記一次線上商城系統高並發的優化
對於線上系統調優,它本身是個技術活,不僅需要很強的技術實戰能力,很強的問題定位,問題識別,問題排查能力,還需要很豐富的調優能力。
本篇文章從實戰角度,從問題識別,問題定位,問題分析,提出解決方案,實施解決方案,監控調優後的解決方案和調優後的觀察等角度來與大家一起交流分享本次線上高並發調優整個閉環過程。
一 項目簡要情況概述
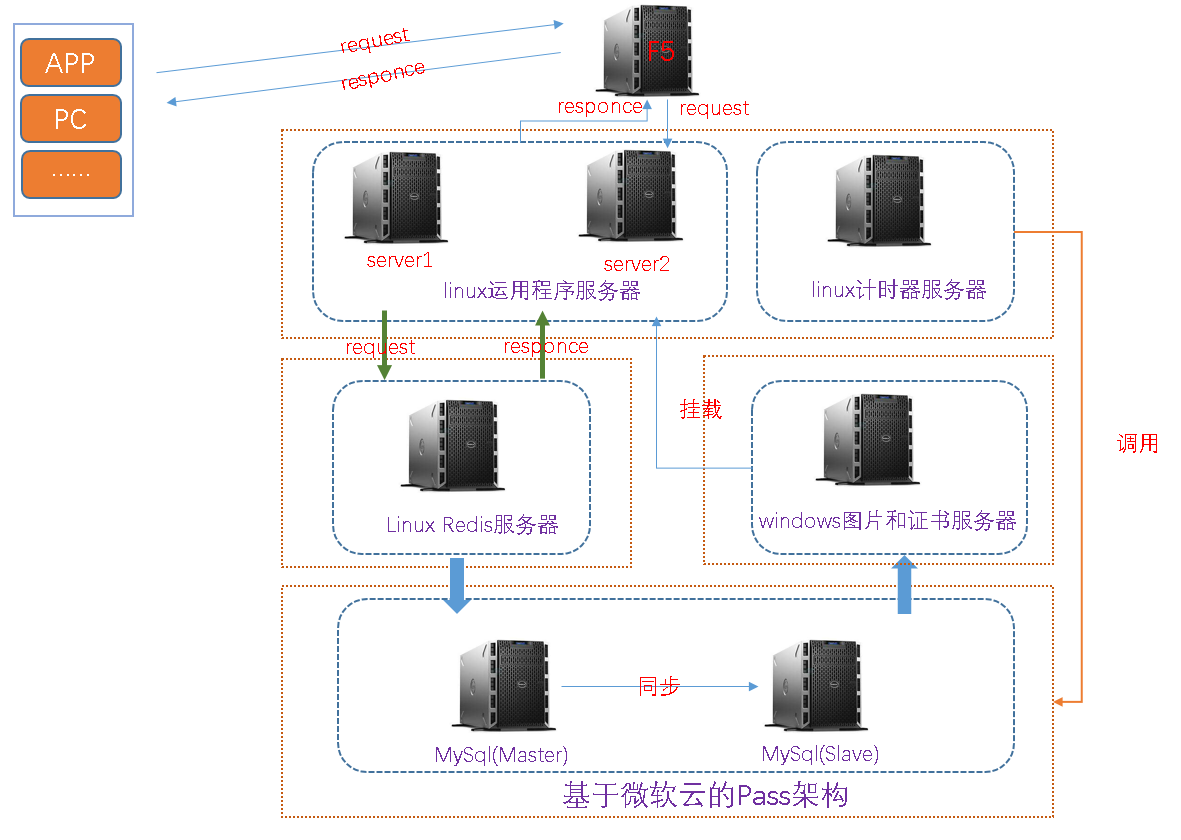
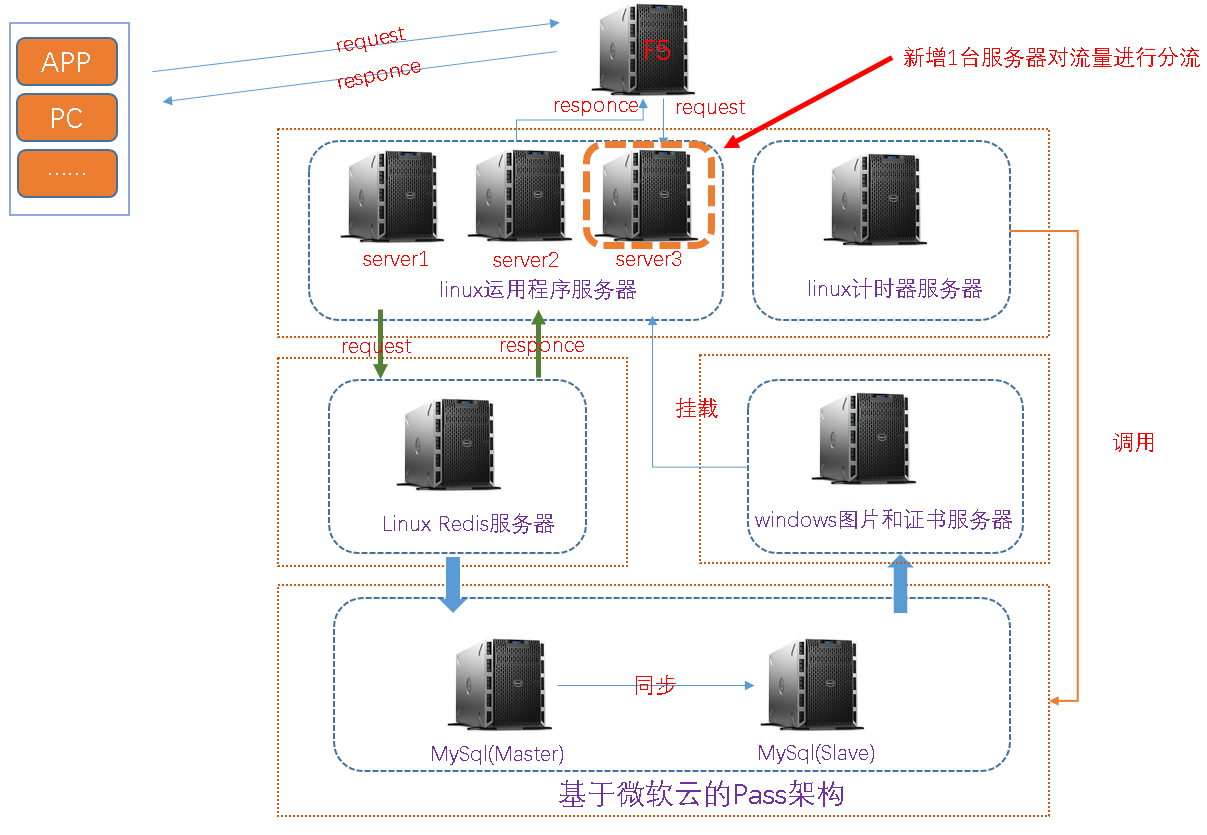
該項目為基於SSM架構的商城類單體架構項目,其中有一個秒殺重磅模塊,如下為當前線上環境的簡要架構部署圖,大致描述一下:
(1)項目為SSM架構
(2)服務器類別:1台負載均衡服務器(F5),3台運用程序服務器,1台計時器服務器,1台redis服務器,1台圖片服服務器和1台基於Pass架構的Mysql主從服務器(微軟雲)
