Python多任務之線程
- 2019 年 10 月 10 日
- 筆記
多任務介紹
我們先來看一下沒有多任務的程序


import time def sing(): for i in range(5): print("我喜歡唱") time.sleep(1) def dance(): for i in range(5): print("我喜歡跳") time.sleep(1) def main(): sing() dance() pass if __name__ == "__main__": main()
沒有多任務的程序
運行結果:花了十秒鐘多,只能按順序執行,無法一起/同步執行
我喜歡唱 我喜歡唱 我喜歡唱 我喜歡唱 我喜歡唱 我喜歡跳 我喜歡跳 我喜歡跳 我喜歡跳 我喜歡跳
我們再來看一下使用了多線程的程序
import time import threading def sing(): for i in range(5): print("我喜歡唱歌") time.sleep(1) def dance(): for i in range(5): print("我喜歡跳舞") time.sleep(1) def main(): t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() t2.start() if __name__ == '__main__': main()
使用線程的多任務
運行結果:花了五秒多一點,代碼同步執行
我喜歡唱歌 我喜歡跳舞 我喜歡跳舞我喜歡唱歌 我喜歡跳舞 我喜歡唱歌 我喜歡跳舞 我喜歡唱歌 我喜歡跳舞 我喜歡唱歌
多任務
在這裡我們可以由多任務額外擴展一些知識,電腦是怎麼運行程序的?
單核cpu的運行原理:時間片輪轉
單核cpu同一時間只能運行一個程序,但你看到的能運行很多程序是因為單核cpu的快速切換,即把一個程序拿過來運行極短的時間比如0.00001秒,就換運行下一個程序,如此往複,就是你看到的同一時間執行多個程序。這是操作系統實現多任務的一種方式,但其實是偽多任務。
時間片輪轉的理念是,只要我切換的夠快,你看到的就是我同時做多件事情,這是操作系統的調度算法。操作系統還有優先級調度,比如聽歌要一直持續。
- 如果是多核cpu同時運行多個任務,我們就稱之為並行,是真的多任務;任務數少於cpu數量;
- 如果是單核cpu切換着運行多個任務,我們就稱之為並發,是假的多任務。任務數多於cpu數量;
- 但因為日常中,任務數一般多於cpu核數,所以我們說的多任務一般都是並發,即假的多任務;
Thread多線程
在前面我們已經看過了線程實現多任務,接下來我們學習線程的使用方法;
通過Thread(target=xxx)創建多線程
線程的使用步驟如下:
- 導入threading模塊;
- 編寫多任務所需要的的函數;
- 創建threading.Thread類的實例對象並傳入函數引用;
- 調用實例對象的start方法,創建子線程。
如果你還不懂怎麼使用多線程?沒關係,看下面這個圖就知道了
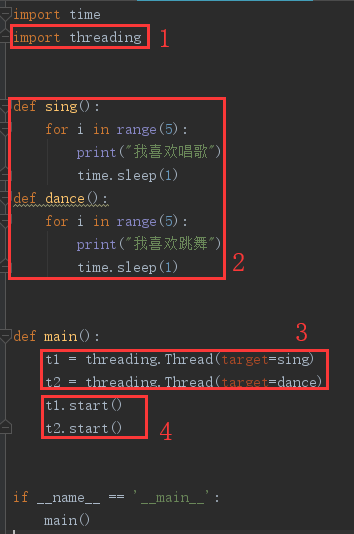
代碼如下:
import time import threading def sing(): for i in range(5): print("我喜歡唱歌") time.sleep(1) def dance(): for i in range(5): print("我喜歡跳舞") time.sleep(1) def main(): t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() t2.start() if __name__ == '__main__': main()
多線程的使用
注意:
- 函數名() 表示函數的調用
- 函數名 表示使用對函數的引用,告訴函數在哪;
代碼解讀
def main(): t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() t2.start()
每個函數在執行時都會有一個線程,我們稱之為主線程;
當我們執行到
t1 = threading.Thread(target=sing)
時,表示創建了一個Thread類的實例對象t1,並且給t1的Thread類中傳入了sing函數的引用。
同理,t2也是如此;
當我們執行到
t1.start()
時,這個實例對象就會創建一個子線程,去調用sing函數;然後主線程往下走,子線程去調用sing函數。
當主線程走到t2.start()時,再次創建一個子線程,子線程去調用dance函數,因為後面沒有代碼了,然後主線程就會等待所有子線程的完成,再結束程序/主線程;可以理解為主線程要給子線程死了之後收屍,然後主線程再去死。
主線程要等子線程執行結束的原因:子線程在執行過程中會調用資源以及產生一些變量等,當子線程執行完之後,
主線程要將這些無用的資源及垃圾進行清理工作。
多線程創建執行理解
我們可以使用如下代碼獲取當前程序中的所有線程;
threading.enumerate()
