十、深度優先 && 廣度優先
一、什麼是「搜索」算法?
- 算法是作用於具體數據結構之上的,深度優先搜索算法和廣度優先搜索算法都是基於「圖」這種數據結構的。
- 因為圖這種數據結構的表達能力很強,大部分涉及搜索的場景都可以抽象成「圖」。
- 圖上的搜索算法,最直接的理解就是,在圖中找出從一個頂點出發,到另一個頂點的路徑。
- 具體方法有很多,兩種最簡單、最「暴力」的方法為深度優先、廣度優先搜索,還有A、 IDA等啟發式搜索算法。
- 圖有兩種主要存儲方法,鄰接表和鄰接矩陣。
- 以無向圖,採用鄰接表存儲為例:
public class Graph {
// 頂點的個數
private int v;
// 每個頂點後面有個鏈表
private LinkedList<Integer>[] adj;
public Graph(int v) {
this.v = v;
adj = new LinkedList[v];
for (int i = 0; i < v; i++) {
adj[i] = new LinkedList<>();
}
}
/**
* 添加邊
* @param s 頂點
* @param t 頂點
*/
public void addEdge(int s,int t){
// 無向圖一條邊存兩次(聯想微信好友)
adj[s].add(t);
adj[t].add(s);
}
}
二、廣度優先搜索(BFS)
- 廣度優先搜索(Breadth-First-Search),簡稱為 BFS。
