redis主從複製、主從延遲知幾何
- 2020 年 5 月 17 日
- 筆記
- NoSQL, ping, psync, Redis, repl_offset, run_id, tcp-nodelay, 主從延遲, 心跳
本片章節主要從 redis 主從複製延遲相關知識及影響因素做簡要論述。
1、配置:repl-disable-tcp-nodelay

也即是TCP 的 TCP_NODELAY 屬性,決定數據的發送時機。
配置關閉:主節點產生的數據無論大小都會及時的發送給從節點。redis默認關閉此配置,以保障較小的主從延遲。當然,這需要主從間保持較好的網絡狀況。
配置打開:主節點會合併較小的TCP數據包以節省寬帶,默認發送時間間隔由linux內核設置決定,默認一般40ms。雖然這樣大大增加了主從之間的延遲,但是對於網絡狀況達不到條件或者對主從延遲不敏感的情況比較適用。
在實際應用中,我們可能也會遇到需要異地機房部署主從的情景,因此需要充分考慮對數據更新及時性及數據本身變動特性來決定具體的架構模式。
2、複製偏移量:master_repl_offset | slave_repl_offset
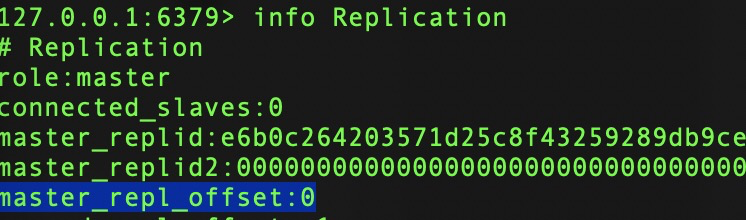
參與複製角色自身維護的複製偏移量。
主節點每次處理完寫操作,會把命令的位元組長度累加到master_repl_offset中。
從節點在接收到主節點發送的命令後,會累加記錄子什麼偏移量信息slave_repl_offset,同時,也會每秒鐘上報自身的複製偏移量到主節點,以供主節點記錄存儲。
在實際應用中,可以通過對比主從複製偏移量信息來監控主從複製健康狀況。
3、複製積壓緩衝:repl_backlog_*
關於redis內存分析,內存優化 介紹過複製積壓緩衝內存佔用,主節點保持的一個固定長度隊列,默認大小1M,當主節點有從節點連接時,主節點在把寫操作發送給從節點的同時,也會寫入一份到複製積壓緩衝區。

複製積壓緩衝隊列,先進先出,主要用於增量複製及丟失命令補救等。
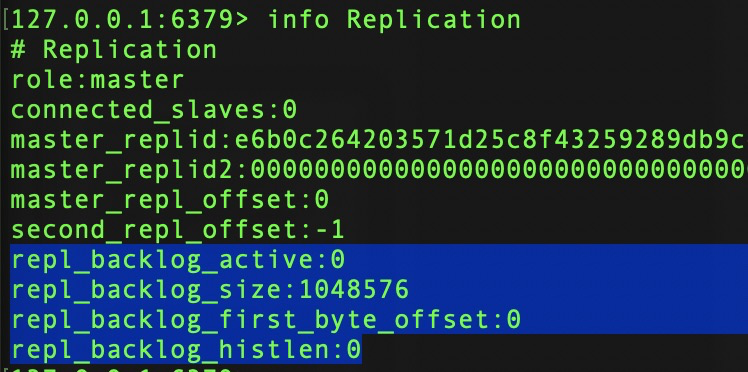
repl_backlog_active:0 | 1 關閉 | 開啟複製積壓緩衝區標誌
