Apache Hudi在醫療大數據中的應用
- 2020 年 5 月 30 日
- 筆記
本篇文章主要介紹Hudi在醫療大數據中的應用,主要分為5個部分進行介紹:1. 建設背景,2. 為什麼選擇Hudi,3. Hudi數據同步,4. 存儲類型選擇及查詢優化,5. 未來發展與思考。
1. 建設背景
我們公司主要為醫院建立大數據應用平台,需要從各個醫院系統中抽取數據建立大數據平台。如醫院信息系統,實驗室(檢驗科)信息系統,體檢信息系統,臨床信息系統,放射科信息管理系統,電子病例系統等等。

在這麼多系統中構建大數據平台有哪些痛點呢?大致列舉如下。
- 接入的數據庫多樣化。其中包括很多系統,而系統又是基於不同數據庫進行開發的,所以要支持的數據庫比較多,例如MySQL,Oracle,Mongo db,SQLServer,Cache等等。
- 統一數據建模。針對不同的醫院不同的系統裏面的表結構,字段含義都不一樣,但是最終數據模型是一定的要應用到大數據產品上的,這樣需要考慮數據模型的量化。
- 數據量級差別巨大。不一樣的醫院,不一樣的系統,庫和表都有着很大的數據量差異,處理方式是需要考慮兼容多種場景的。
- 數據的時效性。數據應用產品需要提供更高效的實時應用分析,這也是數據產品的核心競爭力。
2. 為什麼選擇Hudi
我們早期的數據合併方案,如下圖所示
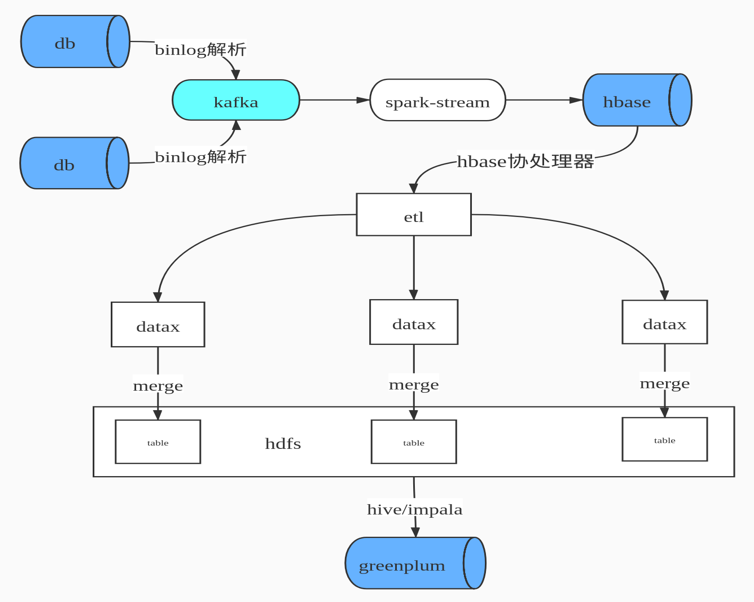
即先通過binlog解析工具進行日誌解析,解析後變為JSON數據格式發送到Kafka 隊列中,通過Spark Streaming 進行數據消費寫入HBase,由HBase完成數據CDC操作,HBase即我們ODS數據層。由於HBase 無法提供複雜關聯查詢,這對後續的數據倉庫建模並不是很友好,所以我們設計了HBase二級索引來解決兩個問題:1. 增量數據的快速拉取,2. 解決數據的一致性。然後就是自研ETL工具通過DataX 根據最後更新時間增量拉取數據到Hadoop ,最後通過Impala數據模型建模後寫入Greenplum提供數據產品查詢。
上述方案面臨了如下幾個問題
- 數據流程環節複雜,數據要經過Kafka,HBase,Hdfs,Impala。
- 數據校驗困難,每層數據質量校驗比較麻煩。
- 數據存儲冗餘,HBase存儲一份,Hive Hdfs 也存儲一份。
- 查詢負載高,HBase表有上限一旦表比較多,維護的Region個數就比較多,Region Server 容易出現頻繁GC。
- 時效性不高,流程長不能保證每張表都能在10分鐘內同步,有些數據表有滯後現象。

