疫情數據背後,聊聊數據分析平台變遷史
今年年初這場突如其來的疫情,讓我們早晨醒來打開手機的第一件事情,從刷朋友圈變成了刷每日最新的疫情數據。看看國內外新增確診人數/現存確診人數,看看國內外疫情分佈的地圖。各大新聞平台也因為快速上線疫情實時動態板塊,成為了大家了解疫情發展的陣地。
其實,在這背後是有着一個海量數據分析的架構平台做支撐。
對於很多企業的管理人員而言,這就是個很熟悉的T+1計算T日的報表場景。管理人員通過報表查看前一天企業的經營情況、庫存情況、用戶新增/流失情況等,用數據提高決策的準確率,減少誤判。
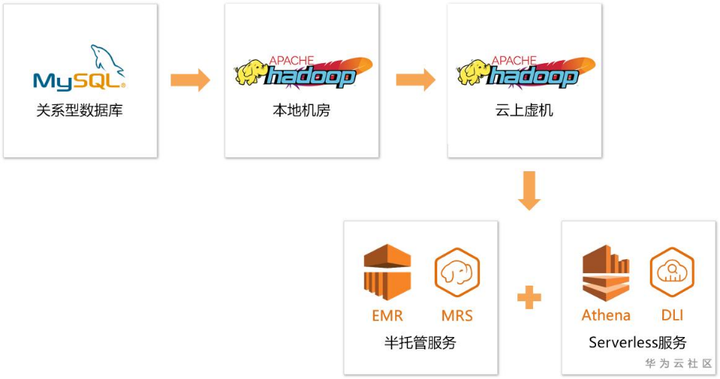
支撐這個典型報表場景的背後,是一整套海量數據計算的大數據架構。根據筆者這幾年幾十家各行各業企業的交流經驗來看,大致都經歷了如下幾個階段:
關係型數據庫
最初,企業的技術人員通常都是在業務數據庫相對空閑的時候(比如:晚上或者凌晨),直接在業務數據庫備庫進行一些數據分析查詢。隨着數據量的增多,一份邏輯上相同的數據,通常需要通過分庫分表的方式分佈在多個業務數據庫中。快速分析全量數據且不影響在線業務變成了一件極其複雜的事情。
線下自建Hadoop集群
2004年,Google發佈MapReduce論文。2006年,Apache Hadoop項目發佈。一些技術走在比較前沿的互聯網公司,開始使用Hadoop的分佈式處理能力解決數據分析中常見的數據量激增、查詢出不了結果等問題。
隨後幾年,越來越多的公司開始在線下機房搭建開源Hadoop集群,Hadoop生態相關的Kafka、Hive、Spark、Flink等都開始百花齊放,懂這些開源組件的技術人員在職場上也變得越來越吃香。
Hadoop架構最本質的優勢就是高擴展性,理論上,解決好節點間的通信、引入多管理節點,就能根據數據量無限擴展集群規模。集群規模跟需要參與計算的數據量(如:最近30天的數據)強相關,尤其像互聯網APP,可能一把就火了,但火上半個月用戶熱情冷卻,又下降到最初的業務量。線下機房採購服務器走流程,周期基本都是以月為單位,根本無法滿足快速變化的業務場景。
雲上自建Hadoop集群
當時,國外的亞馬遜已經誕生了幾年,國內的阿里也開始大刀闊斧進軍公有雲。技術團隊開始考慮公有雲上購買虛擬機部署Hadoop集群,雲上虛擬機按需使用的特點很好地解決了Hadoop集群對於節點伸縮能力的訴求。
雲上半託管大數據服務 & 雲上Serverless大數據服務
雲廠商也紛紛看到了企業對大數據分析的訴求,推出了雲上半託管大數據服務(如:AWS、華為雲的MRS等)。從單純虛擬機的性能競爭演變成了大數據管理軟件的易用性、大數據組件的性能等競爭。
雲上半託管大數據服務對於用戶來說,最核心的優勢就是使得安裝、升級、運維變得簡單化、可視化。同時,因為組件都是開源 + 自研優化,所以在接口上和開源保持一致,減少了業務的改造成本。
但云上半託管大數據服務對於用戶還是有一定的使用門檻(懂大數據運維和調優),而且需要長期持有一部分固定節點資源,存在一定的資源浪費。
注意到這些問題,AWS在2016年推出了基於Serverless架構的Athena服務。最初是主打使用標準SQL分析Amazon S3 中的數據。Athena沒有服務器,無需管理任何基礎設施,且只需為運行的查詢付費。
華為雲也在2017年推出了基於Serverless架構的數據湖探索DLI服務,完全兼容Apache Spark和Apache Flink生態,使用SQL就可輕鬆完成多個數據源的聯合分析。
2019年2月,加州大學伯克利分校發表了這篇名為《Cloud Programming Simplified: A Berkerley View on Serverless Computing》的論文,論文中認為Serverless模式主要有三個特點:
- 弱化了儲存和計算之間的聯繫。服務的儲存和計算被分開部署和收費,服務的儲存不再是它本身的一部分,而是演變成了獨立的雲服務,這使得計算變得無狀態化,更容易調度和縮擴容,同時也降低了數據丟失的風險。
- 代碼的執行不再需要手動分配資源。我們再也不需要為服務的運行指定需要的資源(比如使用幾台機器、多大的帶寬、多大的磁盤…),只需要提供一份代碼,剩下的交由Serverless平台去處理就行了
