[譯]深入理解JVM Understanding JVM Internals
轉載:
英文原版地址://www.cubrid.org/blog/dev-platform/understanding-jvm-internals/
翻不了牆的可以看這個英文版://www.cnblogs.com/davidwang456/p/3464743.html
我找了個翻譯版看,但是圖片刷不出來://segmentfault.com/a/1190000004206269
國內英文版那個代碼排版又很差,但是有圖,我這裡把兩個整合一下
//itindex.net/detail/41088-理解-jvm-內幕
正文
每個使用Java的開發者都知道Java位元組碼是在JRE中運行(Java Runtime Environment Java運行時環境)。JRE中最重要的部分是 Java虛擬機(JVM),JVM負責分析和執行Java位元組碼,Java開發人員並不需要去關心JVM是如何運行的。在沒有深入理解JVM的情況下,許多開發者已經開發出了非常多的優秀的應用以及Java類庫。不過,如果你了解JVM的話,你會更加了解Java的,並且你會輕鬆解決那些看似簡單但是無從下手的問題。
因此,在這篇文件里,我會闡述JVM是如何運行的,包括它的結構,它如何去執行位元組碼,以及按照怎樣的順序去執行,同時我還會給出一些常見錯誤的示例以及對應的解決辦法。最後,我還會講解Java 7中的一些新特性
虛擬機
JRE是由Java API和JVM組成的。JVM的主要作用是通過Class Loader來加載Java程序,並且按照Java API來執行加載的程序。
虛擬機(VM: Virtual Machine) 虛擬機是通過軟件的方式來模擬實現的機器(比如說計算機),它可以像物理機一樣運行程序。設計虛擬機的初衷是讓Java能夠通過它來實現 WORA( Write Once Run Anywhere 一次編譯,到處運行),儘管這個目標現在已經被大多數人忽略了。因此,JVM可以在不修改Java代碼的情況下,在所有的硬件環境上運行 Java位元組碼。
JVM的基本特性:
- 基於棧(Stack-based)的虛擬機: 不同於Intel x86和ARM等比較流行的計算機處理器都是基於_寄存器(register)架構,JVM是_基於棧執行的。
- 符號引用(Symbolic reference): 除了基本類型以外的數據(類和接口)都是通過符號來引用,而不是通過顯式地使用內存地址來引用。
- 垃圾回收機制: 類的實例都是通過用戶代碼進行創建,並且自動被垃圾回收機制進行回收。
- 通過明確清晰基本類型確保平台無關性: 傳統的編程語言,例如C/C++,int類型的大小取決於不同的平台。JVM通過對基本類型的清晰定義來保證它的兼容性以及平台獨立性。
- 網絡位元組序(Network byte order): Java class文件的二進制表示使用的是基於網絡的位元組序(network byte order)。為了在使用小端(little endian)的Intel x86平台和在使用了大端(big endian)的RISC系列平台之間保持平台無關,必須要定義一個固定的位元組序。JVM選擇了網絡傳輸協議中使用的網絡位元組序,即基於大端(big endian)的位元組序。
雖然是Sun公司開發了Java,但是所有的開發商都可以開發並且提供遵循Java虛擬機規範的JVM。正是由於這個原因,使得Oracle HotSpot和IBM JVM等不同的JVM能夠並存。Google的Android系統里的Dalvik VM也是一種JVM,雖然它並不遵循Java虛擬機規範。和基於棧的Java虛擬機不同,Dalvik VM是基於寄存器的架構,因此它的Java位元組碼也被轉化成基於寄存器的指令集。
Java 位元組碼(Java bytecode)
為了保證WORA,JVM使用Java位元組碼這種介於Java和機器語言之間的中間語言。位元組碼是部署Java代碼的最小單位。
在解釋Java位元組碼之前,我們先通過實例來簡單了解它。這個案例是一個在開發環境出現的真實案例的總結。
現象
一個一直運行正常的應用突然無法運行了。在類庫被更新之後,返回下面的錯誤。
Exception in thread "main" java.lang.NoSuchMethodError: com.nhn.user.UserAdmin.addUser(Ljava/lang/String;)V at com.nhn.service.UserService.add(UserService.java:14) at com.nhn.service.UserService.main(UserService.java:19)
程序代碼如下,並在更新類庫之前未曾對這段代碼做過變更:
// UserService.java …
public void add(String userName) {
admin.addUser(userName);
}
類庫中更新過的代碼前後對比如下:
// UserAdmin.java – 更新後的源碼 …
public User addUser(String userName) {
User user = new User(userName);
User prevUser = userMap.put(userName, user);
return prevUser;
}
// UserAdmin.java - 更新前的源碼 …
public void addUser(String userName) {
User user = new User(userName);
userMap.put(userName, user);
}
簡而言之,之前沒有返回值的addUser()被改修改成返回一個User類的實例的方法。不過,應用的代碼沒有做任何修改,因為它沒有使用addUser()的返回值。
咋一看,com.nhn.user.UserAdmin.addUser()方法似乎仍然存在,如果存在的話, 那麼怎麼還會出現NoSuchMethodError的錯誤呢?,
問題分析
上面問題的原因是在於應用的代碼沒有用新的類庫來進行編譯。換句話來說,應用代碼似乎是調了正確的方法,只是沒有使用它的返回值而已。不管怎樣,編譯後的class文件表明了這個方法是有返回值的。你可以從下面的錯誤信息里看到答案。
可以通過下面的異常信息說明這一點:
java.lang.NoSuchMethodError: com.nhn.user.UserAdmin.addUser(Ljava/langString;)V
NoSuchMethodError出現的原因是「com.nhn.user.UserAdmin.addUser(Ljava/lang/String;)V」方法找不到。注意一下」Ljava/lang/String;」和最後面的「V」。在Java位元組碼的表達式里,」L
因為程序代碼是使用之前版本的類庫進編譯的,class文件中定義的是應該調用返回”V”類型的方法(返回值為空)。然而,在改變類庫後,返回”V”類型(返回值為空)的方法已不存在,取而代之的是返回類型為”Lcom/nhn/user/User;”的方法。所以便發生了上面看到的NoSuchMethodError。
注釋
因為開發者未針對新類庫重新編譯程序代碼,所以發生了錯誤。儘管如此,類庫提供者卻也要為此負責。因為之前沒有返回值的addUser()方法既然是public方法,但後面卻改成了會返回user實現,這意味着方法簽名發生了明顯的變化。這意味了該類庫不能對之前的版本進行兼容,所以類庫提供者必須事前對此進行通知。
我們重新回到Java 位元組碼,Java 位元組碼 是JVM的基本元素,JVM本身就是一個用於執行Java位元組碼的執行器。Java編譯器並不會把像C/C++那樣把高級語言轉為機器語言(CPU執行指令),而是把開發者能理解的Java語言轉為JVM理解的Java位元組碼。因為Java位元組碼是平台無關的,所以它可以在安裝了JVM(準確的說,是JRE環境)的任何硬件環境執行,即使它們的CPU和操作系統各不相同(所以在Windows PC機上開發和編譯的class文件在不做任何調整的情況下就可以在Linux機器上執行)。編譯後文件的大小與源文件大小基本一致,所以比較容易通過網絡傳輸和執行Java位元組碼。
The class file itself is a binary file that cannot be understood by a human. Java class-文件是一種人很難去理解的二進制文件,所以我們很難直觀的理解其中的指令。為了便於理解它,JVM提供者提供了javap,反彙編器。使用javap產生的結果是Java彙編語言。在上面的例子中,下面的Java彙編代碼是通過javap -c對UserServiceadd()方法進行反彙編得到的。
public void add(java.lang.String);
Code:
0: aload_0
1: getfield #15; //Field admin:Lcom/nhn/user/UserAdmin;
4: aload_1
5: invokevirtual #23; //Method com/nhn/user/UserAdmin.addUser:(Ljava/lang/String;)V
8: return
在這段Java彙編代碼中,addUser()方法是在第四行的「5:invokevitual#23″進行調用的。這表示對應索引為23的方法會被調用。索引為23的方法的名稱已經被javap給註解在旁邊了。 invokevirtual是Java位元組碼里調用方法的最基本的操作碼(Opcode)。在Java位元組碼里,有四種操作碼可以用來調用一個方法,分別是:invokeinterface,invokespecial,invokestatic以及invokevirtual。操作碼的作用分別如下:
- invokeinterface: 調用接口方法
- invokespecial: 調用初始化方法、私有方法、或父類中定義的方法
- invokestatic: 調用靜態方法
- invokevirtual: 調用實例方法
Java 位元組碼的指令集包含操作碼(OpCode)和操作數(Operand)。像invokevirtual這樣的操作碼需要一個2位元組長度的操作數。(需要2個位元組的操作數。)
By compiling the application code above with the updated library and then disassembling it, the following result will be obtained.