(3)調用邏輯:下圖為簡要調用邏輯
二 何為單體架構項目
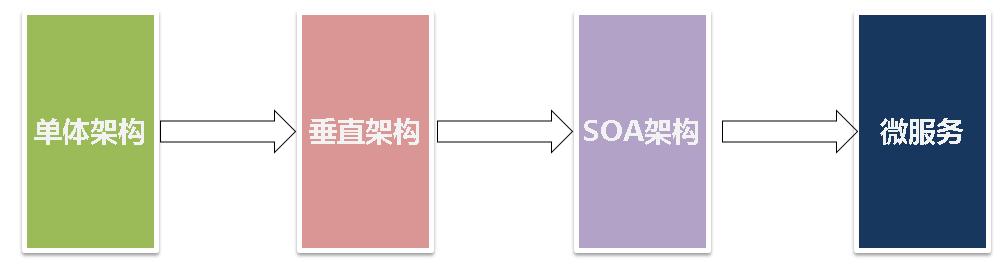
從架構發展角度,軟件項目經歷了如下階段的發展:
1.單體架構:可理解為傳統的前後端未分離的架構
2.垂直架構:可理解為前後端分離架構
3.SOA架構:可理解為按服務類別,業務流量,服務間依賴關係等服務化的架構,如以前的單體架構ERP項目,劃分為訂單服務,採購服務,物料服務和銷售服務等
4 微服務:可理解為一個個小型的項目,如之前的ERP大型項目,劃分為訂單服務(訂單項目),採購服務(採購項目),物料服務(物料項目)和銷售服務(銷售項目),以及服務之間調用
三 本SSM項目引發的線上問題
問題一:當秒殺的時候,cpu暴增。
該系統每天秒殺分為三個時間端:10點,13點和20點,如下為秒殺的簡要頁面
圖1
