DQN(Deep Q-learning)入門教程(五)之DQN介紹
簡介
DQN——Deep Q-learning。在上一篇博客DQN(Deep Q-learning)入門教程(四)之Q-learning Play Flappy Bird 中,我們使用Q-Table來儲存state與action之間的q值,那麼這樣有什麼不足呢?我們可以將問題的稍微複雜化一點了,如果在環境中,State很多,然後Agent的動作也很多,那麼毋庸置疑Q-table將會變得很大很大(比如說下圍棋),又或者說如果環境的狀態是連續值而不是離散值,儘管我們可以將連續值進行離散化,但是又可能會導致q-table變得龐大,並且可能還有一個問題,如果某一個場景沒有訓練過,也就是說q-table中沒有儲存這個值,那麼當agent遇到這種情況時就會一臉懵逼。
這個時候我們聯想我們在神經網絡中學到的知識,我們可以將Q-table變成一個網絡模型,如下所示:(圖來自莫煩)
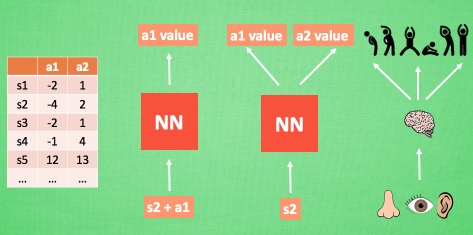
以前我們想獲得Q值,需要去q-table中進行查詢,但是現在我們只需要將狀態和動作(或者僅輸入狀態)即可獲得相對應的Q值,這樣,我們在內存中僅僅只需要保存神經網絡模型即可,簡單又省內存兒。
如果不了解神經網絡的話,可以先去看一看相關的知識,或者看一看我之前的博客,裏面包含了相關的介紹以及具體的實例使用:
- 數據挖掘入門系列教程(七點五)之神經網絡介紹
- 數據挖掘入門系列教程(八)之使用神經網絡(基於pybrain)識別數字手寫集MNIST
- 數據挖掘入門系列教程(十點五)之DNN介紹及公式推導
- 數據挖掘入門系列教程(十一)之keras入門使用以及構建DNN網絡識別MNIST
- 數據挖掘入門系列教程(十一點五)之CNN網絡介紹
- 數據挖掘入門系列教程(十二)之使用keras構建CNN網絡識別CIFAR10
神經網絡中有兩個很重要的概念:訓練,預測。預測我們很好理解,就是輸入一個狀態\(s_1\),它會返回對應的\(q(s_1,a_1),q(s_1,a_2) \cdots q(s_1,a_n)\),然後我們選擇最大值對應的Action就行了。那麼我們怎麼進行訓練呢?
神經網絡的訓練
在傳統的DNN or CNN網絡中,我們是已知訓練集,然後進多次訓練的。但是在強化學習中,訓練集是未知的,因為我們的要求是機器進行自我學習。換句話來說,就是神經網絡的更新是實時的,一邊進行遊戲得到數據集一邊使用數據進行訓練。
首先我們假設模型是下圖這樣的:輸入一個 \(s\) 返回不同動作對應的 \(q\) 值。

那麼我們進行訓練的時候,\(x\_train\) 即為狀態 \(s_1\) ,\(y\_train\) 則為 \(q(s_1,a_1),q(s_1,a_2) \cdots q(s_1,a_n)\)。🆗,現在的問題就回到了我們如何得到「真實」的 \(y\_train\) 。在DQN(Deep Q-learning)入門教程(三)之蒙特卡羅法算法與Q-learning算法中我們提到使用如下的公式來更新q-table:
\]
對應的圖如下所示:
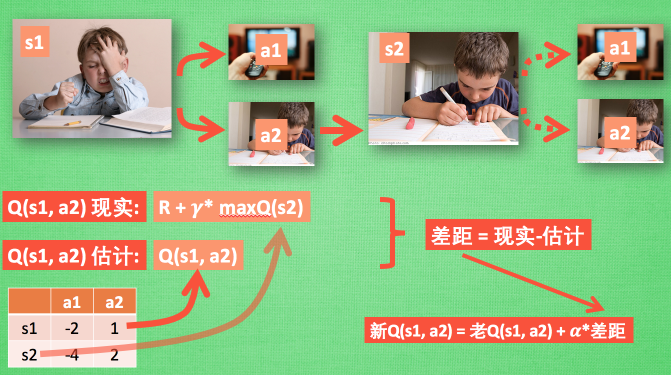
其中我們將\(Q(s_1,a_1) = R+\gamma^{*} \max Q(s_2)\)稱之為Q現實,q-table中的\(Q(s_1,a_1)\)稱之為Q估計。然後計算兩者差值,乘以學習率,然後進行更新Q-table。
我們可以想一想神經網絡中的反向傳播算法,在更新網絡權值的時候,我們是得到訓練集中的真實值和預測值之間的損失函數,然後再乘以一個學習率,再向前逐漸地更新網絡權值。這樣想一想,似乎兩者之間很相似。
在DQN中我們可以這樣做:
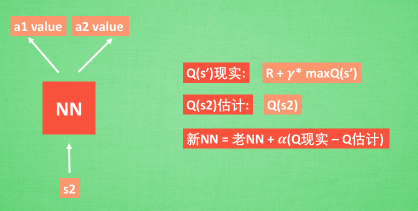
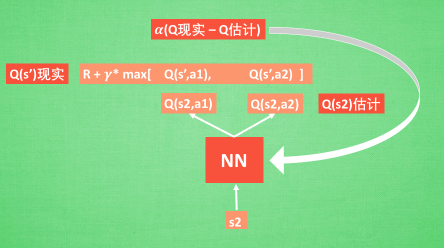
具體的使用,可以看一看下一篇博客的具體使用,用代碼來表達更加的絲滑。
經驗回放(Experience Replay)
經驗回放是一個很妙的方法。實際上,我們訓練神經網絡模型需要訓練很多次才可以得到一個比較好的模型,也就是說,數據會被重複的填入到神經網絡中訓練很多次。而經驗回放就是將數據進行保存,比如說agent再\(S_1\)狀執行動作\(a_1\)得到了\(r_1\)的獎勵,然後狀態轉移到了\(S_2\),則經驗池就會將\((S_1,a_1,r_1,S_2)\)進行保存,然後我們在訓練的時候,隨機從經驗池中抽取一定數量的數據來進行訓練。這樣就可以不停的優化網絡模型。
如果沒有經驗回放,我們則需要每次得到一個數據,則就進行訓練,我們每次訓練的內容都是目前的數據。但是,有了經驗回放,我們就可以從歷史數據中選擇數據進行訓練。

算法流程
下面介紹一下算法流程:
下面是來自Playing Atari with Deep Reinforcement Learning論文中算法流程:

下面是來自強化學習(八)價值函數的近似表示與Deep Q-Learning對算法的中文翻譯:

總結
以上便是DQN的介紹,實際上DQN還有很多優化算法,比如說 Nature DQN使用兩個Q網絡來減少相關性,Double DQN(DDQN,Nature DQN的優化)……
下一篇博客將具體的使用DQN進行訓練,同時DQN入門博客也就快結束了。