對上面案例中的程序代碼,如果在更新類庫後重新編譯程序代碼,然後我們再反編譯位元組碼將看到如下結果:
用更新的類庫來編譯上面的應用代碼,然後反編譯它,將會得到下面的結果:
public void add(java.lang.String);
Code:
0: aload_0
1: getfield #15; //Field admin:Lcom/nhn/user/UserAdmin;
4: aload_1
5: invokevirtual #23; //Method com/nhn/user/UserAdmin.addUser:(Ljava/lang/String;)Lcom/nhn/user/User;
8: pop
9: return
你會發現,對應索引為23的方法被替換成了一個返回值為」Lcom/nhn/user/User」的方法。
在上面的反編譯結果中,代碼前面的數字是具有什麼含義?
表示該Opcode位於第幾個位元組(以0開始),大概這就是為什麼運行在JVM上面的代碼成為Java「位元組」碼的原因。像 aload_0, getfield 和 invokevirtual 都被表示為一個單位元組數字。(aload_0 = 0x2a, getfiled = 0xb4, invokevirtual = 0xb6)。因此Java位元組碼錶示的最大指令碼為256。(一個位元組是2的8次方,可以表示2的8次方,0-255)
像aload_0和aload_1這樣的操作碼不需要任何操作數,因此aload_0的下一個位元組就是下一個指令的操作碼。而像getfield和invokevirtual這樣的操作碼卻需要一個2位元組的操作數,因此第一個位元組里的第二個指令getfield指令的一下指令是在第4個位元組,其中跳過了2個位元組。通過16進制編輯器查看位元組碼如下:
0 1 2 3 4 5 6 7 8 9
2a b4 00 0f 2b b6 00 17 57 b1
(aload_0 = 0x2a, getfiled = 0xb4, invokevirtual = 0xb6) 怎樣計算來的??
aload_0, aload_1, getfield 和 invokevirtual 都為操作碼 佔一個位元組
getfield ,getfield 都需要兩個位元組的操作數。
0x2a –> aload_0 OpCode
0xb4 –> getfield OpCode
0x00 –> one of Operand of getfield OpCode
0x0f –> one of Operand of getfield OpCode
0x2b –> aload_1 OpCode
0xb6 –> invokevirtual Opcode
0x00 –> one of Operand of invokevirtual OpCode
0x17 –> one of Operand of invokevirtual OpCode
0x57 –> pop OpCode
0xb1 –> return OpCode
在Java位元組碼中,類實例表示為”L;”,而void表示為”V”,類似的其他類型也有各自的表示。下表列出了Java位元組碼中類型表示。
表1: Java位元組碼里的類型表示
| Java 位元組碼 | 類型 | 描述 |
|---|---|---|
| B | byte | 單位元組 |
| C | char | Unicode字符 |
| D | double | 雙精度浮點數 |
| F | float | 單精度浮點數 |
| I | int | 整型 |
| J | long | 長整型 |
| L | 引用 | classname類型的實例 |
| S | short | 短整型 |
| Z | boolean | 布爾類型 |
| [ | 引用 | 一維數組 |
表2: Java代碼的位元組碼示例
| Java 位元組碼 | Java 位元組碼錶示 |
|---|---|
| double d[][][] | [[[D |
| Object mymethod(int i, double d, Thread t) | mymethod(I,D,Ljava/lang/Thread;)Ljava/lang/Object; |
在《Java虛擬機技術規範第二版》的4.3 描述符(Descriptors)章節中有關於此的詳細描述,在第6章”Java虛擬機指令集”中介紹了更多不同的指令。
類文件格式
現象
當我們編寫完jsp代碼,並且在Tomcat運行時,Jsp代碼沒有正常運行,而是出現了下面的錯誤。
Servlet.service() for servlet jsp threw exception org.apache.jasper.JasperException: Unable to compile class for JSP Generated servlet error: The code of method _jspService(HttpServletRequest, HttpServletResponse) is exceeding the 65535 bytes limit”
問題分析
在不同的Web服務器上,上面的錯誤信息可能會有點不同,不過有有一點肯定是相同的,它出現的原因是65535位元組的限制。這個65535位元組的限制是JVM規範里的限制,它規定了 一個方法的大小不能超過65535位元組。
下面我會更加詳細地講解這個65535位元組限制的意義以及它出現的原因。
Java位元組碼里的分支和跳轉指令分別是」goto”和”jsr”。
goto [branchbyte1] [branchbyte2]
jsr [branchbyte1] [branchbyte2]
這兩個指令都接收一個2位元組的有符號的分支跳轉偏移量做為操作數,因此偏移量最大只能達到65535。不過,為了支持更多的跳轉,Java位元組碼提供了”goto_w”和”jsr_w”這兩個可以接收4位元組分支偏移的指令。
goto_w [branchbyte1] [branchbyte2] [branchbyte3] [branchbyte4]
jsr_w [branchbyte1] [branchbyte2] [branchbyte3] [branchbyte4]
受這兩個指令所賜,分支能表示的最大偏移遠遠超過了65535,這麼說來java 方法就不會再有65535個位元組的限制了。然而,由於Java 類文件的各種其他限制,java方法的定義仍然不能夠超過65535個位元組的限制。下面我們通過對類文件的解釋來看看java方法不能超過65535位元組的其他原因。
Java類文件的大體結構如下:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];}
上面的文件結構出自《Java虛擬機技術規範第二版》的4.1節 類文件結構。
之前講過的UserService.class文件的前16個位元組的16進制表示如下:
ca fe ba be 00 00 00 32 00 28 07 00 02 01 00 1b
我們通過對這一段符號的分析來了解一個類文件的具體格式。
- magic: 類文件的前4個位元組是一組魔數,是一個用於區分Java類文件的預定義值。如上所看到的,其值固定為0xCAFEBABE。也就是說一個文件的前4個位元組如果是0xCAFABABE,就可以認為它是Java類文件。”CAFABABE”是與”JAVA”有關的一個有趣的魔數。
- minor_version, major_version: 接下來的4個位元組表示類的版本號。如上所示,0x00000032表示的類版本號為50.0。由JDK 1.6編譯而來的類文件的版本號是50.0,而由JDK 1.5編譯而來的版本號則是49.0。JVM必須保持向後兼容,即保持對比其版本低的版本的類文件的兼容。而如果在一個低版本的JVM中運行高版本的類文件,則會出現java.lang.UnsupportedClassVersionError的發生。
- constant_pool_count, constant_pool[]: 緊接着版本號的是類的常量池信息。這裡的信息在運行時會被分配到運行時常量池區域,後面會有對內存分配的介紹。在JVM加載類文件時,類的常量池裡的信息會被分配到運行時常量池,而運行時常量池又包含在方法區內。上面UserService.class文件的constant_pool_count為0x0028,所以按照定義contant_pool數組將有(40-1)即39個元素值。
