6.排序總結和優化
排序算法總結
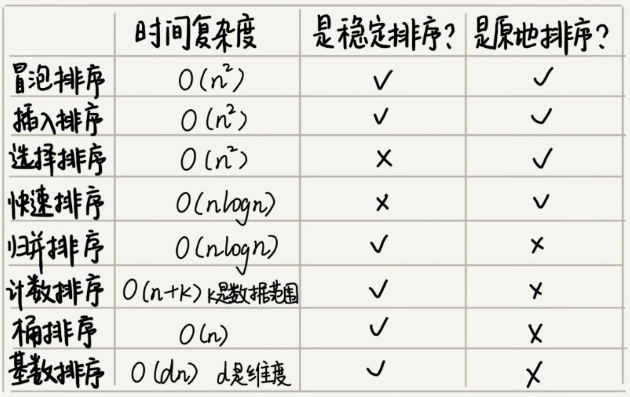
如何實現一個通用的排序算法
-
要知道時間複雜度只是描述一個增長趨勢,複雜度為O(n2)的排序算法執行時間不一定比複雜度為O(nlongn)長,因為在計算O時省略了係數、常數、低階。實際上,在對小規模數據進行排序時,n2的值實際比 knlogn+c還要小。
-
可優化的點
-
小數據規模時,可以優先使用歸併排序,在小規模時佔用的額外空間並不影響
-
數據量較大時,可以使用快排,快排在最壞情況下會退化為O(n**2),主要原因是因為分區點的選擇,分區點選擇優化思路如下
- 三數取中:從區間的頭、尾、中分別取一個數,將其中間值作為分區點。數據很多時可以「五數取中」、「十數取中」等等
- 隨機選擇:即從排序區間中隨機選擇一個數作為分區點。
-
數據量過多可以使用Timsort甚至計數排序
-
-
jdk1.8中Arrays.sort()實現
- n < 47 插入排序
- n < 286 雙軸快排
- 其他Timsort