- 它是一種「地毯式」層層推進的搜索策略,即先查找離起始頂點最近的,然後是次近的,依次往外搜索。
-
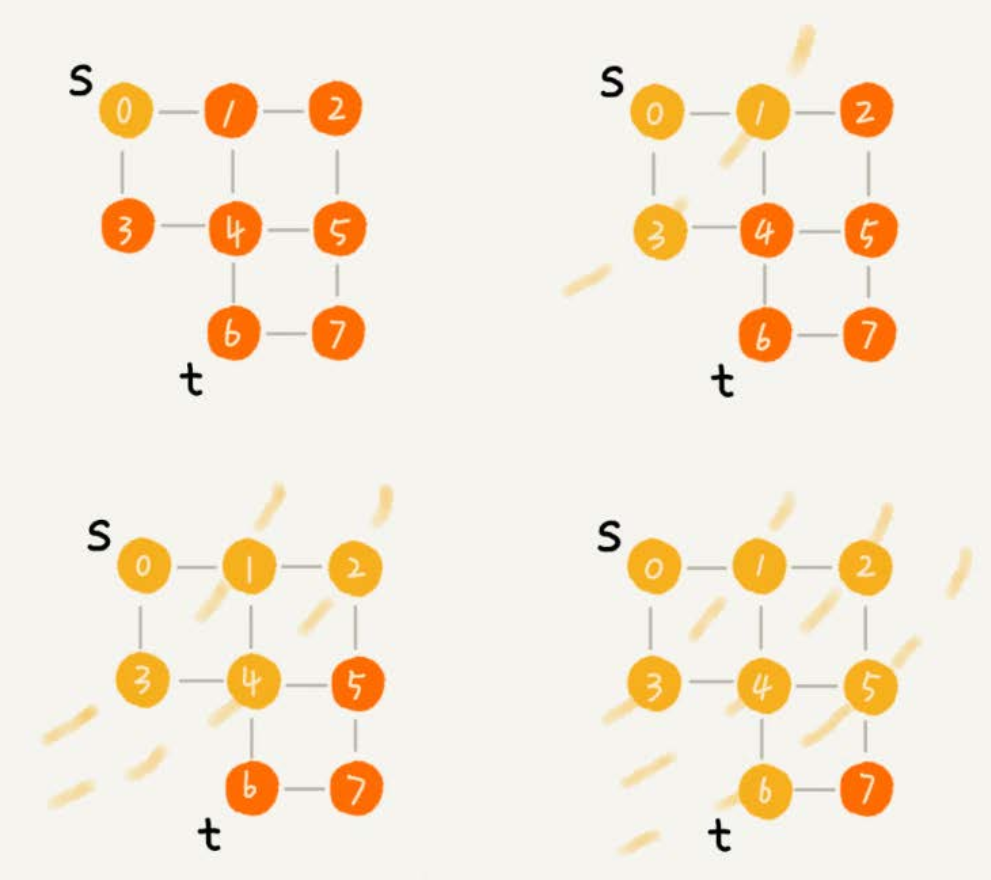

2.1、實現過程
/**
* 圖的廣度優先搜索,搜索一條從 s 到 t 的路徑。
* 這樣求得的路徑就是從 s 到 t 的最短路徑。
*
* @param s 起始頂點
* @param t 終止頂點
*/
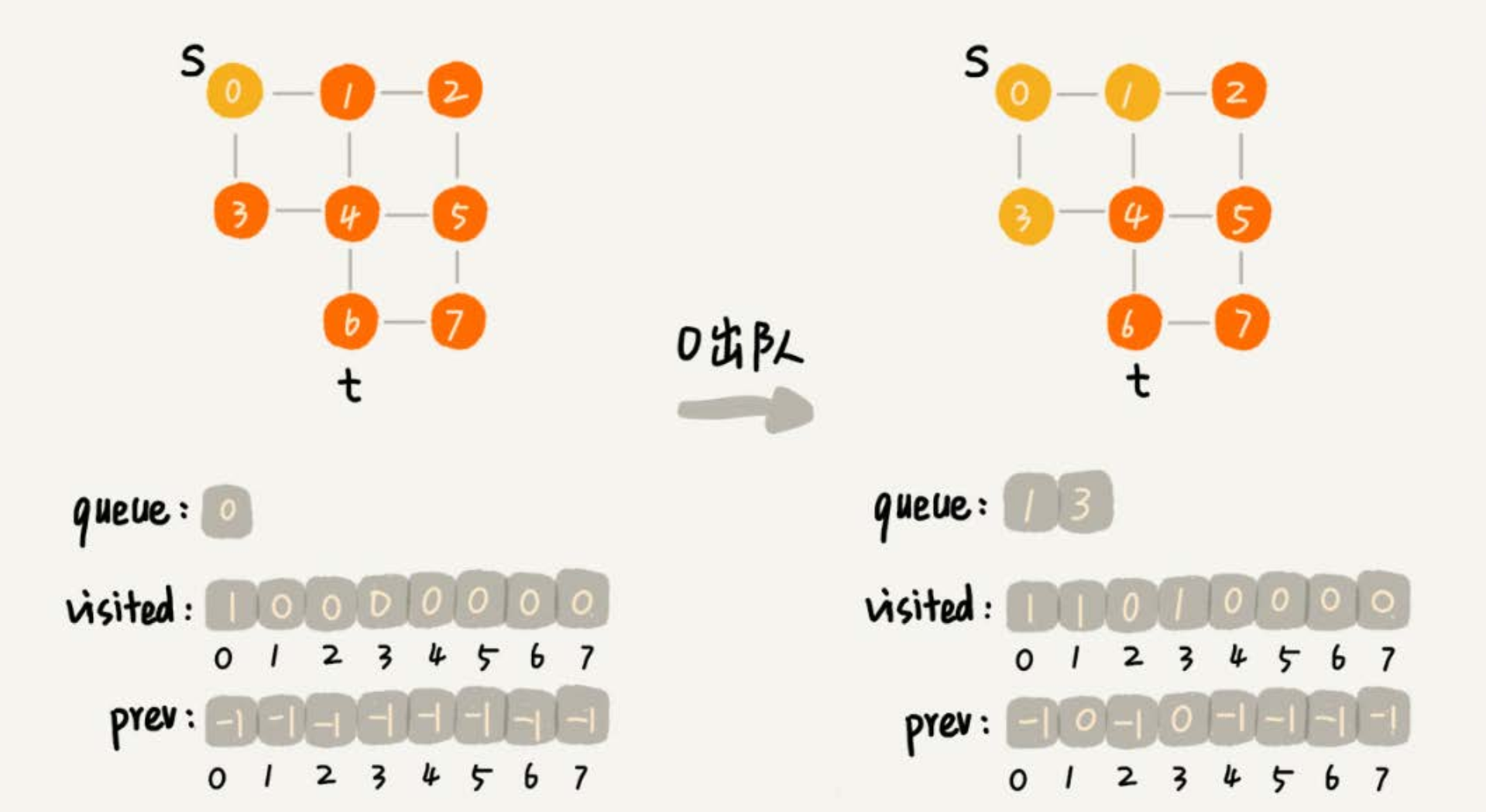
public void bfs(int s, int t) {
if (s == t) {
return;
}
// visited 記錄已經被訪問的頂點,避免頂點被重複訪問。如果頂點 q 被訪問,那相應的visited[q]會被設置為true。
boolean[] visited = new boolean[v];
visited[s] = true;
// queue 是一個隊列,用來存儲已經被訪問、但相連的頂點還沒有被訪問的頂點。因為廣度優先搜索是逐層訪問的,只有把第k層的頂點都訪問完成之後,才能訪問第k+1層的頂點。
// 當訪問到第k層的頂點的時候,需要把第k層的頂點記錄下來,稍後才能通過第k層的頂點來找第k+1層的頂點。
// 所以,用這個隊列來實現記錄的功能。
Queue<Integer> queue = new LinkedList<>();
queue.add(s);