面對上述的問題,我們開始調研開源的實現方案,然後選擇了Hudi,選擇Hudi 優勢如下
- 多種模式的選擇。目前Hudi 提供了兩種模式:Copy On Write和Merge On Read,針對不同的應用場景,可選擇不同模式,並且每種模式還提供不同視圖查詢,。
- 支持多種查詢引擎。Hudi 提供Hive,Spark SQL,presto、Impala 等查詢方式,應用選擇更多。
- Hudi現在只是Spark的一個庫, Hudi為Spark提供format寫入接口,相當於Spark的一個庫,而Spark在大數據領域廣泛使用。
- Hudi 支持多種索引。目前Hudi 支持索引類型HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四種索引以及用戶自定義索引以加速查詢性能,避免不必要的文件掃描。
- 存儲優勢, Hudi 使用Parquet列式存儲,並帶有小文合併功能。
3. Hudi 數據同步
Hudi數據同步主要分為兩個部分:1. 初始化全量數據離線同步;2. 近實時數據同步。

離線同步方面:主要是使用DataX根據業務時間多線程拉取,避免一次請求過大數據和使用數據庫驅動JDBC拉取數據慢問題,另外我們也實現多種datax 插件來支持各種數據源,其中包括Hudi的寫入插件。
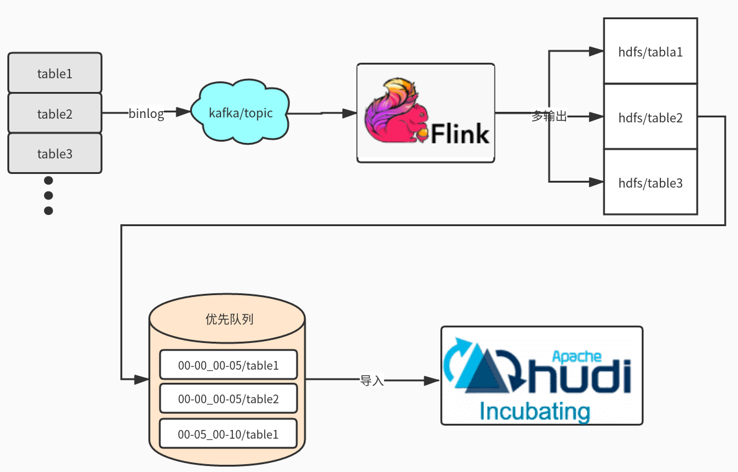
近實時同步方面:主要是多表通過JSON的方式寫入Kafka,在通過Flink多輸出寫入到Hdfs目錄,Flink會根據binlog json的更新時間劃分時間間隔,比如0點0分到0點5分的數據在一個目錄,0點5分到0點10分數據一個目錄,根據數據實時要求選擇目錄時間的間隔。接着通過另外一個服務輪詢監控Hdfs是否有新目錄生成,然後調用Hudi Merge腳本任務。運行任務都是提交到線程池,可以根據集群的資源調整併合並的數量。
這裡可能大家有疑問,為什麼不是Kafka 直接寫入Hudi ?官方是有這樣例子,但是是基於單表的寫入,如果表的數據多達上萬張時怎麼處理?不可能創建幾萬個Topic。還有就是分流的時候是無法使用Spark Write進行直接寫入。
4. 存儲類型選擇及查詢優化
我們根據自身業務場景,選擇了Copy On Write模式,主要出於以下兩個方面考慮。
- 查詢時的延遲,
- 基於讀優化視圖增量模式的使用。
關於使用Spark SQL查詢Hudi也還是SQL拆分和優化、設置合理分區個數(Hudi可自定義分區可實現上層接口),提升Job並行度、小表的廣播變量、防止數據傾斜參數等等。
關於使用Presto查詢測試比Spark SQL要快3倍,合理的分區對優化非常重要,Presto 不支持Copy On Write 增量視圖,在此基礎我們修改了hive-hadoop2插件以支持增量模式,減少文件的掃描。
5. 未來發展與思考
-
離線同步接入類似於FlinkX框架,有助於資源統一管理。FlinkX是參考了DataX的配置方式,把配置轉化為Flink 任務運行完成數據的同步。Flink可運行在Yarn上也方便資源統一管理。
-
Spark消費可以支持多輸出寫入,避免需要落地Hdfs再次導入。這裡需要考慮如果多表傳輸過來有數據傾斜的問題,還有Hudi 的寫入不僅僅只有Parquert數據寫入,還包括元數據寫入、布隆索引的變更、數據合併邏輯等,如果大表合併比較慢會影響上游的消費速度。
-
Flink對Hudi的支持,社區正在推進這塊的代碼合入。
-
更多參與社區,希望Hudi社區越來越好。