- 按使用量計費。Serverless按照服務的使用量(調用次數、時長等)進行計費,而不是像傳統的Serverless服務那樣,按照使用的資源(ECS實例、VM的規格等)計費。
在很長一段時間內,雲上半託管大數據服務和Serverless大數據服務一定是長期並存的狀態。
有大數據技術團隊的大企業通常會選擇半託管服務,一是因為使用習慣和自由度更像是開源Hadoop集群,二是因為技術團隊自身也希望在大數據技術上有積累以便不時之需。
大數據技能較弱,且對成本敏感的中小型企業會考慮Serverless服務,吸引他們的是Serverless大數據服務即開即用免運維 + 標準SQL能力,用JDBC連上Serverless服務,體驗十分接近傳統關係型數據庫。
Serverless大數據服務的未來
Serverless大數據服務要真正被大眾接受,對外需要做好宣傳,對內需要練好內功。Serverless概念從2018年才開始真正火起來,很多用戶一提到大數據,直觀還是想到自建Hadoop集群或者雲上半託管大數據服務。隨着K8S容器和微服務被更多的用戶接受和使用,Serverless大數據服務也在逐漸出現在技術人員選型的清單中。
內功修鍊上,Serverless大數據服務必須要解決好「安全」、「彈性」、「智能」、「易用」四個核心問題
安全
大數據領域,無論是SQL中的UDF還是用戶自己開發的應用程序,都存在會攻擊其它租戶的風險。當前想要解決這類安全問題的方法,不外乎沙箱隔離、安全容器隔離、物理隔離等這幾個方法。每一個方法對架構和資源利用率的挑戰都非常大。
彈性
Serverless大數據服務最初誕生的初衷就是讓用戶提交應用時,無需感知和指定具體的運行資源數。彈性分為兩個方面:一是彈性的速度,二是彈性的預測。
彈性的速度取決於底層物理資源池的大小和擴容算法、資源預熱的程度以及不同租戶間的資源搶佔機制。
彈性的預測可以從易到難分為幾類:最簡單的就是根據用戶定時規則進行彈性,優點是及時彈性,缺點也顯而易見用戶需要對業務比較了解;其次就是如果是周期性任務,服務可以通過收集歷史作業執行規律(作業數、資源利用率等),在下一次執行時根據歷史規律進行彈性;更進一步,通常大數據的任務都是拆分成多個邏輯相同的Task,根據資源量進行多輪調度。第一輪運行的時候,可以收集到單個Task的運行時長、CPU利用率等,第二輪就可以根據單個Task的信息,跟彈性的速度做個平衡,獲取最佳彈性策略。
智能
使用大數據組件,其實搭建、升級等都不算特別複雜的事情,真正複雜的是上百個參數的調優。Serverless大數據服務如果想要真正地吸引之前使用自建Hadoop集群的用戶,核心就是解決用戶最頭疼的調優問題。Serverless大數據服務根據用戶的業務及歷史執行情況,智能對服務參數及數據組織進行調優。最典型的幾個問題,比如:如何避免輸出過多小文件、如何切分合適的Reduce個數、如何根據查詢條件自動調整數據組織形式等。
易用
除了解決基本的部署、升級等運維相關的問題,真正做到免運維。在使用習慣上,相比雲上半託管大數據服務,Serverless大數據服務一定會有一個適應過程,我們要做的就是讓這個適應過程變得潛移默化。
- 基礎功能頁面的使用:如果跟微信一樣,做好界面易用性設計和功能的取捨,這個學習過程會在潛移默化中完成。
- 運維相關頁面的使用:一定要儘可能保持和開源一樣或者類似的頁面邏輯,比如:Spark UI。
- 作業操作腳本:包括作業的提交、作業的終止、狀態的查詢等,如果Serverless大數據服務是想搞定某個開源大數據框架的遷移場景,這一部分一定要全兼容開源習慣。
Serverless大數據服務有些是基於開源大數據框架深度優化,有些是純自研大數據框架。在應用開發的接口定義上,不管是哪種方式,對於從開源組件入門大數據的用戶來說,開源接口就是標準,保持和兼容開源接口是Serverless大數據服務的基礎。
總結
Serverless大數據服務是一種面向未來的形態。隨着逐個攻破當前存在的問題,它在大數據分析所佔的比重一定會逐年增加。真正把大數據分析變成跟水和電一樣隨取隨用,每個企業都能用得起的工具。


