集群故障處理之處理思路以及健康狀態檢查(三十二)
- 2019 年 10 月 3 日
- 筆記
前言
按照筆者的教程,大家應該都能夠比較順暢的完成k8s集群的部署,不過由於環境、配置以及對Linux、k8s的不了解會導致很多問題、異常和故障,這裡筆者分享一些處理技巧和思路,以及部分常見的問題,以供大家參考和學習。
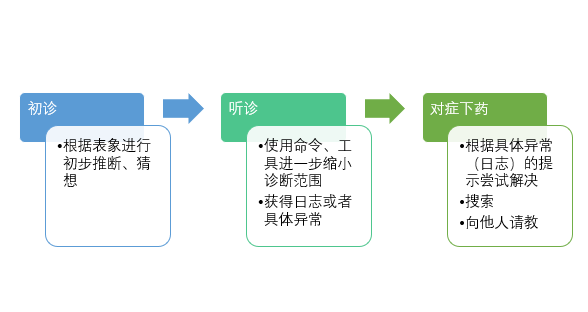
總之,出現問題不要慌,先根據異常、故障癥狀初步推敲問題的所在,然後結合相關命令、工具、日誌推敲出具體問題。其中,具體的日誌內容是關鍵,請務必獲得相關異常的詳細日誌進行診斷,而不是被表象所迷惑,或者根據表象問題(比如“XXXX”pod崩潰了)去猜、搜索或者請教他人。總體上,思路如下圖所示:

如果問題實在無法解決或者無法確定是哪裡的配置以及操作不當引起的,可以試着重置節點以及重置集群。
如果出現問題,我們應該怎麼去分析和解決問題呢?下面,筆者將分享一些思路和經驗:
目錄
健康狀態檢查——初診
-
組件、插件健康狀態檢查
-
Kubernetes 組件異常分析
-
節點健康狀態檢查
-
Pod健康狀態檢查
健康狀態檢查——初診
首先,我們需要根據表象進行初步診斷,以便沿着線索按圖索驥。
組件、插件健康狀態檢查
使用命令:
kubectl get componentstatus
或
kubectl get cs
健康情況下如下圖所示:


Kubernetes組件(插件)部分默認基於systemd運行,比如kubelet、docker等,我們需要使用以下命令確保其處於活動(active)狀態:
systemctl status kubelet docker


而大部分的Kubernetes的組件則運行在命名空間為“kube-system”的靜態Pod 之中(參見“kubeadm init”一節),我們可以使用以下命令來查看這些Pod 的狀態:
kubectl get pods -o wide -n kube-system


Kubernetes 組件異常分析
k8s組件主要分為Master組件和節點組件,Master組件對集群做出全局性決策(比如調度), 以及檢測和響應集群事件。如果Master組件出現問題,可能會導致集群不可訪問,Kubernetes API 訪問出錯,各種控制器無法工作等等。而節點組件在每個節點上運行,維護運行的Pod並提供 Kubernetes運行時環境。如果節點組件出現問題,可能會導致該節點異常並且該節點Pod無法正常運行和結束。
因此,根據不同的組件,可能會出現不同的異常。
kube-apiserver對外暴露了Kubernetes API,如果kube-apiserver出現異常可能會導致:
-
集群無法訪問,無法註冊新的節點
-
資源(Deployment、Service等)無法創建、更新和刪除
-
現有的不依賴Kubernetes API的pods和services可以繼續正常工作
etcd用於Kubernetes的後端存儲,所有的集群數據都存在這裡。保持穩定的etcd集群對於Kubernetes集群的穩定性至關重要。因此,我們需要在專用計算機或隔離環境上運行etcd集群以確保資源需求。當etcd出現異常時可能會導致:
-
kube-apiserver無法讀寫集群狀態,apiserver無法啟動
-
Kubernetes API訪問出錯
-
kubectl操作異常
-
kubelet無法訪問apiserver,僅能繼續運行已有的Pod
kube-controller-manager和kube-scheduler分別用於控制器管理和Pod 的調度,如果他們出現問題,則可能導致:
-
相關控制器無法工作
-
資源(Deployment、Service等)無法正常工作
-
無法註冊新的節點
-
Pod無法調度,一直處於Pending狀態
kubelet是主要的節點代理,如果節點宕機(VM關機)或者kubelet出現異常(比如無法啟動),那麼可能會導致:
-
該節點上的Pod無法正常運行,如果節點關機,則當前節點上所有Pod都將停止運行
-
已運行的Pod無法伸縮,也無法正常終止
-
無法啟動新的Pod
-
節點會標識為不健康狀態
-
副本控制器會在其它的節點上啟動新的Pod
-
Kubelet有可能會刪掉當前運行的Pod
CoreDNS(在1.11以及以上版本的Kubernetes中,CoreDNS是默認的DNS服務器)是k8s集群默認的DNS服務器,如果其出現問題則可能導致:
-
無法註冊新的節點
-
集群網絡出現問題
-
Pod無法解析域名
kube-proxy是Kubernetes在每個節點上運行網絡代理。如果它出現了異常,則可能導致:
-
該節點Pod通信異常
節點健康狀態檢查
我們可以使用以下命令來檢查節點狀態:
kubectl get nodes
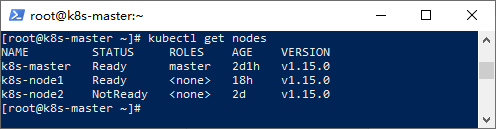

其中,“Ready”表示節點已就緒,為正常狀態,反之則該節點出現異常。節點出現問題,則Pod無法無法調度到該節點。
Pod健康狀態檢查
如果是集群應用出現異常,我們需要檢查相關Pod是否運行正常,可以使用以下命令:
kubectl get pods -o wide
如果存在命名空間,需要使用-n參數指定命名空間。如上圖所示,Pod為“Running”狀態才是正常。
如果Pod運行正常,但是又無法訪問(集群內部、外部),這時,我們需要檢查Service是否正常,可使用以下命令:
kubectl get svc -o wide