repl_backlog_size:緩衝區最大長度
repl_backlog_first_byte_offset:緩衝區起始偏移量
repl_backlog_hislen:已存儲的數據長度。
可用偏移量範圍:[repl_backlog_first_byte_offset, repl_backlog_first_byte_offset + repl_backlog_hislen]
4、redis 實例運行id:run_id:
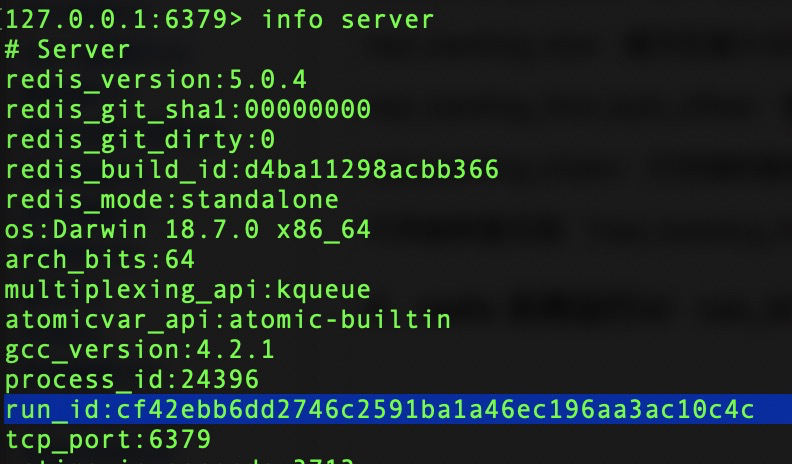
用以網絡中唯一標識區別redis運行實例。
需要注意的是redis重啟之後run_id會隨之改變,如下:

通常我們需要同一個redis實例保持唯一不變的運行ID,以保障主從複製數據安全性。
在需要重新加載配置時通常可以通過執行 debug reload 命令操作:

需要注意的是,debug reload 是阻塞操作,執行時首先生成本地RDB快照,然後清空數據再加載RDB數據。