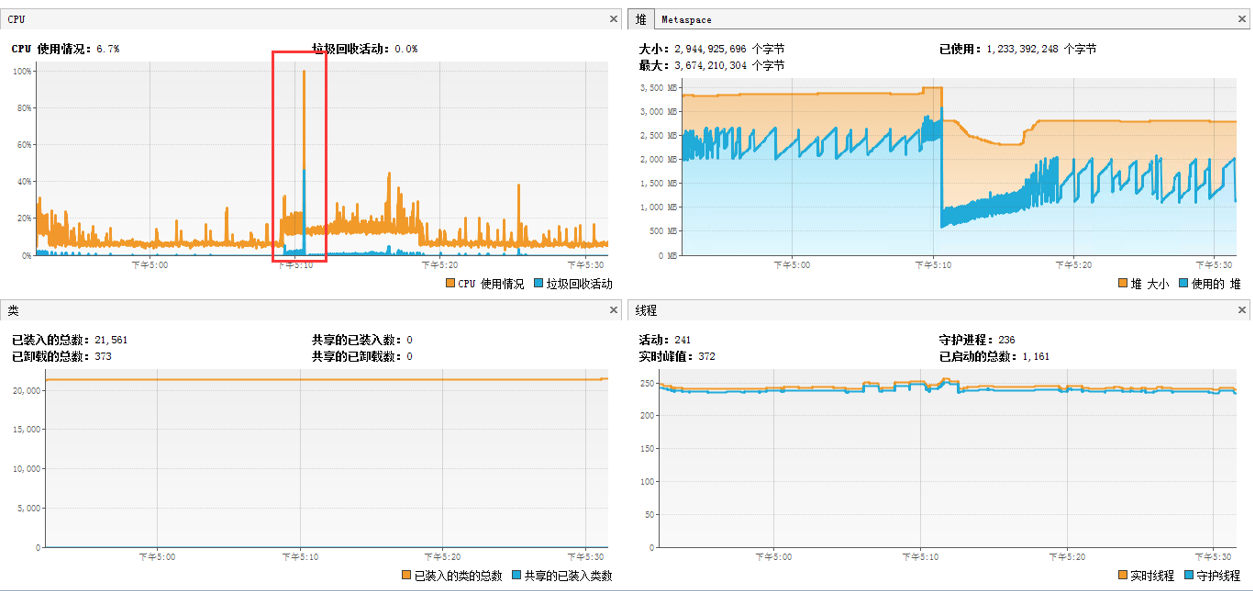
圖2
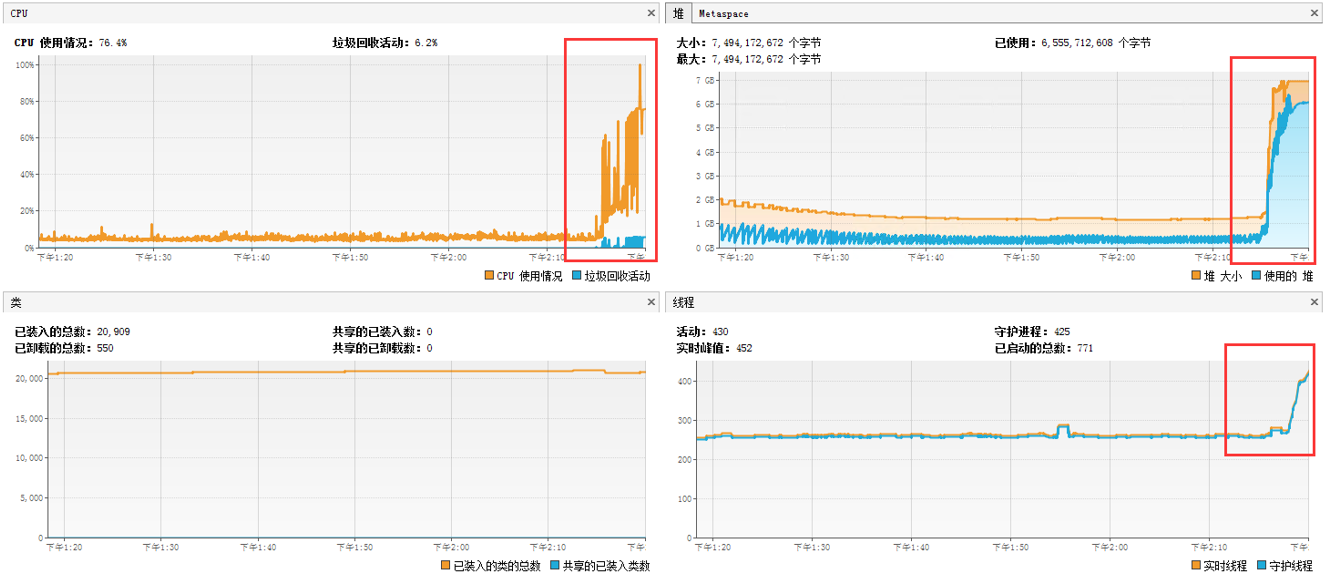
圖3
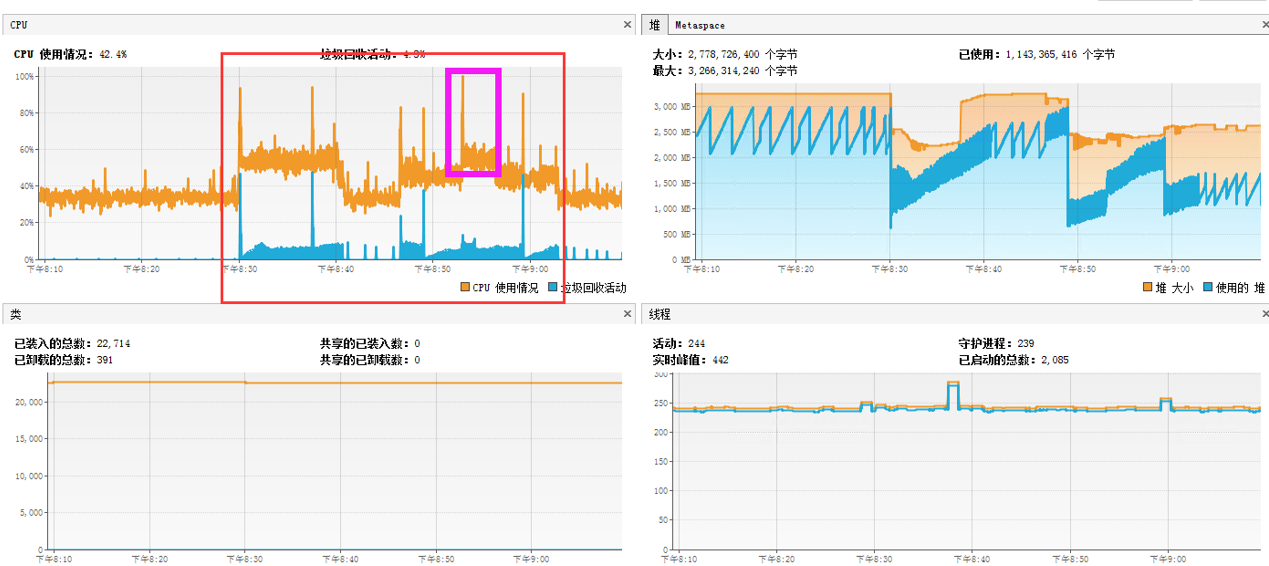
2.單台運用服務器cpu
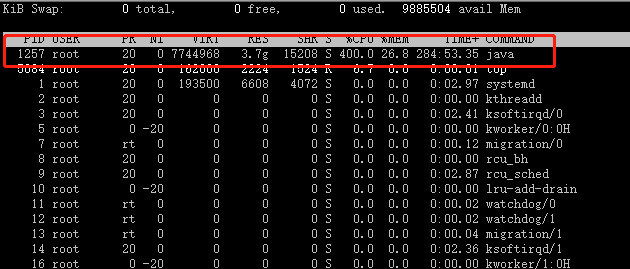
3.單台運用服務器請求數

4.rdis連接數(info clients)
這個未保存截圖,記得是600左右
connected_clients:600
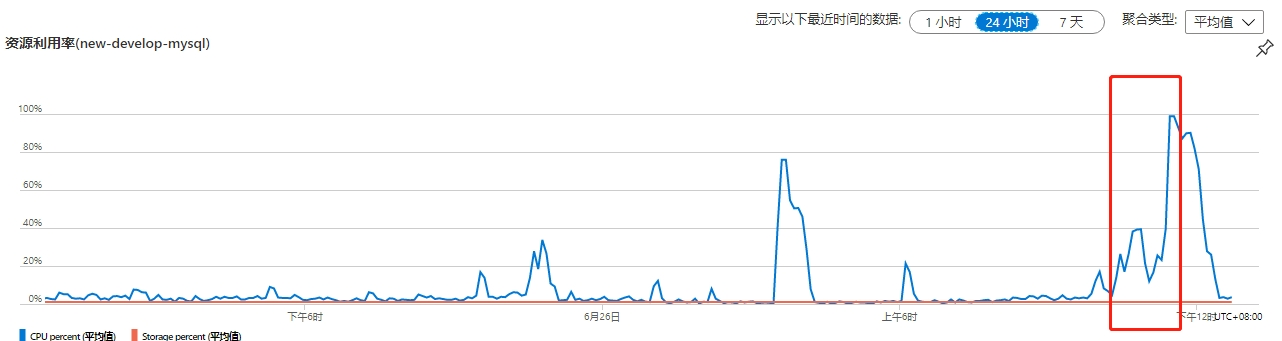
5.mysql請求截圖
四 排查過程及分析
(一)排查思路。
根據服務部署和項目架構,從如下幾個方面排查:
(1)運用服務器:排查內存,cpu,請求數等;
(2)文件圖片服務器:排查內存,cpu,請求數等;
(3)計時器服務器:排查內存,cpu,請求數等;
