第35次文章:數據庫簡單查詢
- 2019 年 10 月 8 日
- 筆記
本周學習的數據庫,有一種明顯的感覺,語法簡單,基本上不會有大段大段的代碼出現,簡簡單單的幾行代碼就可以完成我們需要實現的任務,或許是因為我們的任務比較初級吧!嘻嘻!
所以本周主要分享的是一些語法結構,如果每個語法都給出一個例子的話,這篇文章將會出奇的長。所以,小白對於比較生疏的一些語法,會給出一個具體案例進行講解,剩餘比較簡單的案例,各位小夥伴就自己摸索一下,很簡單的喲!
遇到什麼問題,想要和小白討論的話,可以在文章下面留言,或者直接添加微信號:javaxiaobaizhushou,與小白面對面交流呀!下面進入正式的分享啦!
緊接上周的內容,補充一下常見的幾款數據庫管理系統:
mysql、oracle(甲骨文),db2(IBM)、sqlserver(微軟)
sql 語言分類
DQL語言的學習:數據查詢語言(date query language)
DML語言的學習:數據操作語言(data manipulation )
DDL語言:數據定義語言data define language
TCL語言:事務控制語言transaction control language
在下面使用到的案例中,我們都用下面的一張emp表進行查詢,所以我就先把這張表截圖放在這裡,便於後續的查看

tips:這張表格僅僅是用作我們在後續的操作,並沒有任何實際意義哈,不用糾結裏面的每個值是不是符合現實邏輯。
進階1:基礎查詢
一、語法
select 查詢列表 from 表名;
二、特點
1、查詢列表可以是字段、常量、表達式、函數,也可以是多個
2、查詢結果是一個虛擬表
三、示例
1、查詢單個字段
select 字段名 from 表名;
2、查詢多個字段
select 字段名,字段名 from 表名;
3、查詢所有的字段
select * from 表名;
4、查詢常量值
select 常量值;
注意:字符型和日期型的常量值必須用單引號引起來,數值型不需要
5、查詢函數
select 函數名(實參列表);
6、查詢表達式
select 100/1234;
注意:可以使用正常的加減乘除,但是不能使用java中++ —
7、起別名
(1)as
(2)空格
8、去重
select distinct 字段名 from 表名;
注意:去重的時候,只能對一個字段名進行去重處理。
9、+
作用:做加法運算
select 數值+數值;直接運算
select 字符+數值;先試圖將字符轉換成數值,如果轉換成功,則繼續運算;否則將字符轉換為0,再做運算。
select null+值;結果都為null
在這裡我們給出一個字符串連接的案例,便於各位同學的理解吧~
/* java中的+號: (1)運算符,兩個操作數都為數值型 (2)連接符,只要有一個操作數為字符型 mysql中的+號: 僅僅只有一個功能:運算符 select 100+90;兩個操作數都為數值型,則做加法運算 SELECT '123'+90; 只要其中一方為字符型,試圖將字符型數值轉換為數值型 如果轉化成功,則繼續做加法運算 SELECT 'ans'+90; 如果轉換失敗,則將字符型數值轉換為0 SELECT null+10; 只要其中一方為null,則其結果肯定為null */ #案例,查詢員工名和姓連接成一個字段,並顯示為 姓名,實現字符串的連接使用concat函數 SELECT CONCAT(empname, last_name) 全名 FROM emp;
結果圖:

