聚類算法——DBSCAN算法原理及公式
聚類的定義
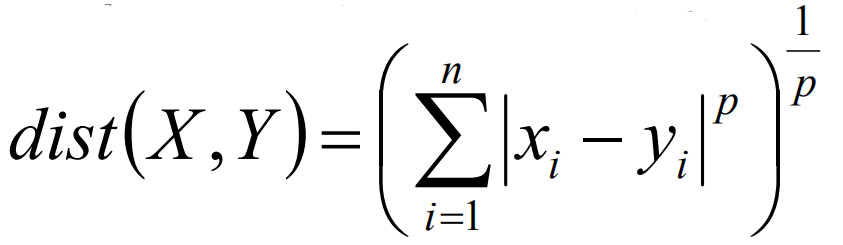
在上述的計算中,當p=1時,則是計算絕對值距離,通常叫做曼哈頓距離,當p=2時,表述的是歐式距離。
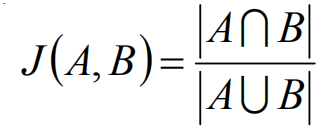
傑卡德相關係數主要用於描述集合之間的相似度,在目標檢測中,iou的計算就和此公式相類似
餘弦相似度
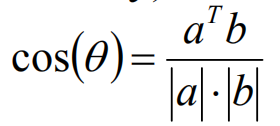
餘弦相似度通過夾角的餘弦來描述相似性
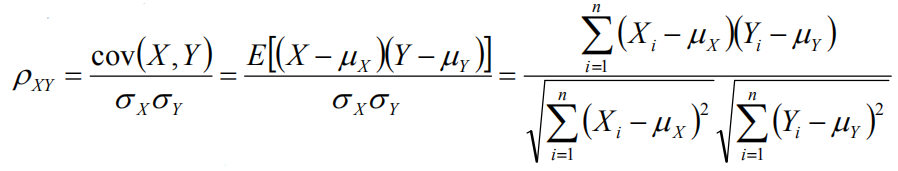
相對熵(K-L距離)
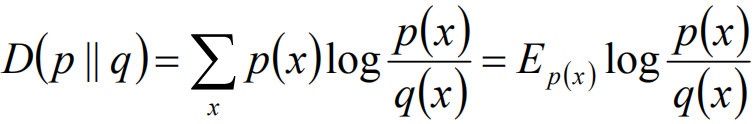
相對熵的相似度是不對稱的相似度,D(p||q)不一定等於D(q||p)。
聚類的基本思想
給定一個有N個對象的數據集,劃分聚類的技術將構造數據的K個劃分,每個劃分代表一個簇,K<=n。也就是說,聚類將數據劃分為k個簇,而且這k個劃分滿足下列條件:
每個簇至少包含一個對象,每一個對象屬於且僅屬於一個簇。
具體的步驟為,對於給定的k,算法首先給出一個初始的劃分方法。以後通過反覆迭代的方法改變劃分,使得每一次改進之後的劃分方案都較前一次更好。
密度聚類
密度聚類方法的指導思想是,只要一個區域中的點的密度大於某個閾值,就把它加到與之相近的聚類中去。這類算法能夠克服基於距離的算法只能發現「類圓形」的聚類的缺點,可以發現任意形狀的聚類,且對噪聲數據不敏感。但計算密度單元的計算複雜度大,需要建立空間索引來降低計算量。
DBSCAN算法
DBSCAN是一個比較有代表性的基於密度聚類的聚類算法,它對簇的定義為密度相連的點的最大集合,能夠把具有足夠高密度的區域劃分為簇,並可在有噪聲的數據中發現任意形狀的聚類。
DBSCAN相關定義
對象的ε-鄰域:給定對象在半徑ε內的區域。
核心對象:對於給定的數據m,如果一個對象的ε-鄰域至少包含有m個對象,則成為該對象的核心對象。
直接密度可達:給定一個對象集合D,如果p是在q的ε-鄰域內,而q是一個核心對象,則對象p從對象q出發是直接密度可達的。
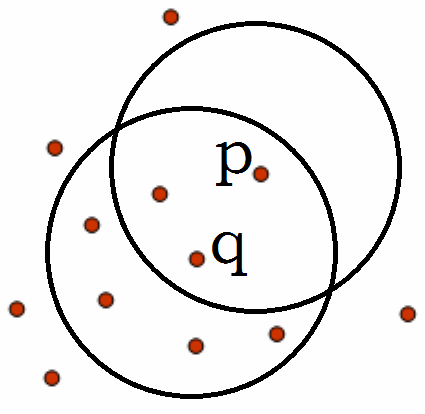
密度可達:如果存在一個對象鏈p1p2···pn,p1=q,pn=p,對pi屬於D,pi+1是從pi關於ε和m直接密度可達的,則對象p是從對象q關於ε和m密度可達的。
密度相連:如果對象集合D中存在一個對象o,使得對象p和q是從o關於ε和m密度可達的,那麼對象p和q是關於ε和m密度相連的。
簇:一個基於密度的簇是最大的密度相連對象的集合。
噪聲:不包含在任何簇中的對象稱為噪聲。
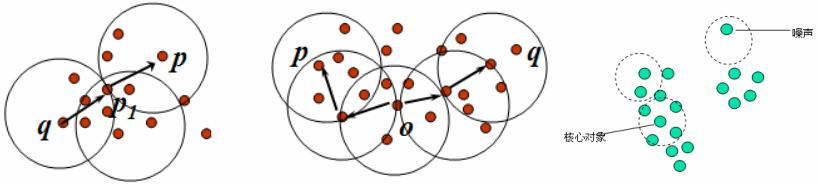
DBSCAN通過檢查數據集中的每個對象的ε-鄰域來尋找聚類,如果一個點p的ε-鄰域包含對於m個對象,則創建一個p作為核心對象的新簇。然後,DBSCAN反覆地尋找這些核心對象直接密度可達的對象,這個過程可能涉及密度可達簇的合併。當沒有新的點可以被添加到任何簇時,該過程結束。算法的中ε和m是根據先驗知識來給出的。