(4)redis服務器:排查內存,cpu,連接數等;
(5)db服務器:排查內存,cpu,連接數等;
(二)排查過程
在秒殺後30分鐘內,
1.運用程序服務器cpu暴增,內存暴增,造成cpu和內存暴增的根本原因是請求數過高,單台運用服務器達到3000多;
2.redis請求超時

3.jdbc連接超時

4.通過gc查看,發現24小時內,FullGC發生了152次

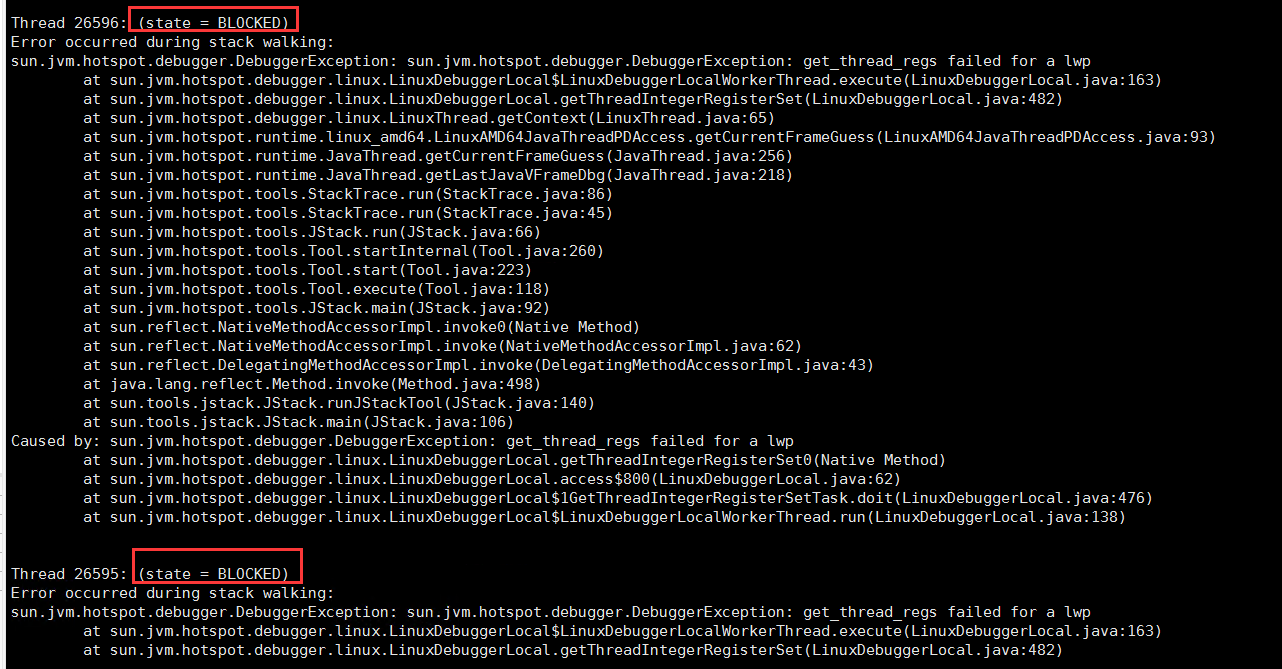
5.再看看堆棧,發現有一些線程阻塞和死鎖
jstat -l pid,也可以通過VisualVM分析
6.發現有2000多個線程請求無效資源
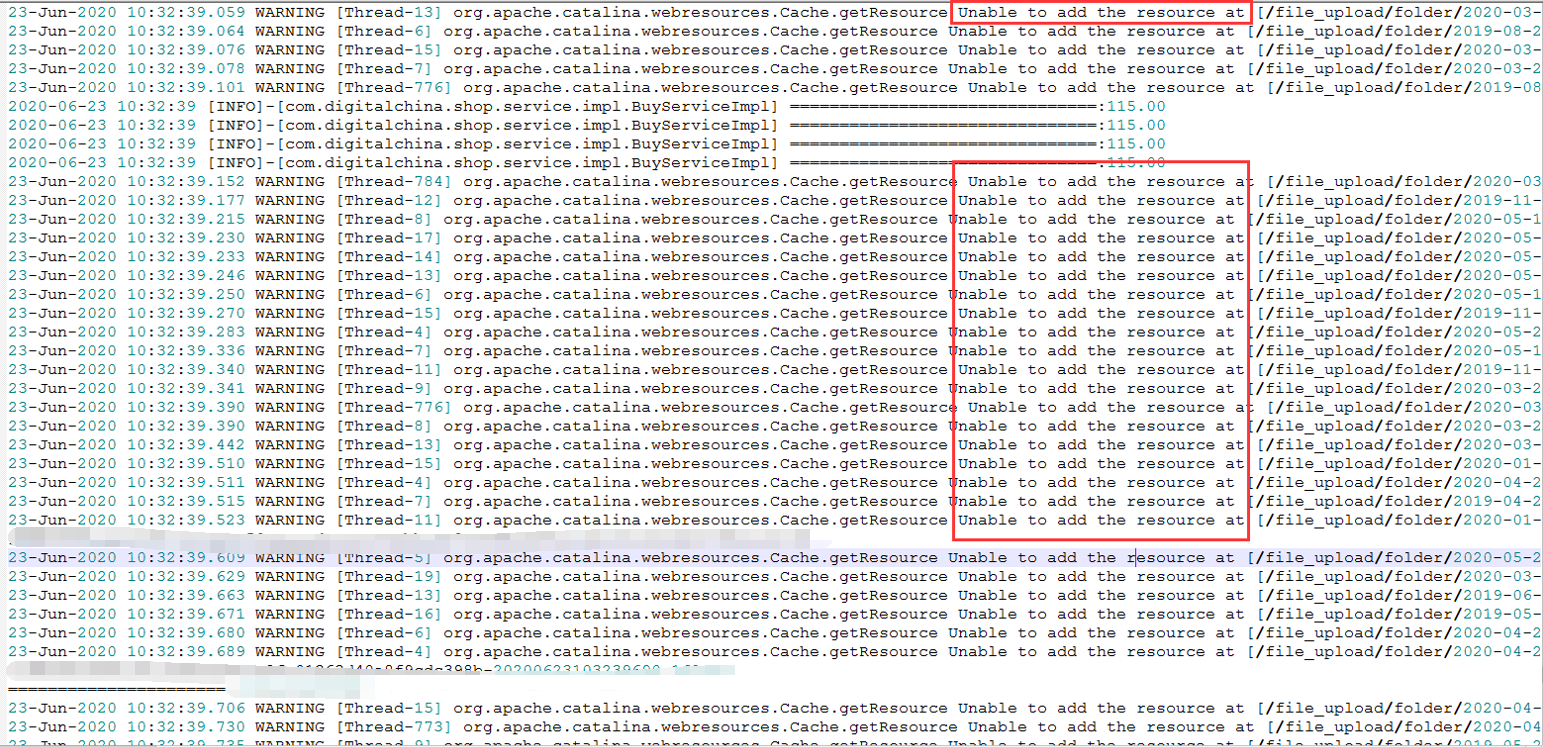
(三)造成本次系統異常主要因素分析
(1)在秒殺時,請求量過高,導致運用服務器負載過高;