關於enumerate的使用,可以查看我的上一篇博客 python內置函數之enumerate函數 ,但這裡表示的是獲取當前程序中的所有線程,可以不必看;
讓某些線程先運行
因為 線程創建完後,線程的執行順序是不確定的,如果我們想要讓某個線程先執行,可以採用time.sleep的方法。代碼如下
import time import threading def sing(): for i in range(5): print("-----sing----%d" % i) def dance(): for i in range(5): print("-----dance----%d" % i) def main(): t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() time.sleep(1) print("sing") t2.start() time.sleep(1) print("dance") print(threading.enumerate()) if __name__ == '__main__': main()
讓某些線程先運行
運行結果
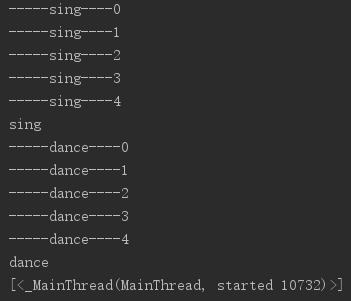
我們可以看到,sing線程已經先運行了,但是此時查看的線程只有一個主線程,這是因為當子線程執行完了才執行到查看線程的代碼。
循環查看當前運行的線程數
我們可以通過讓子線程延時執行多次,主線程死循環查看當前線程數(適當延時),即可看到當前運行的線程數量,當線程數量小於等於1時,使用break結束主線程。
代碼如下
import time import threading def sing(): for i in range(5): print("-----sing--%d--" % i) time.sleep(1) def dance(): for i in range(5): print("-----dance--%d--" % i) time.sleep(1) def main(): t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() t2.start() while True: t_len = len(threading.enumerate()) # print("當前運行線程數:%s" % t_len) print(threading.enumerate()) if t_len <= 1: break time.sleep(1) if __name__ == '__main__': main()
循環查看當前運行的線程數
運行結果
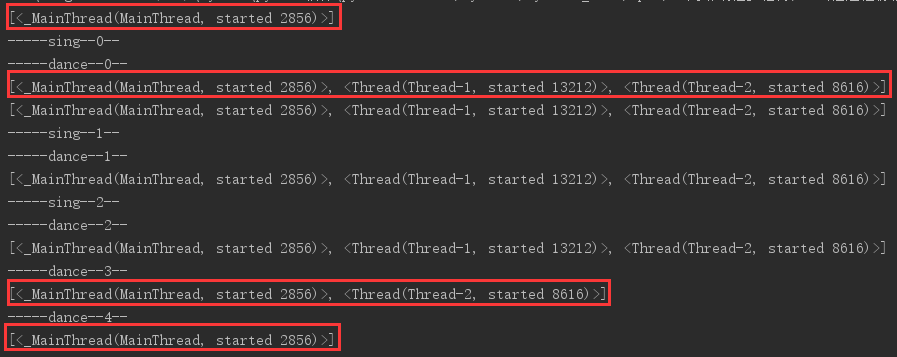
可以看到,剛開始的時候只有一個是主線程,當子線程開始後,有三個線程,在sing子線程結束後,只剩兩個線程了,dance結束後,只有一個主線程。
驗證子線程的執行時間
為了驗證子線程的執行時間,我們可以在交互式python下運行代碼,子線程調用的函數在何時執行即代表子線程在何時執行;
驗證結果如下

據此,我們可以判斷子線程的執行是在線程的示例對象調用start()方法之後執行的。
驗證代碼
import threading def sing(): print("-----sing-----") t1 = threading.Thread(target=sing) t1.start() -----sing-----
驗證子線程的創建時間
驗證原理:我們可以通過計算線程數在各個時間段的數量來判斷子線程的創建時間
驗證代碼
import time import threading def sing(): for i in range(5): print("----sing----") time.sleep(1) def main(): print("創建實例對象之前的線程數:", len(threading.enumerate())) t1 = threading.Thread(target=sing) print("創建實例對象之後/start方法之前的線程數:", len(threading.enumerate())) t1.start() print("調用start方法之後的線程數:", len(threading.enumerate())) if __name__ == '__main__': main()
驗證子線程的創建時間
驗證結果
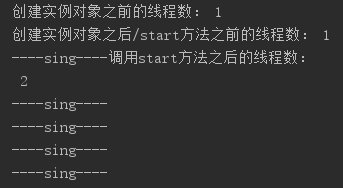
可以觀察到在調用start方法之前線程數一直都是1個主線程,由此我們可以判斷線程的創建時間是在調用了實例對象的start方法之後;
結合前面,我們可以得出結論,子線程的創建時間和執行時間是在Thread創建出來的實例對象調用了start方法之後,而子線程的結束時間是在調用的函數執行完成後。
通過繼承Thread類來創建進程
前面我們是通過子線程調用一個函數,那麼當函數過多時,想將那些函數封裝成一個類,我們可以不可以通過子線程調用一個類呢?