// prev 用來記錄搜索路徑。當從頂點s開始,廣度優先搜索到頂點t後,prev數組中存儲的就是搜索的路徑。
// 不過,這個路徑是反向存儲的。prev[w]存儲的是,頂點w是從哪個前驅頂點遍歷過來的。
// 比如,通過頂點2的鄰接表訪問到頂點3,那prev[3]就等於2。為了正向打印出路徑,需要遞歸地來打印,就是print()函數的實現方式。
int[] prev = Arrays.stream(new int[v]).map(f -> -1).toArray();
while (queue.size() != 0) {
int w = queue.poll();
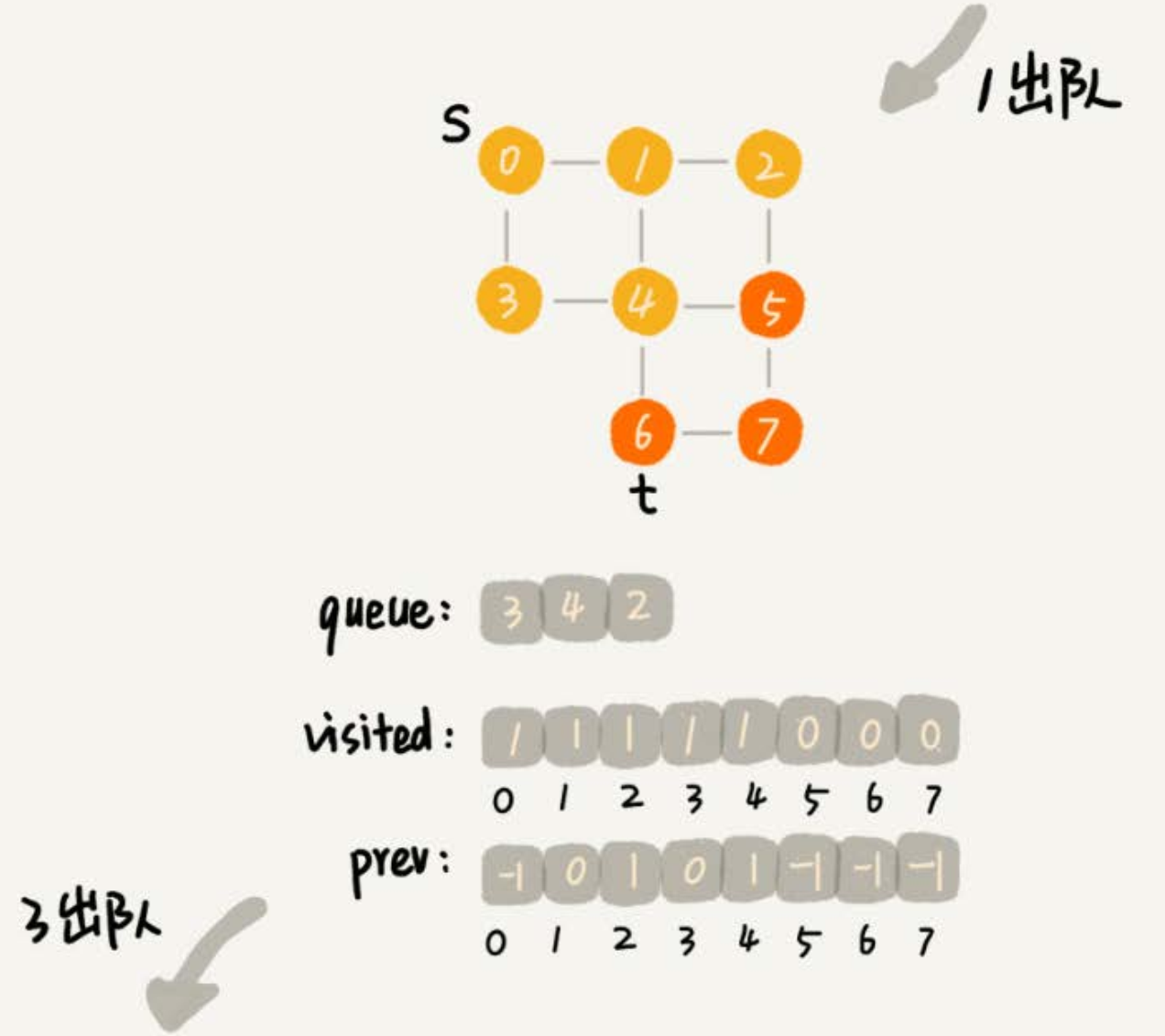
LinkedList<Integer> wLinked = adj[w]; // 表示:鄰接表存儲時頂點為w,所對應的鏈表
for (int i = 0; i < wLinked.size(); ++i) {
int q = wLinked.get(i);
// 判斷頂點 q 是否被訪問
if (!visited[q]) {
// 未被訪問
prev[q] = w;
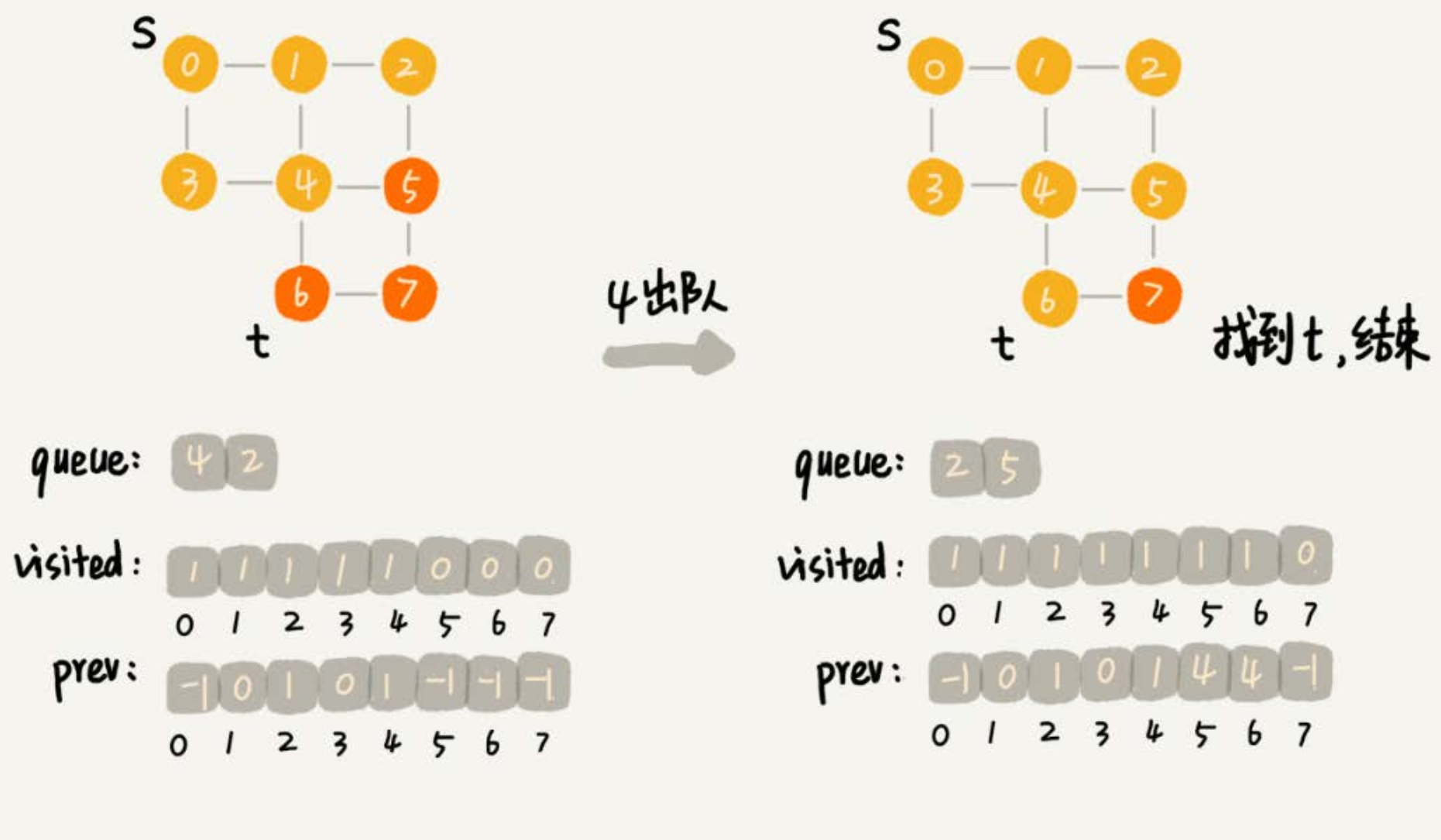
if (q == t) {
print(prev, s, t);
return;
}
visited[q] = true;
queue.add(q);
}
}
}
}
// 遞歸打印s->t的路徑
private void print(int[] prev, int s, int t) {