(2)redis連接池滿,獲取不到連接,connot get a connection from thread pool
(3)jdbc連接池滿,獲取不到連接和超時
(4)存在大對象代碼,如向list集合中不停添加對象,不能及時回收對象導致內存增加,頻繁發生Full GC
(5)tomcat並發參數,jvm優化參數,jedis配置參數,jdbc配置參數不合理
(6)未對請求量進行削峰和限流
(7)資源連接未及時釋放,如redis連接,jdbc連接未及時釋放
五 最終解決方案
1.增加運用服務,做流量削峰和分流
由於該項目未增加MQ,因此只能採用硬負載,增加服務器水平擴展方式來實現流量削峰和流量分流
2.優化jvm參數,如下為本次優化後的參數
JAVA_OPTS=”-server -Xmx9g -Xms9g -Xmn3g -Xss500k -XX:+DisableExplicitGC -XX:MetaspaceSize=2048m -XX:MaxMetaspaceSize=2048m -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -Dfile.encoding=UTF8 -Duser.timezone=GMT+08″
關於這個jvm參數的優化,jvm理論是怎樣的,官方建議是怎樣的,實戰是怎樣的,將在下篇文章中分析。
3.優化tomcat並發相關參數
主要是兩方面:
(1)修改bio協議為nio2 (2)根據服務器配置,業務場景,業務流量等合理設置相關參數,盡量達到最優
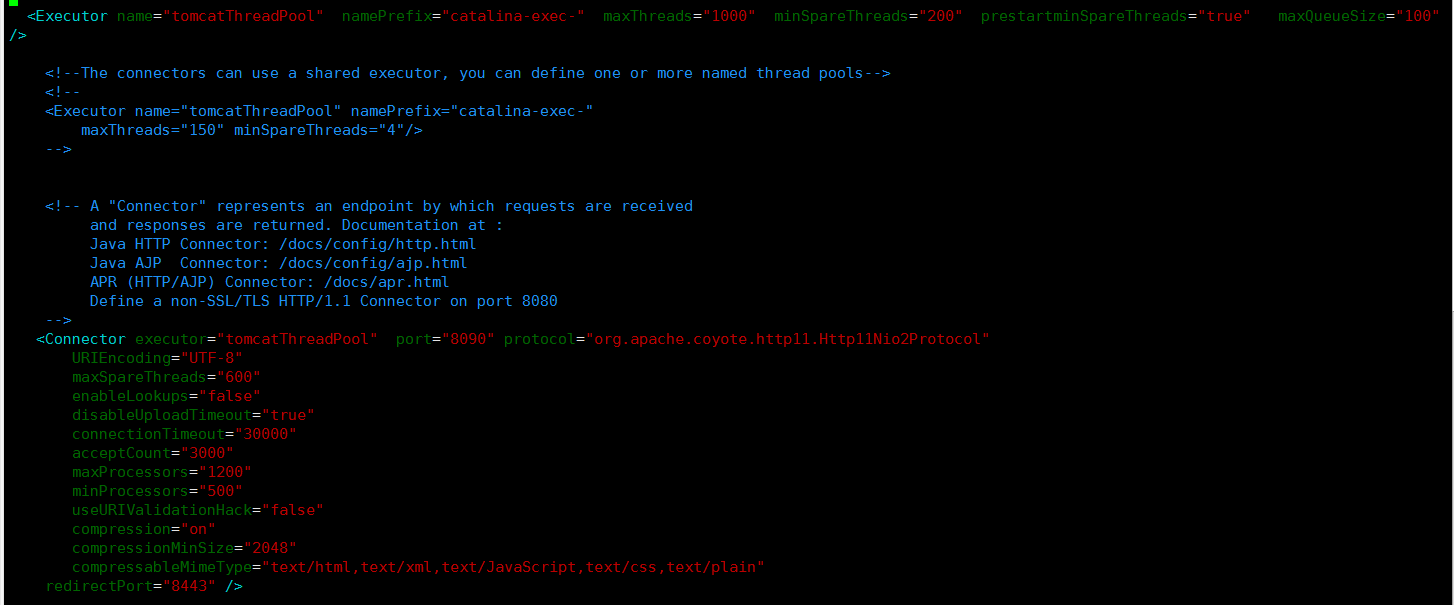
關於tomcat相關參數優化,在接下來的文章中分析。
4.redis 和jdbc參數優化
由於涉及到安全性問題,這裡不列出
5.代碼優化
(1)優化掉大對象
(2)優化未及時釋放的對象和連接資源
6.解決000多個線程請求無效資源問題
