce buffer 中的內容複製到 primary 的內存 ,並讓其繼續執行 。通過 logging channel 將數據送到 backup 之後,backup 的 Hypervisor 在相同指令處中斷 backup ,將數據複製到 backup 的內存後,最後恢復 backup 的執行 。
5. 機器級複製和應用級複製
5.1 機器級複製
機器級複製 即複製了內存中和寄存器中的所有內容 。優點為可以在 VM-FT 上運行任何軟件;缺點為不夠高效
5.2 應用級複製
應用級複製 即 primary 僅發送 high-level 操作給 backup 。如數據庫,同步的狀態僅為數據庫內容,不是所有的內存內容,操作僅為數據庫命令( get 、put 之類 ),沒有網絡包或中斷 。GFS 使用的也是應用級複製 。
優點:更少的細粒度同步、更低的開銷
缺點:應用程序必須理解系統的容災
6. VM-FT 和 GFS 容錯的比較
VM-FT 備份的是 計算,可以用它為任何已有的網絡服務器提供容錯性。VM-FT 提供了相當嚴謹的一致性而且對 client 和 server 都是透明的。例如,你可以利用 VM-FT 為已有的郵件服務器提供容錯性。
相比之下,GFS 只為 存儲 提供容錯性。因為 GFS 只針對一種簡單的服務提供容錯性,它的備份策略會比 VM-FT 更為高效:例如,GFS 不需要使中斷髮生在所有的副本的同一指令上。GFS 通常只會被用作一個對外提供完整容錯服務的系統的一部分:例如,VM-FT 本身也依賴了一個在主備虛擬機間共享的有容錯性的存儲服務,而你則可以用類似於 GFS 的東西來實現這個模塊( 雖然從細節上來講 GFS 不太適用於 FT )。