- access_flags: 2位元組的類的修飾符信息,表示類是否為public, private, abstract或者interface。
- this_class, super_class: 分別表示保存在constant_pool數組中的當前類及父類信息的索引值。
- interface_count, interfaces[]: interface_count為保存在constant_pool數組中的當前類實現的接口數的索引值,interfaces[]即表示當前類所實現的每個接口信息。
- fields_count, fields[]: 類的字段數量及字段信息數組。字段信息包含字段名、類型、修飾符以及在constant_pool數組中的索引值。
- methods_count, methods[]: 類的方法數量及方法信息數組。方法信息包括方法名、參數的類型及個數、返回值、修飾符、在constant_pool中的索引值、方法的可執行代碼以及異常信息。
- attributes_count, attributes[]: attribute_info有多種不同的屬性,分別被field_info, method_into使用。
javap程序把class文件格式以可閱讀的方式輸出來。在對UserService.class文件使用”javap -verbose”命令分析時,輸出內容如下:
Compiled from "UserService.java"
public class com.nhn.service.UserService extends java.lang.Object
SourceFile: "UserService.java"
minor version: 0
major version: 50
Constant pool:const #1 = class #2; // com/nhn/service/UserService
const #2 = Asciz com/nhn/service/UserService;
const #3 = class #4; // java/lang/Object
const #4 = Asciz java/lang/Object;
const #5 = Asciz admin;
const #6 = Asciz Lcom/nhn/user/UserAdmin;;// … omitted - constant pool continued …
{
// … omitted - method information …
public void add(java.lang.String);
Code:
Stack=2, Locals=2, Args_size=2
0: aload_0
1: getfield #15; //Field admin:Lcom/nhn/user/UserAdmin;
4: aload_1
5: invokevirtual #23; //Method com/nhn/user/UserAdmin.addUser:(Ljava/lang/String;)Lcom/nhn/user/User;
8: pop
9: return LineNumberTable:
line 14: 0
line 15: 9 LocalVariableTable:
Start Length Slot Name Signature
0 10 0 this Lcom/nhn/service/UserService;
0 10 1 userName Ljava/lang/String; // … Omitted - Other method information …
}
由於篇幅原因,上面只抽取了部分輸出結果。在全部的輸出信息中,會為你展示包括常量池和每個方法內容等各種信息。
方法的65535個位元組的限制受到了method_info struct的影響。如上面”javap -verbose”的輸出所示,method_info結構包含Code,LineNumberTable,以及LocalViriable attribute幾個屬性,這個在「javap -verbose”的輸出里可以看到。Code屬性里的LineNumberTable,LocalVariableTable以及exception_table的長度都是用一個固定的2位元組來表示的。因此,方法的大小是不能超過LineNumberTable,LocalVariableTable以及exception_table的長度的,它們都是65535位元組(即不能超過65535個位元組)。
儘管許多人都在抱怨方法的大小限制,JVM規範里也聲稱了」這個長度以後有可能會是可擴展的「。不過,到現在為止,還沒有為這個限制做出任何動作。從JVM規範里的把class文件里的內容直接拷貝到方法區這個特點來看,要想在保持後向兼容性的同時來擴展方法區的大小是非常困難的。
對於一個由Java編譯器錯誤而導致的錯誤的類文件將發生怎樣的情況?如果是在網絡傳輸或文件複製過程中,類文件被損壞又將發生什麼?
為了應對這種場景,Java的類裝載器通過一個嚴格而且慎密的過程來校驗class文件。在JVM規範里詳細地講解了這方面的內容。
注釋 我們怎樣能夠判斷JVM正確地執行了class文件校驗的所有過程呢?我們怎麼來判斷不同提供商的不同JVM實現是符合JVM規範的呢?
劃重點:驗證jvm
1.驗證jvm是否符合jvm規範
2.驗證jvm是否成功執行類文件的驗證過程
為了能夠驗證以上兩點,Oracle提供了一個測試工具TCK(Technology Compatibility Kit)。這個TCK工具通過執行成千上萬的測試用例來驗證一個JVM是否符合規範,這些測試裏面包含了各種非法的class文件。只有通過了TCK的測試的JVM才能稱作JVM。
和TCK相似,有一個組織JCP(Java Community Process; //jcp.org)負責Java規範以及新的Java技術規範。對於JCP而言,如果要完成一項Java規範請求(Java Specification Request, JSR)的話,需要具備規範文檔,可參考的實現以及通過TCK測試。任何人如果想使用一項申請JSR的新技術的話,他要麼使用RI提供許可的實現,要麼自己實現一個並且保證通過TCK的測試。
JVM 結構
Java程序的執行過程如下圖所示:
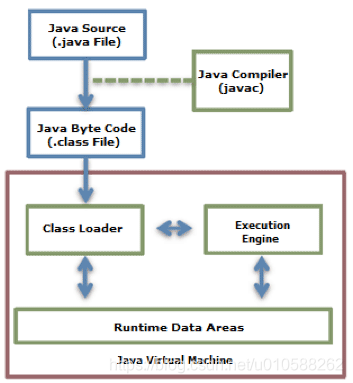
圖1: Java代碼執行過程
類裝載器負責裝載編譯後的位元組碼,並加載到運行時數據區(Runtime Data Area),然後執行引擎執行會執行這些位元組碼。
類加載
Java提供了動態的裝載特性;它會在運行時的第一次引用到一個class的時候對它進行裝載和鏈接,而不是在編譯期進行。JVM的類裝載器負責動態裝載。Java類裝載器有如下幾個特點:
- 層次結構: Java的類加載器是按父子關係的層次結構組織的。Boostrap類加載器處於層次結構的頂層,是所有類加載器的父類。
- 委派模式: 基於類加載器的層次組織結構,類加載器之間是可以進行委派的。當一個類需要被加載,會先去請求父加載器判斷該類是否已經被加載。如果父類加器已加載了該類,那它就可以直接使用而無需再次加載。如果尚未加載,才需要當前類加載器來加載此類。
- 可見性限制: 子類加載器可以從父類加載器中獲取類,反之則不行。一個子裝載器可以查找父裝載器中的類,但是一個父裝載器不能查找子裝載器里的類。
- 不能卸載: 類裝載器可以裝載一個類但是不可以卸載它,不過可以刪除當前的類裝載器,然後創建一個新的類裝載器。
Each class loader has its namespace that stores the loaded classes. When a class loader loads a class, it searches the class based on FQCN (Fully Qualified Class Name) stored in the namespace to check whether or not the class has been already loaded. Even if the class has an identical FQCN but a different namespace, it is regarded as a different class. A different namespace means that the class has been loaded by another class loader.