在conf/context.xml增大緩存
<Resource
cachingAllowed = “true”
cacheMaxSize = “102400”
/>
六 最終優化結果
經過幾天觀察,系統平穩
1.基本監控
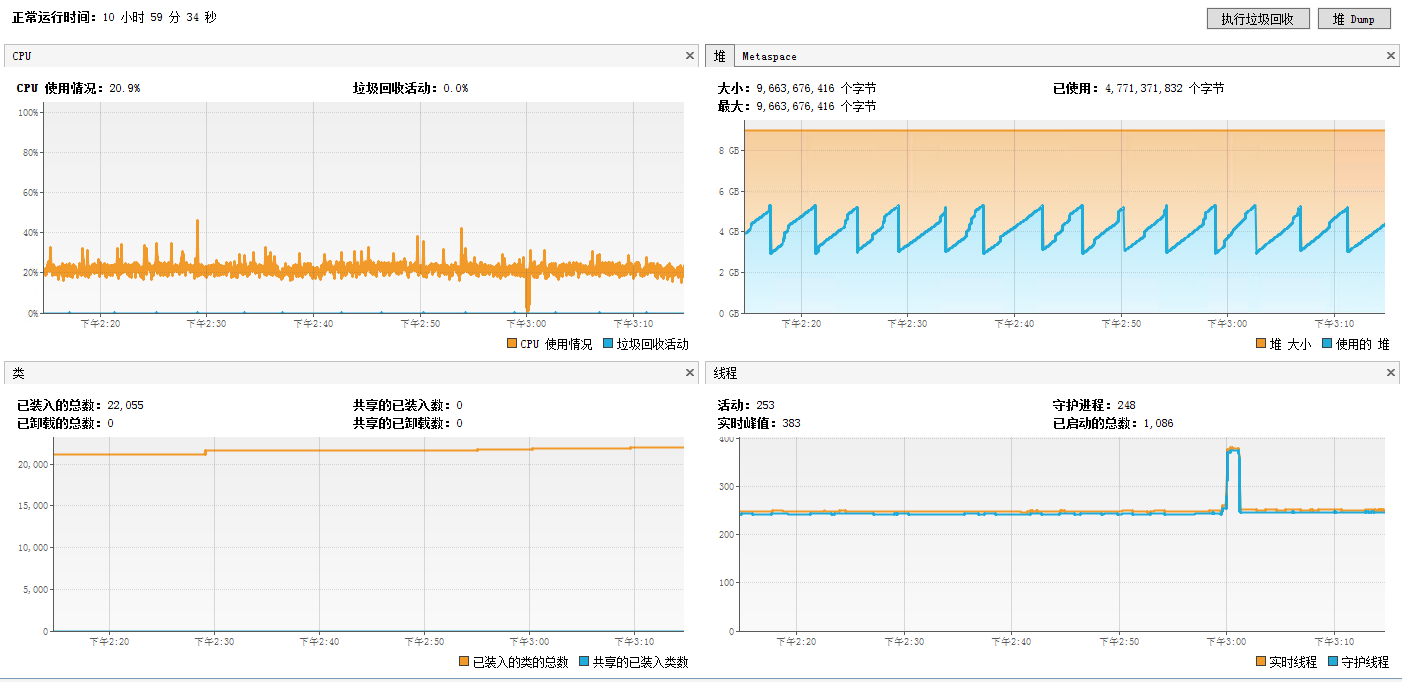
2.GC
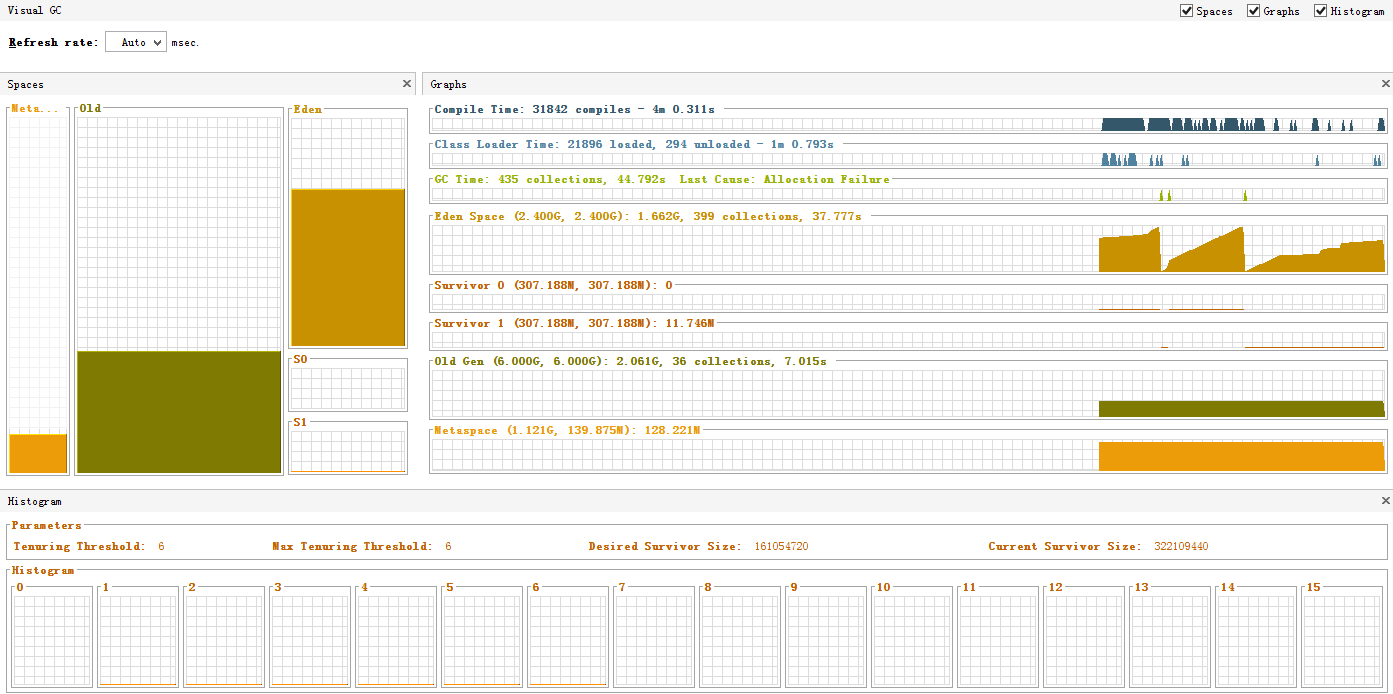
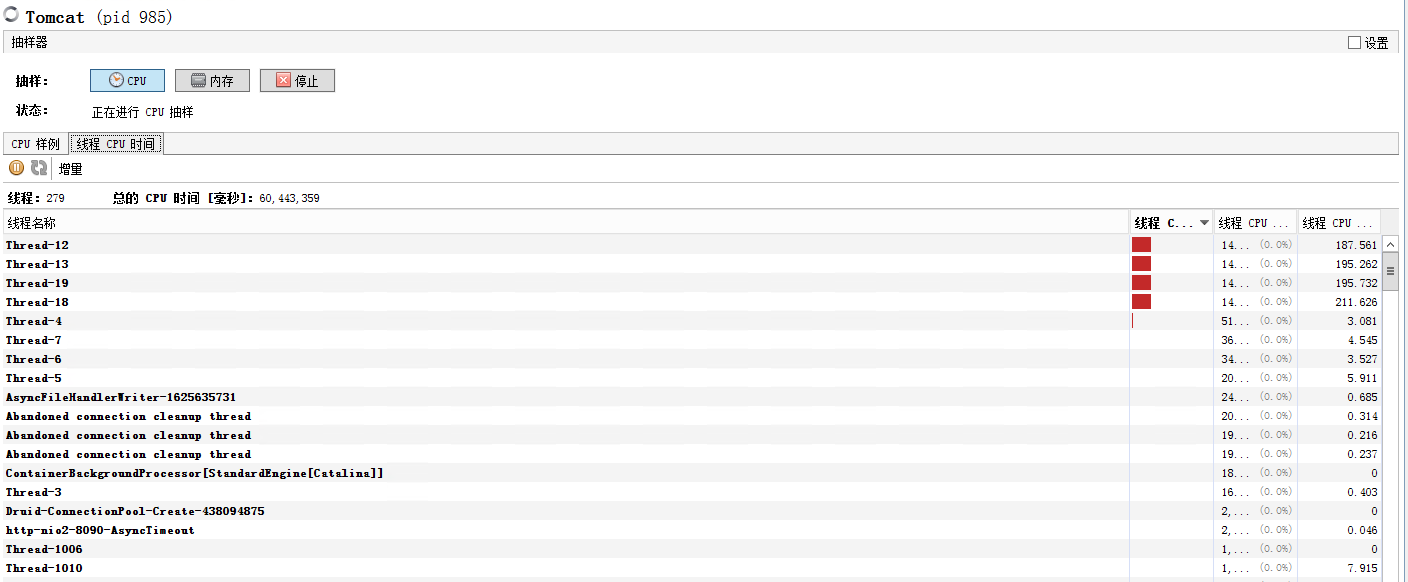
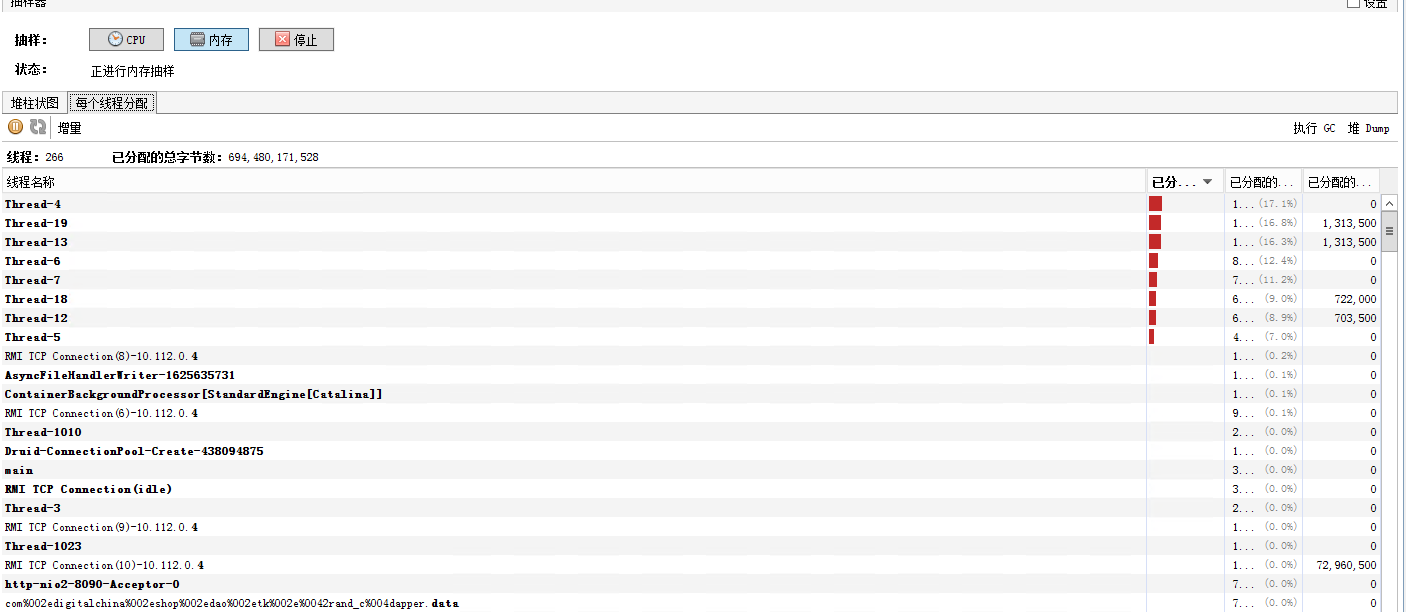
3.抽樣器cou和內存
cpu
內存
七 總結
1.本篇文章從實戰角度,從問題識別,問題定位,問題分析,提出解決方案,實施解決方案,監控調優後的解決方案和調優後的觀察等角度來與大家一起交流分享本次線上高並發調優整個閉環過程,當然,由於篇幅的限制,
有些細節和優化手段未在本篇文章中提及;
2.雖然解決了該問題,但是從長遠來看,該單體項目任然存在很大的問題和隱患,下面隨便舉幾個:
(1)前後端緊耦合,未分離
(2)由於該系統秒殺業務屬於非持續性並發,即局部性並發,當前並未做局部並發架構的調整
(3)由於該系統秒殺業務與該項目緊緊耦合在一起,未進行隔離,未獨立成單獨模塊,未單獨部署,從而存在因秒殺業務造成整個系統癱瘓的風險;
(4)未做流量削峰和流量限流,如加mq等軟手段;
(5)redis為做高可用集群
八 版權區
- 轉載博客,必須註明博客出處
- 博主網址://www.cnblogs.com/wangjiming/
- 如您有新想法,歡迎提出,郵箱:[email protected]
- 專業.NET之家技術QQ群:490539956
- 專業化Java之家QQ群:924412846
- 有問必答QQ群:2098469527
- 一對一技術輔導QQ:2098469527