if (prev[t] != -1 && t != s) {
print(prev, s, prev[t]);
}
System.out.print(t + " ");
}
原理如下:
2.2、複雜度分析
- 最壞情況下,終止頂點 t 離起始頂點 s 很遠,需要遍歷完整個圖才能找到。
- 這個時候,每個頂點都要進出一遍隊列,每個邊也都會被訪問一次,所以,廣度優先搜索的時間複雜度是 O(V+E)。
- 其中,V 表示頂點的個數,E 表示邊的個數。
- 對於一個連通圖來說,也就是說一個圖中的所有頂點都是連通的,E肯定要大於等於 V-1,所以,廣度優先搜索的時間複雜度也可以簡寫為 O(E)。
- 廣度優先搜索的空間消耗主要在幾個輔助變量 visited 數組、queue 隊列、prev 數組上。
- 這三個存儲空間的大小都不會超過頂點的個數,所以空間複雜度是 O(V)。
三、深度優先搜索(DFS)
- 深度優先搜索(Depth-First-Search),簡稱DFS。
- 最直觀的例子就是「走迷宮,假設站在迷宮的某個岔路口,然後想找到出口。
- 隨意選擇一個岔路口來走,走着走着發現走不通的時候,就回退到上一個岔路口,重新選擇一條路繼續走,直到最終找到出口。這種走法就是一種深度優先搜索策略。
- 如下圖所示,在圖中應用深度優先搜索,來找某個頂點到另一個頂點的路徑。
- 搜索的起始頂點是 s,終止頂點是 t,在圖中尋找一條從頂點 s 到頂點 t 的路徑。