每個類加載器都有自己的空間,用於存儲其加載的類信息。當類加載器需要加載一個類時,它通過FQCN)(Fully Quanlified Class Name: 全限定類名)的方式先在自己的存儲空間中檢測此類是否已存在。在JVM中,即便具有相同FQCN的類,如果出現在了兩個不同的類加載器空間中,它們也會被認為是不同的。存在於不同的空間意味着類是由不同的加載器加載的。
下圖解釋了類加載器的委派模型:
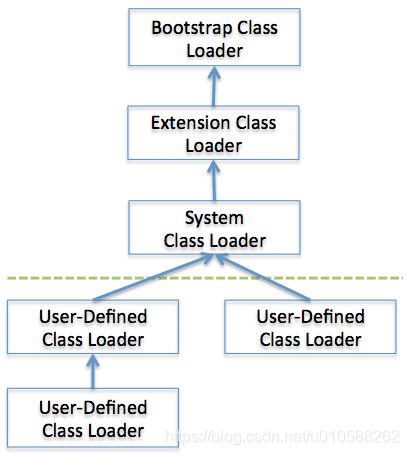
圖2: 類加載器的委派模型
When a class loader is requested for class load, it checks whether or not the class exists in the class loader cache, the parent class loader, and itself, in the order listed. In short, it checks whether or not the class has been loaded in the class loader cache. If not, it checks the parent class loader. If the class is not found in the bootstrap class loader, the requested class loader searches for the class in the file system.
當JVM請示類加載器加載一個類時,加載器總是按照從類加載器緩存、父類加載器以及自己加載器的順序查找和加載類。也就是說加載器會先從緩存中判斷此類是否已存在,如果不存在就請示父類加載器判斷是否存在,如果直到Bootstrap類加載器都不存在該類,那麼當前類加載器就會從文件系統中找到類文件進行加載。
- Bootstrap加載器:
這個類裝載器是在JVM啟動的時候創建的。它負責裝載Java API,包含Object對象。和其他的類裝載器不同的地方在於這個裝載器是通過native code來實現的,而不是用Java代碼。 - 擴展加載器(Extension class loader): 擴展加載器用於加載除基本Java APIs以外擴展類。也用於加載各種安全擴展功能。
- 系統加載器(System class loader): 如果說Bootstrap和Extension加載器用於加載JVM運行時組件,那麼系統加載器加載的則是應用程序相關的類。它會加載用戶指定的CLASSPATH里的類。
If the bootstrap class loader and the extension class loader load the JVM components, the system class loader loads the application classes. It loads the class in the $CLASSPATH specified by the user. - 用戶自定義加載器: 這個是由用戶的程序代碼創建的類加載器。This is a class loader that an application user directly creates on the code.
Frameworks such as Web application server (WAS) use it to make Web applications and enterprise applications run independently. In other words, this guarantees the independence of applications through class loader delegation model. Such a WAS class loader structure uses a hierarchical structure that is slightly different for each WAS vendor.
像Web應用服務器(WAS: Web Application Server)等框架通過使用用戶自定義加載器使Web應用和企業級應用可以隔離開在各自的類加載空間獨自運行。也就是說可以通過類加載器的委派模式來保證應用的獨立性。不同的WAS在自定義類加載器時會有略微不同,但都不外乎使用加載器的層次結構原理。
如果一個類加載器發現了一個未加載的類,則該類的加載和鏈接過程如下圖:
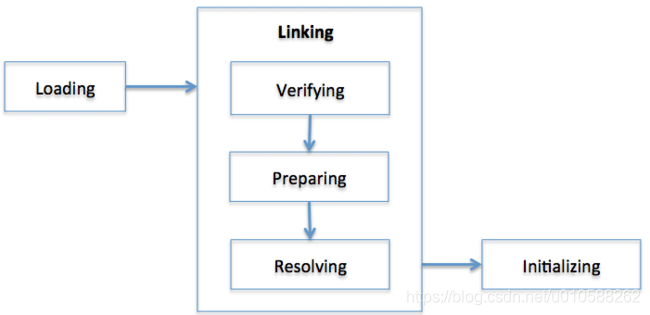
圖3: 類加載步驟
每一步的具體描述如下:
- 加載(Loading): 從.class文件中獲取類並載入到JVM內存空間。
- 驗證(Verifying): 檢查讀入的結構是否符合Java語言規範以及JVM規範的描述。這是類裝載中最複雜的過程,並且花費的時間也是最長的。
Most cases of the JVM TCK test cases are to test whether or not a verification error occurs by loading wrong classes.
並且JVM TCK工具的大部分場景的用例也用來測試在裝載錯誤的類的時候是否會驗證失敗。 - 準備(Preparing): 分配一個結構用來存儲類信息,這個結構中包含了類中定義的成員變量,方法和接口的信息。
- 解析(Resolving): 把類常量池中所有的符號引用轉為直接引用。Change all symbolic references in the constant pool of the class to direct references.
- 初始化(Initializing): 把類中的變量初始化成合適的值。執行靜態初始化程序,把靜態變量初始化成指定的值。 Initialize the class variables to proper values. Execute the static initializers and initialize the static fields to the configured values.
JVM規範定義了上面的幾個任務,不過它允許具體執行的時候能夠有些靈活的變動。
運行時數據區
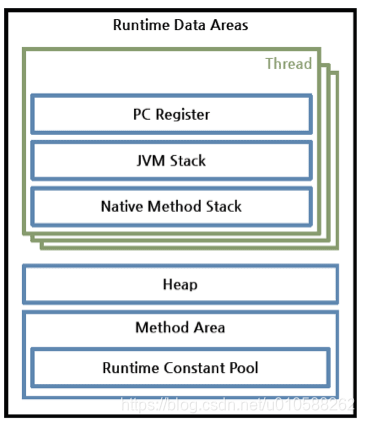
圖4: 運行時數據區(Runtime Data Areas)
Runtime Data Areas are the memory areas 【which is】assigned(分配) when the JVM program runs on the OS. The runtime data areas can be divided into 6 areas. Of the six, one PC Register, JVM Stack, and Native Method Stack are created for one thread. Heap, Method Area, and Runtime Constant Pool are shared by all threads.
運行時數據區域是在操作系統上運行JVM程序時分配的內存區域。運行時數據區域可分為6個區域。在這6個區域中,一個PC Register,JVM stack 以及Native Method Statck都是為每一個線程創建的,Heap,Method Area以及Runtime Constant Pool都是被所有線程共享的。
PC 寄存器(PC register)::
One PC (Program Counter) register exists for one thread, and is created when the thread starts. PC register has the address of a JVM instruction being executed now.
每個線程都會有一個PC(Program Counter)寄存器,並跟隨線程的啟動而創建。PC寄存器里保存有當前正在執行的JVM指令的地址。
JVM 棧(JVM stack):
One JVM stack exists for one thread, and is created when the thread starts. It is a stack that saves the struct (Stack Frame). The JVM just pushes or pops the stack frame to the JVM stack.