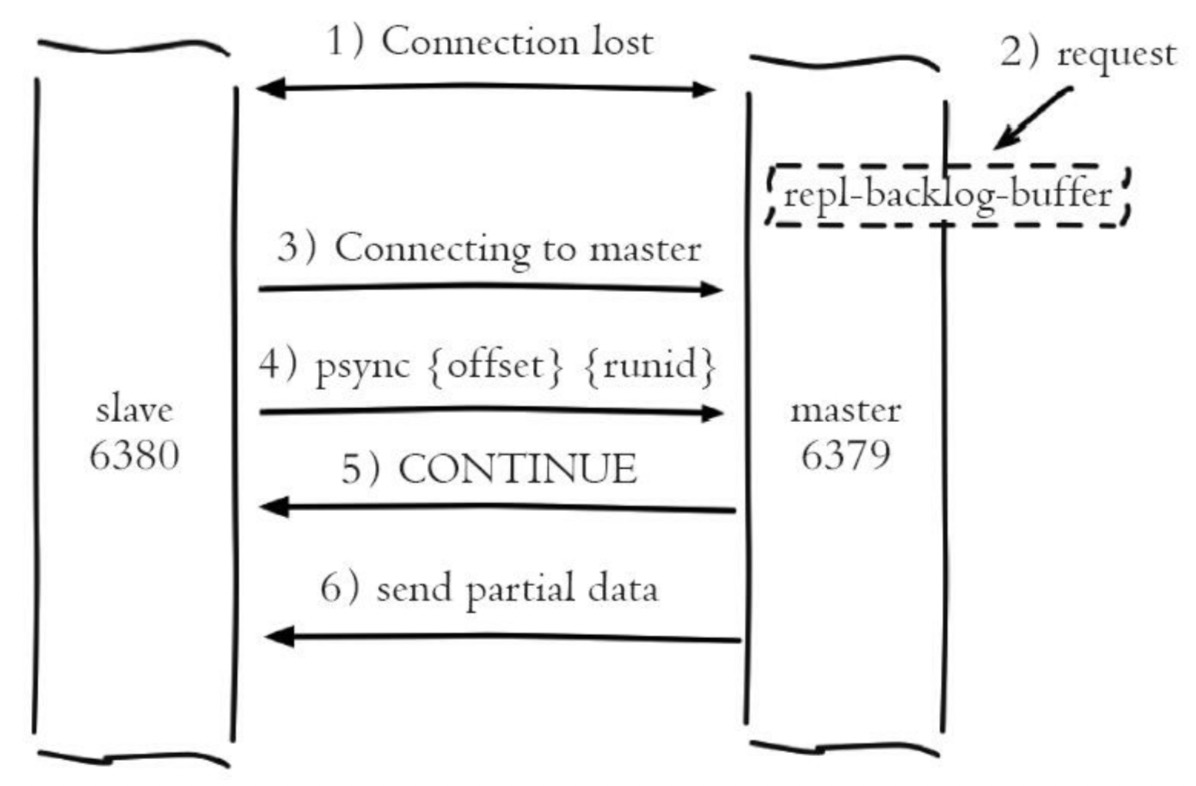
5、主從複製:sync | psync
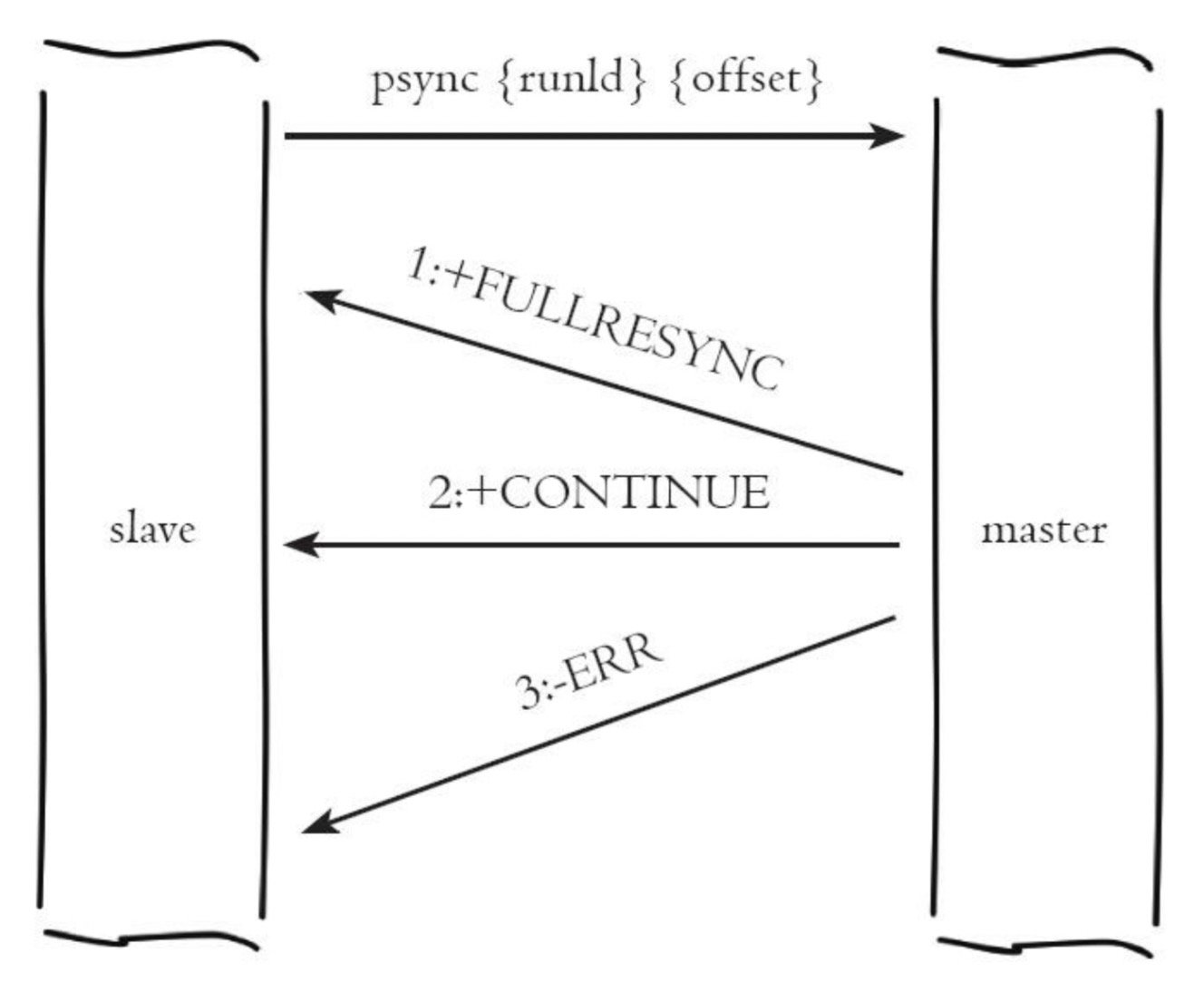
run_id就是上面我們所說的run_id,offset則是複製偏移量。
psync是v2.8版本之後的命令。
FULLRESYNC:全量複製
CONTINUE:部分複製
ERR:從節點版本限制無法識別psync命令。
全量複製:

部分複製:
6、主從心跳
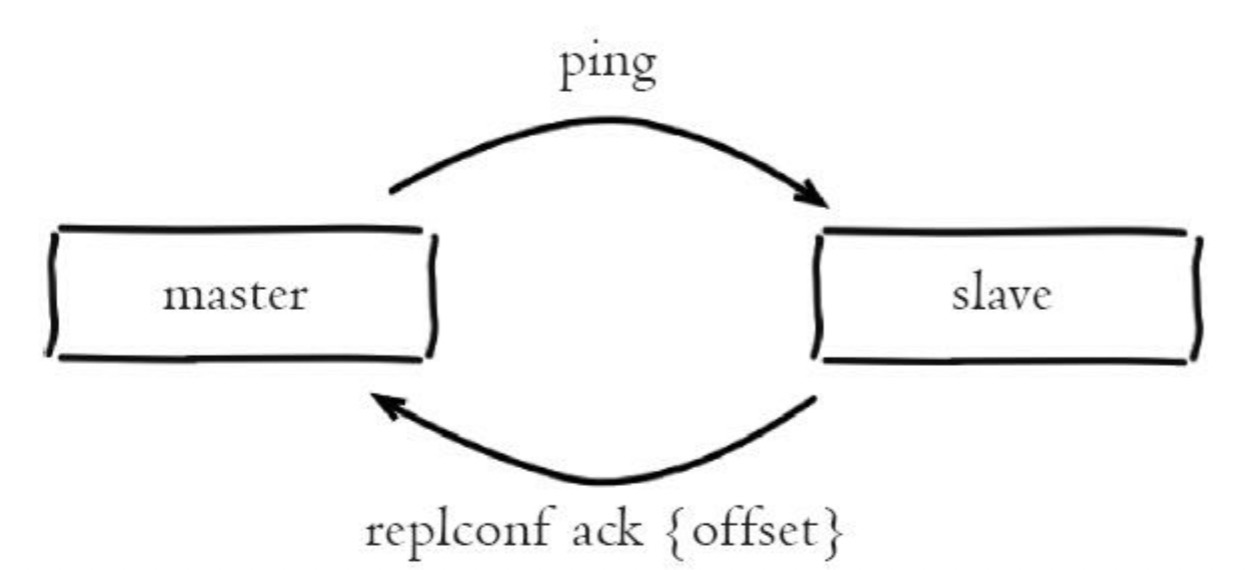
主從之間維持長連接發送信條信息。
主節點每隔10s發送ping命令檢測從節點存活。配置:repl-ping-slave-period
![]()
從節點每隔1s發送 repconfig 命令,上報複製偏移量。
關於repconfig:
實時檢測主從節點網絡狀況。
上報複製偏移量,檢查數據複製狀況。
維護從節點數據量(min-slaves-to-write)及延遲性功能(min-slaves-max-lag)。