創建線程的第二種方法步驟
- 導入threading模塊;
- 定義一個類,類裏面繼承threading.Thread類,裏面定義一個run方法;
- 然後創建這個類的實例對象;
- 調用實例對象的start方法,就創建了一個線程。
如果你創建一個線程的時候是通過 類繼承一個Thread類來創建的,必須在裏面定義run方法,當你調用start方法的時候,會自動調用run方法,接下來線程執行的就是run方法裏面的代碼。
通過繼承Thread類來創建進程示例代碼
import time import threading class TestThread(threading.Thread): def run(self): print("---run---") for i in range(3): msg = "我是%s,i--->%s" % (self.name, str(i)) # self.name中保存的是當前線程的名字 print(msg) time.sleep(1) def main(): t1 = TestThread() t1.start() if __name__ == '__main__': main()
通過繼承Thread類來創建進程
運行結果
---run--- 我是Thread-1,i--->0 我是Thread-1,i--->1 我是Thread-1,i--->2
知識點
- 這種方法適用於一個線程裏面要做的事情比較複雜,要封裝成幾個函數來做,那麼我們就將它封裝成一個類。
- 在類中定義其他的幾個函數,可以在run裏面進行調用這幾個函數。
- 創建線程時使用哪種方法比較好?哪個簡單使用哪個。
注意:
一個實例對象只能創建一個線程;
通過繼承Thread類來創建進程時,不會自動調用類中除run函數的其他函數,如果想要調用其他可數,可以在run方法中使用self.xxx()來調用。
多線程共享變量
在函數中修改全局變量,如果是數字等不可變類型,要用global聲明之後才能修改,如果是列表等可變類型,就可以不用聲明,直接append等對列表內容進行修改,但,如果不是對列表內容進行修改,而是指向一個新的列表,就需要使用global聲明;
在全局變量中,如果是對引用的數據進行修改,那麼不需要使用global,如果是對全局變量的引用進行修改(直接換一個引用地址),那麼就需要使用global,同時,我們也應注意全局變量是可變類型還是不可變類型,比如數字,不可變,就只能通過修改變量的引用來進行修改全局變量了,所以需要global;
驗證多線程中共享全局變量
驗證原理:
定義一個全局變量,在函數1中加1,在函數2中查看,讓線程控制的函數1先執行,如果線程函數2的查看結果和函數1的查看結果一樣,那麼就證明多線程之間共享全局變量。
代碼驗證
import time import threading g_num = 100 def sing(): global g_num g_num += 1 print("---sing中的g_num: %d---" % g_num) time.sleep(1) def dance(): print("---dance中的g_num: %d---" % g_num) time.sleep(1) def main(): t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() t2.start() print("---主線程中的g_num: %d---" % g_num) if __name__ == '__main__': main()
多線程之間共享全局變量驗證
運行結果
---sing中的g_num: 101--- ---dance中的g_num: 101--- ---主線程中的g_num: 101---
如上代碼我們可知,多線程之間共享全局變量。
我們可以將多線程之間共享去全局變量理解為:
一個房子裏面有幾個人,一個人就是一個線程,每個人有自己私有的東西資源,但在這個大房子裏面,也有些共有的東西,比如說唯一一台飲水機的水,有一個人喝了一半,拿下一個人來接水,也只剩下一半了,這個飲水機裏面的誰就是全局變量。
多線程給子線程傳參
給子線程傳參數語法如下
g_nums = [11, 22] t1 = threading.Thread(target=sing, args=(g_num,))
給子線程傳參示例代碼
import time import threading def sing(temp): temp.append(33) print("---sing中的g_nums: %s---" % str(temp)) time.sleep(1) def dance(temp): print("---dance中的g_nums: %s---" % str(temp)) time.sleep(1) g_nums = [11, 22] def main(): t1 = threading.Thread(target=sing, args=(g_nums,)) t2 = threading.Thread(target=dance, args=(g_nums,)) t1.start() time.sleep(1) t2.start() time.sleep(1) print("---主線程中的g_nums: %s---" % str(g_nums)) if __name__ == '__main__': main()
給子線程傳參數
運行結果
---sing中的g_nums: [11, 22, 33]--- ---dance中的g_nums: [11, 22, 33]--- ---主線程中的g_nums: [11, 22, 33]---