If any exception occurs, provides programmatic access to the stack trace information printed by printStackTrace(). Returns an array of stack trace elements, each representing one stack frame
每個線程啟動的時候,都會創建一個JVM stack。它是用來保存棧幀(Stack Frame)。JVM只會在JVM stack上對棧幀進行push和pop的操作。如果出現了異常,使用printStackTrace()方法。可以獲取一個棧跟蹤元素數組,每個元素表示一個棧幀。
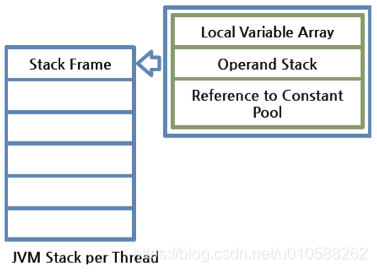
圖5: JVM棧結構
- 1.- 棧幀(stack frame):
One stack frame is created whenever a method is executed in the JVM, and the stack frame is added to the JVM stack of the thread. When the method is ended, the stack frame is removed.
Each stack frame has the reference for local variable array, Operand stack, and runtime constant pool of a class where the method being executed belongs.
在JVM中一旦有方法執行,JVM就會為之創建一個棧幀,並把其添加到當前線程的JVM棧中。當方法運行結束時,棧幀也會相應的從JVM棧中移除。
Each stack frame has the reference for local variable array, Operand stack, and runtime constant pool of a class where the method being executed belongs
每個棧幀里都包含有當前正在執行的方法所屬類的局部變量數組 的引用,操作數棧 的引用,以及運行時常量池 的引用
The size of local variable array and Operand stack is determined while compiling. Therefore, the size of stack frame is fixed according to the method.
局部變量數組的和操作數棧的大小都是在編譯時確定的。因此,一個方法的棧幀的大小也是固定不變的。
-
2.- 局部變量數組(Local variable array ):
It has an index starting from 0. 0 is the reference of a class instance where the method belongs. From 1, the parameters sent to the method are saved. After the method parameters, the local variables of the method are saved.
這個數組的索引從0開始。索引為0的變量表示這個方法所屬的類的實例。從1開始,首先存放的是傳給該方法的參數,在參數後面保存的是方法的局部變量。 -
3 – 操作數棧(Operand stack ):
An actual workspace of a method. Each method exchanges data between the Operand stack and the local variable array, and pushes or pops other method invoke results. The necessary size of the Operand stack space can be determined during compiling. Therefore, the size of the Operand stack can also be determined during compiling.
方法實際運行的工作空間。每個方法都在操作數棧和局部變量數組之間交換數據,並把調用其它方法的結果從棧中彈或壓入。在編譯時,編譯器就能計算出操作數棧所需的內存大小,因此操作數棧的大小在編譯時也是確定的。
本地方法棧( Native method stack):
A stack for native code written in a language other than Java. In other words, it is a stack used to execute C/C++ codes invoked through JNI (Java Native Interface). According to the language, a C stack or C++ stack is created.
A stack for native code(不用Java語言編寫的代碼) 。它是通過調用JNI(Java Native Interface Java本地接口)去執行C/C++代碼。 According to the language,一個C堆棧或者C++堆棧會被創建。
方法區(Method area):
The method area is shared by all threads, created when the JVM starts.
It (The method area)stores runtime constant pool, field and method information, static variable,
and method bytecode for each of the classes and interfaces read by the JVM.
The method area can be implemented in various formats by JVM vendor.
Oracle Hotspot JVM calls it (指的是method area)Permanent Area or Permanent Generation (PermGen). The garbage collection for the method area is optional for each JVM vendor.
方法區是所有線程共享的,它是在JVM啟動的時候創建的。
它保存所有被JVM加載的類和接口的 運行時常量池,成員變量以及方法的信息,靜態變量以及方法的位元組碼。
JVM的提供者可以通過不同的方式來實現方法區。
在Oracle 的HotSpot JVM里,方法區被稱為Permanent Area(永久區)或者Permanent Generation(PermGen)。
JVM規範並對方法區的垃圾回收未做強制限定,因此對於JVM vendor(提供者)來說,方法區的垃圾回收是可選操作。
運行時常量池( Runtime constant pool ):
An area that corresponds to the constant_pool table in the class file format. This area is included in the method area;
however, it plays the most core role in JVM operation. Therefore, the JVM specification separately describes its importance.
As well as the constant of each class and interface, it contains all references for methods and fields. In short, when a method or field is referred to, the JVM searches the actual address of the method or field on the memory by using the runtime constant pool.
這個區域和class文件里的the constant_pool table是相對應的。這個區域是包含在method area里的。
不過,對於JVM的操作而言,它是一個核心的角色。因此在JVM規範里特別提到了它的重要性。
除了包含每個類和接口的常量( the constant of each class and interface),它也包含了所有方法和變量的引用( all references for methods and fields.)。簡而言之,當一個方法或者變量被引用時,JVM通過運行時常量區來查找方法或者變量在內存里的實際地址(the JVM searches the actual address of the method or field on the memory by using the runtime constant pool.)。
這部分空間雖然存在於方法區內,但卻在JVM操作中扮演着舉足輕重的角色,因此JVM規範單獨把這一部分拿出來描述。除了每個類或接口中定義的常量,它還包含了所有對方法和字段的引用。因此當需要一個方法或字段時,JVM通過運行時常量池中的信息從內存空間中來查找其相應的實際地址。
堆(Heap):
A space that stores instances or objects, and is a target of garbage collection. This space is most frequently mentioned when discussing issues such as JVM performance. JVM vendors can determine how to configure the heap or not to collect garbage.
堆中存儲着所有的類實例或對象,而且它是垃圾回收的主要目標。當涉及到類似於JVM性能之類的問題時,當討論類似於JVM性能之類的問題時,它經常會被提及。JVM提供者可以決定劃分堆空間或者不執行垃圾回收。
現在我們再會過頭來看看之前反彙編的位元組碼:
public void add(java.lang.String);
Code:
0: aload_0
1: getfield #15; //Field admin:Lcom/nhn/user/UserAdmin;
4: aload_1
5: invokevirtual #23; //Method com/nhn/user/UserAdmin.addUser:(Ljava/lang/String;)Lcom/nhn/user/User;
8: pop
9: return
// UserService.java
…
public void add(String userName) {
admin.addUser(userName);
}
Comparing the disassembled code and the assembly code of the x86 architecture that we sometimes see, the two have a similar format, OpCode;
however, there is a difference in that Java Bytecode does not write register name, memory addressor, or offset on the Operand.
As described before, the JVM uses stack. Therefore, it does not use register, unlike the x86 architecture that uses registers,
and it uses index numbers such as 15 and 23 instead of memory addresses since it manages the memory by itself. The 15 and 23 are the indexes of the constant pool of the current class (here, UserService class)
In short, the JVM creates a constant pool for each class, and the pool stores the reference of the actual target.
把上面的反彙編代碼和我們平時所見的x86架構的彙編代碼相比較,我們會發現這兩者的結構有點相似,都使用了操作碼;
不過,有一點不同的地方是Java位元組碼並不會在操作數里寫入寄存器的名稱、內存地址或者偏移量。
之前已經說過,JVM用的是棧,它不會使用寄存器。和使用寄存器的x86架構不同,它自己負責內存的管理。它用索引例如15和23來代替實際的內存地址。15和23都是當前類(這裡是UserService類)的常量池裡的索引。
簡而言之,JVM為每個類創建了一個常量池,並且這個常量池裡保存了真實對象的引用。
Each row of the disassembled code is interpreted as follows.
上面每行代碼的解釋如下:
- aload_0:
Add the #0 index of the local variable array to the Operand stack. The #0 index of the local variable array is always this, the reference for the current class instance.