- 用深度遞歸算法,把整個搜索的路徑標記出來了。實線箭頭表示遍歷,虛線箭頭表示回退。
- 從圖中可以看出,深度優先搜索找出來的路徑,並不是頂點 s 到頂點 t 的最短路徑。
-
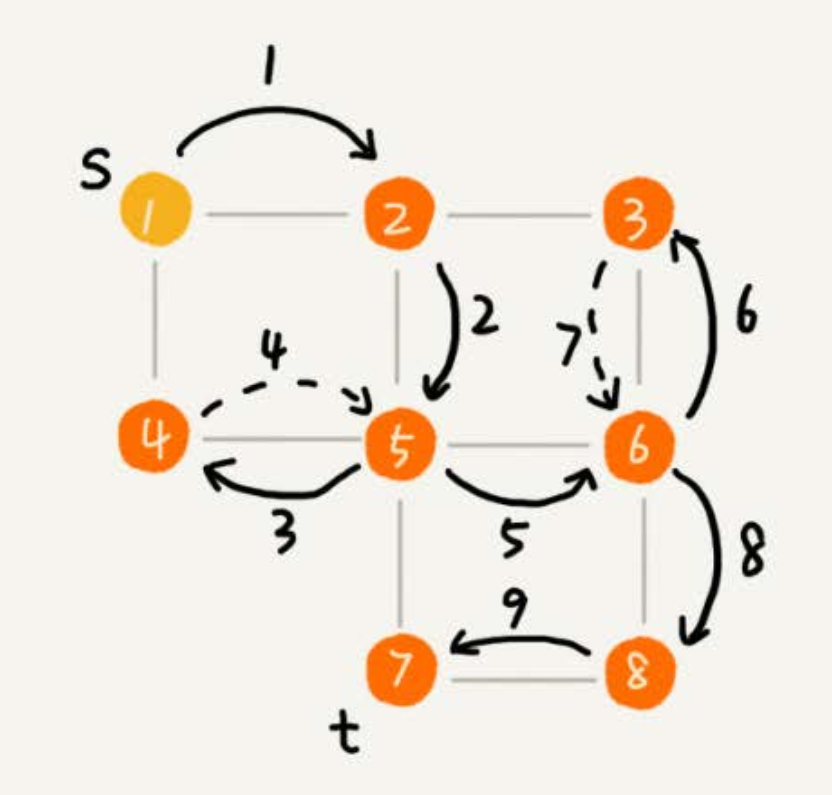

3.1、實現過程
// 全局變量或者類成員變量,標記是否找到終點 t
boolean found = false;
/**
* 深度優先搜索
*
* @param s 起始頂點
* @param t 終止頂點
*/
public void dfs(int s, int t) {
found = false;
// 標記頂點是否被訪問
boolean[] visited = new boolean[v];
// prev 用來記錄搜索路徑,prev[w] = a 表示 w 頂點的上一級節點為 a
int[] prev = Arrays.stream(new int[v])
.map(f -> -1).toArray();
recurDfs(s, t, visited, prev);
print(prev, s, t);
}
private void recurDfs(int w, int t, boolean[] visited, int[] prev) {
if (found == true) {
return;
}
visited[w] = true;
if (w == t) {
found = true;
return;
}