多線程之間共享問題:資源競爭
共享全局變量存在資源競爭的問題,兩個線程同時使用或者修改就會存在問題,一個修改一個使用不會存在;
傳參100的時候可能不會出現問題,因為數字較小,概率也小點;但傳參1000000的時候,數字變大,概率也變大;
num += 1可以分解為三句,獲取num的值,給值加1,給num重賦值;有可能當線程1執行12句,正打算執行3句的時候,cpu就將資源給了線程2,而線程2同理,然後又執行線程1的第3句,因此線程1 +1,存儲全局變量為1;輪到線程2 +1,存儲全局變量也為1;問題就出現了,本來加兩次應該是2的,但全局變量還是1。
資源競爭代碼示例
import time import threading g_num = 0 def add1(count): global g_num for i in range(count): g_num += 1 print("the g_num of add1:", g_num) def add2(count): global g_num for i in range(count): g_num += 1 print("the g_num of add2:", g_num) def main(): t1 = threading.Thread(target=add1, args=(1000000,)) t2 = threading.Thread(target=add2, args=(1000000,)) t1.start() t2.start() time.sleep(3) print("the g_num of main:", g_num) if __name__ == '__main__': main()
共享變量的資源競爭問題
運行結果
the g_num of add1: 1096322 the g_num of add2: 1294601 the g_num of main: 1294601
互斥鎖解決資源競爭問題
原子性操作:要麼不做,要麼做完;
互斥鎖:一個人做某事的時候,別人不允許做這件事,必須需得等到前面的人做完了這件事,才能接着做,例子景點上廁所。
互斥鎖語法
# 創建鎖: mutex = threading.Lock() # 上鎖: mutex.acquire() # 解鎖: mutex.release()
使用互斥鎖解決資源競爭問題
import time import threading g_num = 0 def add1(num): global g_num for i in range(num): mutex.acquire() g_num += 1 mutex.release() print("the g_num of add1:", g_num) def add2(num): global g_num for i in range(num): mutex.acquire() g_num += 1 mutex.release() print("the g_num of add2:", g_num) mutex = threading.Lock() def main(): t1 = threading.Thread(target=add1, args=(1000000,)) t2 = threading.Thread(target=add2, args=(1000000,)) t1.start() t2.start() time.sleep(2) print("the g_num of main:", g_num) if __name__ == '__main__': main()
使用互斥鎖解決資源競爭的問題
運行結果
the g_num of add2: 1901141 the g_num of add1: 2000000 the g_num of main: 2000000
可以看出,使用互斥鎖可以解決資源競爭的問題。
死鎖問題
使用互斥鎖特別是多個互斥鎖的時候,特別容易產生死鎖,就是你在等我的資源,我在等你的資源;
本章內容總結
線程的生命周期
- 從程序開始執行到結束,一直都有一條主線程
- 如果主線程先死了,那麼正在運行的子線程也會死。
- 子線程開始創建是在調用t.start()時,而不是創建Thread的實例化對象時。
- 子線程的開始執行是在調用t.start()時;
- 子線程的死亡時間是在子線程調用的函數執行完成後;
- 線程創建完後,線程的執行順序是不確定的;
- 如果想要讓某個線程先執行,可以採用time.sleep的方法。
創建多線程的兩種方式
通過Thread(target=xxx)創建多線程
- 導入threading模塊;
- 編寫多任務所需要的的函數;
- 創建threading.Thread類的實例對象並傳入函數引用;
- 調用實例對象的start方法,創建子線程。
通過繼承Thread類來創建進程
- 導入threading模塊;
- 定義一個類,類裏面繼承threading.Thread類,裏面定義一個run方法;
- 然後創建這個類的實例對象;
- 調用實例對象的start方法,就創建了一個線程。
多線程理解
- 創建多線程可以理解為創建線程做準備;
- start() 則是準備好後直接創建並運行線程;
- 主線程要等子線程結束後在結束是為了清理子線程中可能產生的垃圾;
多線程共享全局變量
- 子線程和子線程之間共享全局變量;
- 給子線程傳參可以使用 threading.Thread(target=sing, args=(g_num,)) 進行傳參;
- 多線程之間可能存在資源競爭的問題;
- 可以使用互斥鎖解決資源競爭的問題;