把局部變量數組中索引為#0的變量添加到操作數棧上。局部變量數組中索引#0所表示的變量是this,即是當前類實例對象的引用
- getfield /#15:
In the current class constant pool, add the #15 index to the Operand stack. UserAdmin admin field is added. Since the admin field is a class instance, a reference is added.
把當前類的常量池裡的索引為#15的變量添加到操作數棧。這裡添加的是UserAdmin的admin成員變量。因為admin變量是個類的實例,因此添加的是一個引用。
- aload_1:
Add the #1 index of the local variable array to the Operand stack. From the #1 index of the local variable array, it is a method parameter. Therefore, the reference of String userName sent while invoking add() is added.
把局部變量數組裡的索引為#1的變量添加到操作數棧。本地變量數組中從第1個位置開始的元素存儲着方法的參數。
因此,在調用add()方法的時候,會把userName指向的String的引用添加到操作數棧上。
- invokevirtual /#23:
Invoke the method corresponding to the #23 index in the current class constant pool. At this time, the reference added by using getfield and the parameter added by using aload_1 are sent to the method to invoke. When the method invocation is completed, add the return value to the Operand stack.
調用當前類的常量池裡的索引為#23的方法。這個時候,通過getfile添加到操作數棧上的引用和通過aload_1添加到操作數棧上的參數(parameter)都被傳給方法調用。當方法運行完成時,它的返回值結果會被添加到操作數棧上。
- pop:
Pop the return value of invoking by using invokevirtual from the Operand stack.
You can see that the code compiled by the previous library has no return value. In short, the previous has no return value, so there was no need to pop the return value from the stack.
把通過invokevirtual方法調用得到的結果從操作數棧中彈出。
在前面講述中使用之前類庫時沒有返回值,也就不需要把結果從操作數棧中彈出了。
- return: Complete the method. 方法完成。
下圖將幫助理解上面的文字解釋:
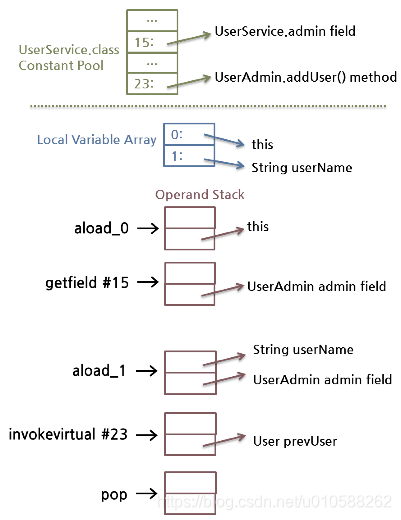
圖6: 從運行時數據區加載Java位元組碼示例
For reference, in this method, no local variable array has been changed.
So the figure above displays the changes in Operand stack only. However, in most cases, local variable array is also changed.
Data transfer between the local variable array and the Operand stack is made by using a lot of load instructions (aload, iload) and store instructions (astore, istore).
順便提一下,在這個方法里,局部變量數組沒有被修改。所以上圖只顯示了操作數棧的變化。不過,大部分的情況下,局部變量數組也是會改變的。
局部變量數組和操作數棧之間的數據傳輸是使用通過大量的load指令(aload,iload)和store指令(astore,istore)來實現的。
In this figure, we have checked the brief description of the runtime constant pool and the JVM stack. When the JVM runs, each class instance will be assigned to the heap, and class information including User, UserAdmin, UserService, and String will be stored in the method area.
在這個圖裡,我們簡單驗證了運行時常量池和JVM棧的描述。當JVM運行的時候,每個類的實例都會在堆上進行分配,User,UserAdmin,UserService以及String等類的信息都會被存儲在方法區。
執行引擎
The bytecode that is assigned to the runtime data areas in the JVM via class loader is executed by the execution engine. The execution engine reads the Java Bytecode in the unit of instruction. It is like a CPU executing the machine command one by one. Each command of the bytecode consists of a 1-byte OpCode and additional Operand. The execution engine gets one OpCode and execute task with the Operand, and then executes the next OpCode.
通過類裝載器裝載的,被分配到JVM的運行時數據區的位元組碼會被執行引擎執行。執行引擎在指令單元讀取Java位元組碼。(它就像一個CPU一樣,一條一條地執行機器指令。)每個位元組碼指令都由一個1位元組的操作碼和附加的操作數組成。執行引擎取得一個操作碼,然後根據操作數來執行任務,完成後就繼續執行下一條操作碼。
But the Java Bytecode is written in a language that a human can understand, rather than in the language that the machine directly executes. Therefore, the execution engine must change the bytecode to the language that can be executed by the machine in the JVM. The bytecode can be changed to the suitable language in one of two ways.
儘管如此,Java位元組碼還是以一種可以理解的語言編寫的,而不是用機器可以直接執行的語言。因此,JVM的執行引擎必須把位元組碼轉換成直接被機器(the machine in the JVM)執行的機器碼。位元組碼可以通過以下兩種方式轉換成合適的語言。
ps://www.cnblogs.com/chanshuyi/p/jvm_serial_04_from_source_code_to_machine_code.html 這邊有更加詳細的介紹
當源代碼轉化為位元組碼之後,其實要運行程序,有兩種選擇。一種是使用 Java 解釋器解釋執行位元組碼,另一種則是使用 JIT 編譯器將位元組碼轉化為本地機器代碼。
- 解釋器(Interpreter):
Reads, interprets and executes the bytecode instructions one by one. As it interprets and executes instructions one by one, it can quickly interpret one bytecode, but slowly executes the interpreted result. This is the disadvantage of the interpret language. The ‘language’ called Bytecode basically runs like an interpreter.
一條一條地讀取,解釋並且執行位元組碼指令。因為它一條一條地解釋和執行指令,所以它可以很快地解釋位元組碼,但是執行起來會比較慢。這是解釋執行的語言的一個缺點。位元組碼這種「語言」基本來說是解釋執行的。
- 即時編譯器(JIT: Just-In-Time):
The JIT compiler has been introduced to compensate for the disadvantages of the interpreter. The execution engine runs as an interpreter first, and at the appropriate time, the JIT compiler compiles the entire bytecode to change it to native code. After that, the execution engine no longer interprets the method, but directly executes using native code. Execution in native code is much faster than interpreting instructions one by one. The compiled code can be executed quickly since the native code is stored in the cache.
即時編譯器被引入用來彌補解釋器的缺點。執行引擎首先按照解釋執行的方式來執行,然後在合適的時候,即時編譯器把整段位元組碼編譯成本地代碼。然後,執行引擎就沒有必要再去解釋執行方法了,它可以直接通過本地代碼去執行它。執行本地代碼比一條一條進行解釋執行的速度快很多。編譯後的代碼可以執行的很快,因為本地代碼是保存在緩存里的。
However, it takes more time for JIT compiler to compile the code than for the interpreter to interpret the code one by one. Therefore, if the code is to be executed just once, it is better to interpret it instead of compiling. Therefore, the JVMs that use the JIT compiler internally check how frequently the method is executed and compile the method only when the frequency is higher than a certain level.