LinkedList<Integer> wLinked = adj[w];
for (int i = 0; i < wLinked.size(); ++i) {
int q = wLinked.get(i);
if (!visited[q]) {
prev[q] = w;
recurDfs(q, t, visited, prev);
}
}
}
3.2、複雜度分析
- 深度搜索中每條邊最多會被訪問兩次,一次是遍歷,一次是回退。
- 所以,深度優先搜索算法的時間複雜度是 O(E), E 表示邊的個數。
- 深度優先搜索算法的消耗內存主要是 visited、 prev 數組和遞歸調用棧。
- visited、 prev 數組的大小跟頂點的個數V成正比,遞歸調用棧的最大深度不會超過頂點的個數,所以總的空間複雜度就是 O(V)。
四,兩者對比
- 廣度優先搜索和深度優先搜索是圖上的兩種最常用、最基本的搜索算法,比起其他高級的搜索算法,比如A、 IDA等,要簡單粗暴,沒有什麼優化,所以,也被
叫作暴力搜索算法。 - 所以,這兩種搜索算法僅適用於狀態空間不大,也就是說圖不大的搜索。
- 廣度優先搜索,通俗的理解就是,地毯式層層推進,從起始頂點開始,依次往外遍歷。
- 廣度優先搜索需要藉助隊列來實現,遍歷得到的路徑就是,起始頂點到終止頂點的最短路徑。
- 深度優先搜索用的是回溯思想,非常適合用遞歸實現。換種說法,深度優先搜索是藉助棧來實現的。
- 在執行效率方面,深度優先和廣度優先搜索的時間複雜度都是 O(E),空間複雜度是 O(V)。