tips:mysql中的『+』號不具備拼接字符串的特性,需要單獨利用拼接字符串的函數concat(),來完成拼接功能。
10、【補充】concat函數
功能:拼接字符串
select concat(字符1,字符2,字符3,…..)
11、【補充】ifnull函數
功能:判斷某字段或表達式是否為null,如果為null 返回指定的值,否則返回原本的值
select ifnull(bonus,0) from emp;
12、【補充】isnull
功能:判斷某字段或表達式的值是否為null,如果是,則返回為1,如果不是,則返回為0
進階2:條件查詢
一、語法
select 查詢列表 from 表名 where 篩選條件;
二、篩選條件的分類
1、簡單條件運算符
> < = <>不等於 >= <= <=>安全等於
2、邏輯運算符
&& and
|| or
! not
3、模糊查詢
我們着重對於模糊查詢進行詳細介紹,下面給出相應的案例:
(1)like:一般搭配通配符使用,可以判斷字符型和數值型
通配符:%任意多個字符,_任意單個字符
/* LIKE 特點: 1.一般和通配符搭配使用 通配符: % 任意多個字符,包含0個字符 _ 任意單個字符 */ #案例1:查詢員工名中帶有字母a的員工 SELECT * FROM emp WHERE empname like '%a%'; #案例2:查詢員工名中第三個字符為i,第五個字符為e的員工名和工資 SELECT empname,salary from emp WHERE empname LIKE '__i_e%'; #案例3:查詢員工名中第二個字符為_的員工名,包含有特殊字符 SELECT empname FROM emp WHERE empname LIKE '_$_' ESCAPE '$';#可以使用任意字符與使用escape關鍵字一起使用,將此字符改變為轉義字符;或者使用斜杠轉義:empname LIKE '__'
查看一下結果圖:
案例1結果:

案例2結果:

案例3結果:
tips:這裡主要說明一下案例3結果,由於我們的數據集中,並沒有員工名中包含有『_』的員工。所以最後查詢的結果為空,而案例3的意義在於說明對於轉義字符的使用問題。我們除了使用斜杠之外,增加了一種使用escape關鍵字的方法。最後的結果中,並沒有報語法錯誤,所以證明這個關鍵字是可以使用的。
(2)between and
#2.between and /* 1.使用between and 可以提高語句的簡潔度 2.包含臨界值 3.兩個臨界值不要調換順序 */ #案例1.查詢員工薪資在2000到5000之間的員工信息 select * FROM emp where salary>=2000 AND salary<=5000; #------------------- select * FROM emp WHERE salary between 2000 and 5000;
兩個查詢的結果集相同,如下所示:

tips:使用between and進行模糊查詢的時候,我們需要注意兩個數值之間的順序,而且between and模糊查詢最後代表的是一個範圍內的結果。
(3)in
/* 含義:判斷某字段的值是否屬於in列表中的某一項 特點: (1)使用in提高語句的簡潔度 (2)in列表的值類型必須一致或兼容 '123' 123 (3)列表中不支持通配符的使用 */ #查詢:查詢員工的姓名為tom1、tom、ceimeng的員工的名字和部門編號 SELECT empname,deptId FROM emp where empname = 'tom1' OR empname = 'tom' OR empname = 'ceimeng'; #------------------------------------------ SELECT empname,deptId FROM emp where empname IN('tom1','tom','ceimeng');
兩個查詢的結果集也相同:
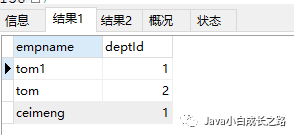
tips :關鍵字in的模糊查詢更加類似於一種列表清單,在此列表清單內的數據都會被列舉出來。
(4)is null 和 is not null:用於判斷null值
/* =或<>不能用於判斷null值 is null 或者 is not null 可以判斷null值 #is null pk <=> is null :僅僅可以判斷null值,可讀性較高,建議使用 <=> :既可以判斷null值,又可以判斷普通的數值,可讀性較低 */ #案列1:查詢沒有獎金的員工名和獎金 SELECT empname,bonus FROM emp WHERE bonus is NULL; #---------------- #安全等於 <=> SELECT empname,bonus FROM emp WHERE bonus <=> NULL;
查看一下結果集:

tips:案例中也給出了兩種判斷null方法,供各位同學選擇~
進階3:排序查詢
基本的語法與上面的兩種相同,主要是使用order by關鍵字
#進階3:排序查詢 /* 引入: select * FROM emp; 語法: select 查詢列表 FROM 表 【where 篩選條件】 ORDER BY 排序列表 【asc|DESC】 特點: 1、asc代表的是升序,desc代表的是降序 如果不寫,默認的是升序 2、order by字句中可以支持單個字段、多個字段、表達式、函數、別名 3、order by字句一般是放在查詢語句的最後面,limit字句除外 */ #案列1:查詢薪資>=2000的員工信息,按生日進行排序【添加篩選調價】 SELECT * from emp where salary >= 2000 ORDER BY birthday DESC; #案列2:按年薪的高低顯示員工的信息和 年薪【按表達式排序】 SELECT *,salary+IFNULL(bonus,0) '年薪' FROM emp ORDER BY salary+IFNULL(bonus,0) DESC; #案例3:查詢員工信息,要求先按照薪資升序,再按照員工編號降序【按多個字段進行排列】 SELECT * FROM emp ORDER BY salary ASC,id DESC;
在上面給出了3個案例,最後的結果如下所示:
案例1:

案例2:

案例3:

tips:上面的三個案例基本涵蓋了我們經常使用到的幾種排序情況,通過總結,我們可以發現,order by子句的使用方法與select子句的使用方法基本一致,主要差別在於使用的位置在整個語句的後面。
進階4:常見函數
一、基本概念
類似於java的方法,將一組邏輯語句封裝在方法體中,對外暴露方法名。
好處:
1、隱藏了實現細節
2、提高代碼的重用型調用:select 函數名(實參列表)【from 表】;
特點:
1、叫什麼(函數名)
2、幹什麼(函數功能)
分類:
1、單行函數 如 CONCAT、length、ifnull
2、分組函數 功能:做統計使用、聚合函數、組函數
二、單行函數
(1)字符函數
length:計算字符串長度
concat:拼接字符串
substr:截取從指定索引後面所有字符,或者,截取從指定索引處,指定字符長度的字符。注意:索引是從1開始的。
instr:返回子串第一次出現的索引,如果找不到返回0。
trim:去除子串前後的空格
upper、lower:將所有的字符串全部轉換為大寫或者小寫
lpad、rpad:用指定的字符實現左(或右)填充指定長度
replace :替換指定的字符串
(2)數學函數
round:四捨五入,可以指定保留小數點後面多少位
ceil:向上取整,返回>=改參數的最小整數
floor:向下取整,返回<=該參數的最大整數
truncate:從小數點後面第幾位開始截斷
mod:取余函數
對於取余函數我們需要注意一下其內部的計算法則,以避免在負數取余的時候犯錯。
/* 取余函數的底層運算 mod(a,b) : a-a/b*b MOD(-10,-3) :-10-(-10)/(-3)*(-3)=-10-3*(-3)=-1 */ select MOD(-10,-3); SELECT -10%(-3);
tips:正因為上述的取余運算的底層法則,使得負數取余的時候,餘數依舊為負數。
(3)日期函數
NOW:顯示當前年月日時分秒
curdate:僅僅顯示當前的日期
curtime:僅僅顯示當前的時間
year、month、day、hour、minute、second:分別顯示相應的時間單位
str_to_date:將時間字符串通過指定的格式轉換為日期
date_format:將時間按照指定的格式轉化為字符串
(4)控制函數
if函數
#1.if函數:if else 的效果 SELECT empname,bonus, IF(bonus is NULL,'沒獎金,呵呵','有獎金,嘻嘻') 備註 FROM emp;
我們查看一下結果集:

tips:通過上面的結果集,我們可以明顯的看出,if函數類似於java中的三位運算符,當判斷條件為真時,輸出第一個結果,條件為假時,輸出第二個結果。
case函數
#2.case函數的使用一:switch case 的效果 /* java 中 switch(變量或表達式){ case 常量1:語句1;break; ..... DEFAULT:語句n;break; } mysql 中 case 要判斷的字段或表達式 when 常量1 then 要顯示的值1或語句1; when 常量2 then 要顯示的值2或語句2; ... ELSE 要顯示的值n或語句n; END */ /*案例:查詢員工的工資,要求 部門號=1,顯示的工資為1.1倍 部門號=2,顯示的工資為1.2倍 部門號=3,顯示的工資為1.3倍 部門號=4,顯示的工資為1.4倍 */ SELECT empname,salary 原始工資,deptId, CASE deptId WHEN 1 THEN salary*1.1 WHEN 2 THEN salary*1.2 WHEN 3 THEN salary*1.3 ELSE salary*1.4 END 新工資 FROM emp; #3.CASE 函數的使用二:類似於 多重if /* java中: if(條件1){ 語句1; }else if(條件2){ 語句2; } ... ELSE{ 語句n; } mysql 中: CASE WHEN 條件1 THEN 要顯示的值1或語句1; WHEN 條件2 THEN 要顯示的值2或語句2; ..... ELSE 要顯示的值n或語句n; end */ #案例:查詢員工的工資情況 /* 如果工資>10000,顯示的A級別 如果工資>5000,顯示的B級別 如果工資>1000,顯示的C級別 否則,顯示的D級別 */ SELECT empname,salary, CASE WHEN salary>10000 THEN 'A' WHEN salary>5000 THEN 'B' WHEN salary>1000 THEN 'C' ELSE 'D' END 工資等級 FROM emp;
用法一的結果:

用法二的結果:

tips:對於兩種case的用法,全部都已經展示在了代碼行中,各位同學自己查看即可哈!
三、分組函數
(1)基本功能
功能:用作統計使用,又稱為聚合函數或統計函數或組函數。
(2)分類
sum 求和、avg 平均值、max 最大值、min 最小值、count 計算個數
下面對這幾個函數進行簡單的介紹
/* 特點: 1、sum avg 一般用於處理數值型 max min count 可以處理任何類型 2、以上分組函數都忽略null值 3、可以和關鍵字distinct搭配使用,實現去重的運算 4、count函數的單獨介紹 一般使用count(*)用作統計行數 5、和分組函數一同查詢的字段要求是group by 後的字段 */ #1、和distinct搭配 SELECT COUNT(DISTINCT deptId) from emp; #2、count函數的詳細介紹 SELECT COUNT(*) from emp;#統計整張表中的所有行數,也可以通過在添加常量的方法來統計:SELECT COUNT(1) from emp; #效率: #MYISAM 存儲引擎下 , count(*)的效率高 #INNODB 存儲引擎下 , count(*)和COUNT(1)的效率差不多,比count(字段)要高一些
案例1結果圖:

案例2結果圖:

tips:通過案例1,我們主要說明一下去重關鍵字與統計函數的搭配使用。在對deptId進行計數的時候,可以計算有多少個部門id。
進階5:分組查詢
一、基本思想
在前面的進階過程中,我們一直是針對整張表格的數據進行。分組查詢主要是根據用戶的需求,對自己設定的類別進行單獨的統計計算。在分組查詢中主要使用group by關鍵字。
二、語法
SELECT 分組函數,列(要求出現在group by的後面)
FROM 表 【where 篩選條件】
GROUP BY 分組的列表
【order by 子句】
注意點:查詢列表必須特殊,要求是分組函數和group by 後出現的字段
三、特點
#進階5:分組查詢 /* 特點: 1、分組查詢中的篩選條件分為兩類 數據源 位置 關鍵字 分組前篩選 原始表 GROUP BY子句的前面 WHERE 分組後篩選 分組後的結果集 GROUP BY子句的後面 HAVING (1)分組函數做條件肯定是放在having子句中 (2)能用分組前篩選的,就優先考慮使用分組前篩選 2、group by子句支持單個字段分組,多個字段分組(多個字段之間用逗號隔開,沒有順序要求),表達式(使用的較少) 3、也可以添加排序(排序放在整個分組查詢的最後) */ #案例1:查詢每個部門的平均工資 SELECT round(avg(salary),2),deptId FROM emp GROUP BY deptId; #添加分組後複雜的篩選條件 #案例2:查詢部門編號>1的每個部門中,最低工資大於1000的部門編號是哪個,以及其部門的最低工資 SELECT deptId,MIN(salary) 部門最低工資 FROM emp WHERE deptId>1 GROUP BY deptId HAVING 部門最低工資>5000;
案例1結果:

案例2結果:

tips:
案例2中,首先要求部門編號大於1,這個篩選條件我們可以直接在原始表中進行,所以使用的是where關鍵字,得到了第一步篩選之後的表格——部門編號大於1的各個部門的最低工資。
但是根據案例中的要求,每個部門的最低工資需要大於1000,這個篩選是基於我們第一次篩選之後表格進行的,所以此時我們不能夠繼續使用where關鍵字,需要使用having關鍵字,表示我們對第一次篩選得到的表格進行第二次篩選。同時根據我們的代碼也可以發現,在使用having關鍵字的時候,我們還可以使用別名進行二次篩選。