不過,用JIT編譯器來編譯代碼所花的時間要比用解釋器去一條條解釋執行花的時間要多。因此,如果代碼只被執行一次的話,那麼最好還是解釋執行而不是編譯後再執行。因此,內置了JIT編譯器的JVM都會檢查方法的執行頻率,如果一個方法的執行頻率超過一個特定的值的話,那麼這個方法就會被編譯成本地代碼。
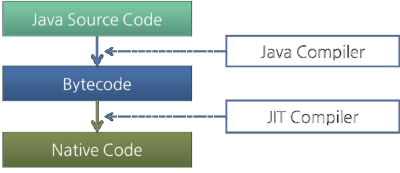
圖7: Java編譯器和即時編譯器
How the execution engine runs is not defined in the JVM specifications. Therefore, JVM vendors improve their execution engines using various techniques, and introduce various types of JIT compilers.
JVM規範沒有定義執行引擎該如何去執行。因此,JVM的提供者通過使用不同的技術以及不同類型的JIT編譯器來提高執行引擎的效率。
Most JIT compilers run as shown in the figure below:
大部分的即時編譯器運行流程如下圖:
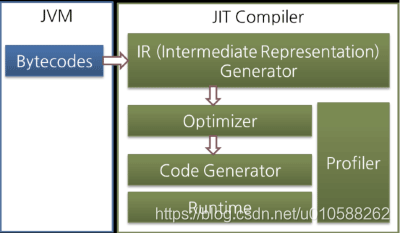
圖8: 即時編譯器
The JIT compiler converts the bytecode to an intermediate-level expression, IR (Intermediate Representation), to execute optimization, and then converts the expression to native code.
即時編譯器先把位元組碼轉為一種中間形式的表達式(IR: Itermediate Representation),來進行優化,然後再把這種表示轉換成本地代碼
Oracle Hotspot VM uses a JIT compiler called Hotspot Compiler. It is called Hotspot because Hotspot Compiler searches the ‘Hotspot’ that requires compiling with the highest priority through profiling, and then it compiles the hotspot to native code. If the method that has the bytecode compiled is no longer frequently invoked, in other words, if the method is not the hotspot any more, the Hotspot VM removes the native code from the cache and runs in interpreter mode. The Hotspot VM is divided into the Server VM and the Client VM, and the two VMs use different JIT compilers.
Oracle Hotspot VM使用一種叫做Hotspot Compiler 的JIT編譯器。它之所以被稱作」Hotspot「是因為Hotspot Compilerr會根據剖析找到具有更高編譯優先級的熱點代碼,然後把熱點代碼編譯成本地代碼。如果已經被編譯成本地代碼的位元組碼不再被頻繁調用了,換句話說,這個方法不再是熱點了,Hotspot VM會把這些本地代碼從緩存中刪除並對其再次使用解釋器模式執行。Hotspot VM分為Server VM和Client VM兩種,這兩種VM使用不同的JIT編譯器。
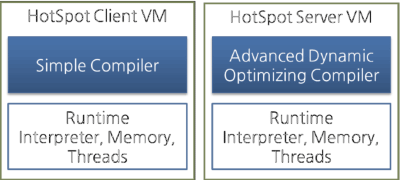
圖9: Hotspot ClientVM 和Server VM
The client VM and the server VM use an identical runtime; however, they use different JIT compilers, as shown in the above figure.
Advanced Dynamic Optimizing Compiler used by the server VM uses more complex and diverse (多樣的)performance optimization techniques.
Client VM 和Server VM使用完全相同的運行時,不過如上圖所示,它們所使用的JIT編譯器是不同的。Server VM用的是更高級的動態優化編譯器,這個編譯器使用了更加複雜並且更多種類的性能優化技術。
IBM JVM has introduced AOT (Ahead-Of-Time) Compiler from IBM JDK 6 as well as the JIT compiler. This means that many JVMs share the native code (which is )compiled through the shared cache.
In short, the code that has been already compiled through the AOT compiler can be used by another JVM without compiling. In addition, IBM JVM provides a fast way of execution by pre-compiling code to JXE (Java EXecutable) file format using the AOT compiler.
IBM 在IBM JDK 6里不僅引入了JIT編譯器,它同時還引入了AOT(Ahead-Of-Time)編譯器。它使得多個JVM可以通過共享緩存來共享編譯過的本地代碼。
簡而言之,通過AOT編譯器編譯過的代碼可以直接被其他JVM使用。除此之外,IBM JVM通過使用AOT編譯器通過提前把代碼編譯器成JXE(Java EXecutable)文件格式從而提供了一種快速執行代碼的方式。
Most Java performance improvement is accomplished by improving the execution engine. As well as the JIT compiler, various optimization techniques are being introduced so the JVM performance can be continuously improved. The biggest difference between the initial JVM and the latest JVM is the execution engine.
大多數的Java性能提升都是通過優化執行引擎的性能實現的。像即時編譯等各種優化技術被不斷的引入,從而使得JVM性能得到了持續的優化和提升。老舊的JVM與最新的JVM之間最大的差異其實就來自於執行引擎。
Hotspot compiler has been introduced to Oracle Hotspot VM from version 1.3, and JIT compiler has been introduced to Dalvik VM from Android 2.2.
Hotspot編譯器從Java 1.3開始便引入到了Oracle Hotspot VM中,而即時編譯器從Android 2.2開始便被引入到了Android Dalvik VM中。
Note
The technique in which an intermediate language such as bytecode is introduced, the VM executes the bytecode, and the JIT compiler improves the performance of JVM is also commonly used in other languages that have introduced intermediate languages. For Microsoft’s .Net, CLR (Common Language Runtime), a kind of VM, executes a kind of bytecode, called CIL (Common Intermediate Language). CLR provides the AOT compiler as well as the JIT compiler. Therefore, if source code is written in C# or VB.NET and compiled, the compiler creates CIL and the CIL is executed on the CLR with the JIT compiler. The CLR uses the garbage collection and runs as a stack machine like the JVM.
注釋
引入一種中間語言,例如位元組碼,虛擬機執行位元組碼,並且通過JIT編譯器來提升JVM的性能的這種技術以及廣泛應用在使用中間語言的編程語言上。例如微軟的.Net,CLR(Common Language Runtime 公共語言運行時),也是一種VM,它執行一種被稱作CIL(Common Intermediate Language)的位元組碼。CLR提供了AOT編譯器和JIT編譯器。因此,用C#或者VB.NET編寫的源代碼被編譯後,編譯器會生成CIL並且CIL會執行在有JIT編譯器的CLR上。CLR和JVM相似,它也有垃圾回收機制,並且也是基於棧運行。
Java 虛擬機規範,Java SE 第7版
2011年7月28日,Oracle發佈了Java SE的第7個版本,並且把JVM規也更新到了相應的版本。在1999年發佈《The Java Virtual Machine Specification,Second Edition》後,Oracle花了12年來發佈這個更新的版本。這個更新的版本包含了這12年來累積的眾多變化以及修改,並且更加細緻地對規範進行了描述。此外,它還反映了《The Java Language Specificaion,Java SE 7 Edition》里的內容。主要的變化總結如下:
- 來自Java SE 5.0里的泛型,支持可變參數的方法
- 從Java SE 6以來,位元組碼校驗的處理技術所發生的改變
- 添加invokedynamic指令以及class文件對於該指令的支持
- 刪除了關於Java語言概念的內容,並且指引讀者去參考Java語言規範
- 刪除關於Java線程和鎖的描述,並且把它們移到Java語言規範里
最大的改變是添加了invokedynamic指令。也就是說JVM的內部指令集做了修改,使得JVM開始支持動態類型的語言,這種語言的類型不是固定的,例如腳本語言以及來自Java SE 7里的Java語言。之前沒有被用到的操作碼186被分配給新指令invokedynamic,而且class文件格式里也添加了新的內容來支持invokedynamic指令。
Java SE 7的編譯器生成的class文件的版本號是51.0。Java SE 6的是50.0。class文件的格式變動比較大,因此,51.0版本的class文件不能夠在Java SE 6的虛擬機上執行。
儘管有了這麼多的變動,但是Java方法的65535位元組的限制還是沒有被去掉。除非class文件的格式徹底改變,否者這個限制將來也是不可能去掉的。
值得說明的是,Oracle Java SE 7 VM支持G1這種新的垃圾回收機制,不過,它被限制在Oracle JVM上,因此,JVM本身對於垃圾回收的實現不做任何限制。也因此,在JVM規範里沒有對它進行描述。
String in switch Statements
Java SE 7 adds various grammars and features. However, compared to the various changes in language of Java SE 7, there are not so many changes in the JVM. So, how can the new features of the Java SE 7 be implemented? We will see how String in switch Statements (a function to add a string to a switch() statement as a comparison) has been implemented in Java SE 7 by disassembling it.
For example, the following code has been written.
Java SE 7里添加了很多新的語法和特性。不過,在Java SE 7的版本里,相對於語言本身而言,JVM沒有多少的改變。那麼,這些新的語言特性是怎麼來實現的呢?我們通過反彙編的方式來看看switch語句里的String(把字符串作為switch()語句的比較對象)是怎麼實現的?
例如,下面的代碼:
// SwitchTest
public class SwitchTest {
public int doSwitch(String str) {
switch (str) {
case "abc": return 1;
case "123": return 2;
default: return 0;
}
}
}
Since it is a new function of Java SE 7, it cannot be compiled using the Java compiler for Java SE 6 or lower versions. Compile it using the javac of Java SE 7. The following screen is the compiling result printed by using javap –c.
因為這是Java SE 7的一個新特性,所以它不能在Java SE 6或者更低版本的編譯器上來編譯。用Java SE 7的javac來編譯。下面是通過javap -c來反編譯後的結果。
C:Test>javap -c SwitchTest.classCompiled from "SwitchTest.java"
public class SwitchTest {
public SwitchTest();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return public int doSwitch(java.lang.String);
Code:
0: aload_1
1: astore_2
2: iconst_m1
3: istore_3
4: aload_2
5: invokevirtual #2 // Method java/lang/String.hashCode:()I
8: lookupswitch { // 2
48690: 50
96354: 36
default: 61
}
36: aload_2
37: ldc #3 // String abc
39: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
42: ifeq 61
45: iconst_0
46: istore_3
47: goto 61
50: aload_2
51: ldc #5 // String 123
53: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
56: ifeq 61
59: iconst_1
60: istore_3
61: iload_3
62: lookupswitch { // 2
0: 88
1: 90
default: 92
}
88: iconst_1
89: ireturn
90: iconst_2
91: ireturn
92: iconst_0
93: ireturn
A significantly longer bytecode than the Java source code has been created. First, you can see that lookupswitch instruction has been used for switch() statement in Java bytecode.
However, two lookupswitch instructions have been used, not the one lookupswitch instruction.
When disassembling the case in which int has been added to switch() statement, only one lookupswitch instruction has been used.
This means that the switch() statement has been divided into two statements to process the string.
See the annotation of the #5, #39, and #53 byte instructions to see how the switch() statement has processed the string.
生成的位元組碼的長度比Java源碼長多了。
首先,你可以看到位元組碼里用lookupswitch指令來實現switch()語句。
不過,這裡使用了兩個lookupswitch指令,而不是一個。
如果反編譯的是針對Int的switch()語句的話,位元組碼里只會使用一個lookupswitch指令。
也就是說,針對string的switch語句被分成用兩個語句來實現。
請參閱#5、#39和#53位元組指令的注釋,以了解switch()語句如何處理字符串。
In the #5 and #8 byte, first, hashCode() method has been executed and switch(int) has been executed by using the result of executing hashCode() method.
在#5和#8位元組處,首先是調用了hashCode()方法,然後它作為參數調用了switch(int)。
In the braces of the lookupswitch instruction, branch is made to the different location according to the hashCode result value. String “abc” is hashCode result value 96354, and is moved to #36 byte. String “123” is hashCode result value 48690, and is moved to #50 byte.
在lookupswitch的指令里,根據hashCode的結果進行不同的分支跳轉。字符串「abc”的hashCode是96354,它會跳轉到#36處。字符串」123「的hashCode是48690,它會跳轉到#50處。
In the #36, #37, #39, and #42 bytes, you can see that the value of the str variable received as an argument is compared using the String “abc” and the equals() method. If the results are identical, ‘0’ is inserted to the #3 index of the local variable array, and the string is moved to the #61 byte.
在第#36,#37,#39,以及#42位元組的地方,你可以看見str參數被equals()方法來和字符串「abc」進行比較。如果比較的結果是相等的話,『0』會被放入到局部變量數組的索引為#3的位置,然後跳轉到第#61位元組。
In this way, in the #50, #51, #53, and #56 bytes, you can see that the value of the str variable received as an argument is compared by using the String “123” and the equals() method. If the results are identical, ‘1’ is inserted to the #3 index of the local variable array and the string is moved to the #61 byte.
在第#50,#51,#53,以及#56位元組的地方,你可以看見str參數被equals()方法來和字符串「123」進行比較。如果比較的結果是相等的話,’1’會被放入到局部變量數組的索引為#3的位置,然後跳轉到第#61位元組。
In the #61 and #62 bytes, the value of the #3 index of the local variable array, i.e., ‘0’, ‘1’, or any other value, is lookupswitched and branched.
在第#61和#62位元組的地方,局部變量數組裡索引為#3的值,這裡是’0’,『1』或者其他的值,被lookupswitch用來進行搜索並進行相應的分支跳轉。
In other words, in Java code, the value of the str variable received as the switch() argument is compared using the hashCode() method and the equals() method. With the result int value, switch() is executed.
換句話來說,在Java代碼里的用來作為switch()的參數的字符串str變量是通過hashCode()和equals()方法來進行比較,然後根據比較的結果,來執行swtich()語句。
In this result, the compiled bytecode is not different from the previous JVM specifications. The new feature of Java SE 7, String in switch is processed by the Java compiler, not by the JVM itself. In this way, other new features of Java SE 7 will also be processed by the Java compiler.
在這個結果里,編譯後的位元組碼和之前版本的JVM規範沒有不兼容的地方。Java SE 7的這個用字符串作為switch參數的特性是通過Java編譯器來處理的,而不是通過JVM來支持的。通過這種方式還可以把其他的Java SE 7的新特性也通過Java編譯器來實現。
結束語
我不認為為了使用好Java必須去了解Java底層的實現。許多沒有深入理解JVM的開發者也開發出了很多非常好的應用和類庫。不過,如果你更加理解JVM的話,你就會更加理解Java,這樣你會有助於你處理類似於我們前面的案例中的問題。
除了這篇文章里提到的,JVM還是用了其他的很多特性和技術。JVM規範提供了是一種擴展性很強的規範,這樣就使得JVM的提供者可以選擇更多的技術來提高性能。值得特別說明的一點是,垃圾回收技術被大多數使用虛擬機的語言所使用。不過,由於這個已經在很多地方有更加專業的研究,我這篇文章就沒有對它進行深入講解了。


