【Flink】使用之前,先簡單了解一下Flink吧!
- 2020 年 5 月 11 日
- 筆記
Flink簡單介紹
概述
在使用Flink之前,我們需要大概知道Flink是什麼?
首先,從Flink的官網可以有一個簡單的了解:Apache Flink 是一個框架和分佈式處理引擎,用於在無邊界和有邊界數據流上進行有狀態的計算。Flink 能在所有常見集群環境中運行,並能以內存速度和任意規模進行計算。
這裡了解過大數據的可以看到幾個熟悉的詞,分佈式處理、內存計算,首先分佈式處理是大數據集群最常見的,也是必備的處理方式,其次,內存計算也不難讓人想到現在很火的Spark,至少通過這個詞肯定可以聯想到Flink處理任務的速度一定也很快。
那麼,什麼是無邊界和有邊界數據流呢?
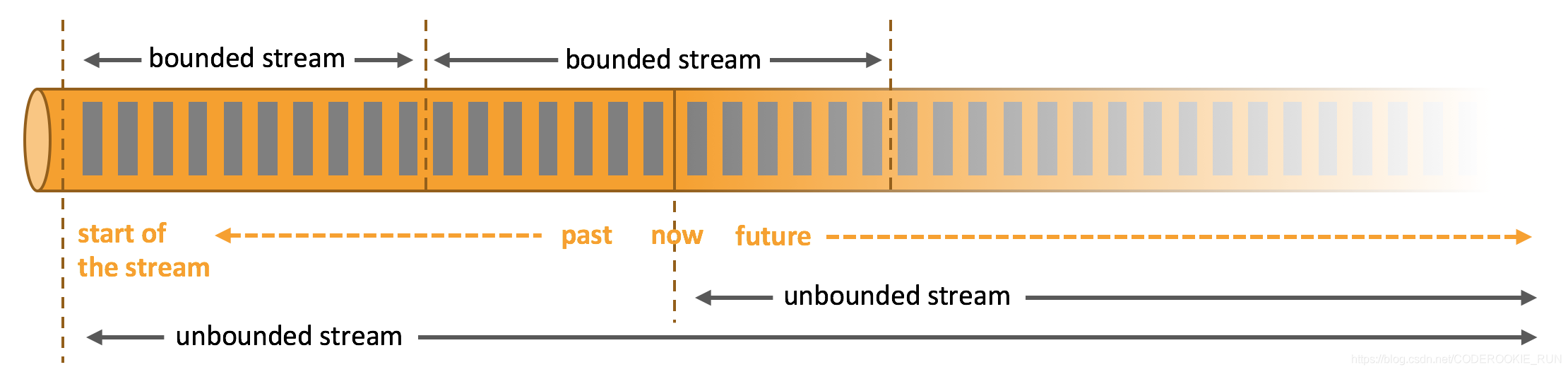
無邊界數據流和有邊界數據流
- 無邊界數據流 | Unbounded Stream
官方的定義:有定義流的開始,但沒有定義流的結束。它們會無休止地產生數據。無界流的數據必須持續處理,即數據被攝取後需要立刻處理。我們不能等到所有數據都到達再處理,因為輸入是無限的,在任何時候輸入都不會完成。處理無界數據通常要求以特定順序攝取事件,例如事件發生的順序,以便能夠推斷結果的完整性。 - 有邊界數據流 | Bounded Stream
官方的定義:有定義流的開始,也有定義流的結束。有界流可以在攝取所有數據後再進行計算。有界流所有數據可以被排序,所以並不需要有序攝取。有界流處理通常被稱為批處理。


技術棧核心組成
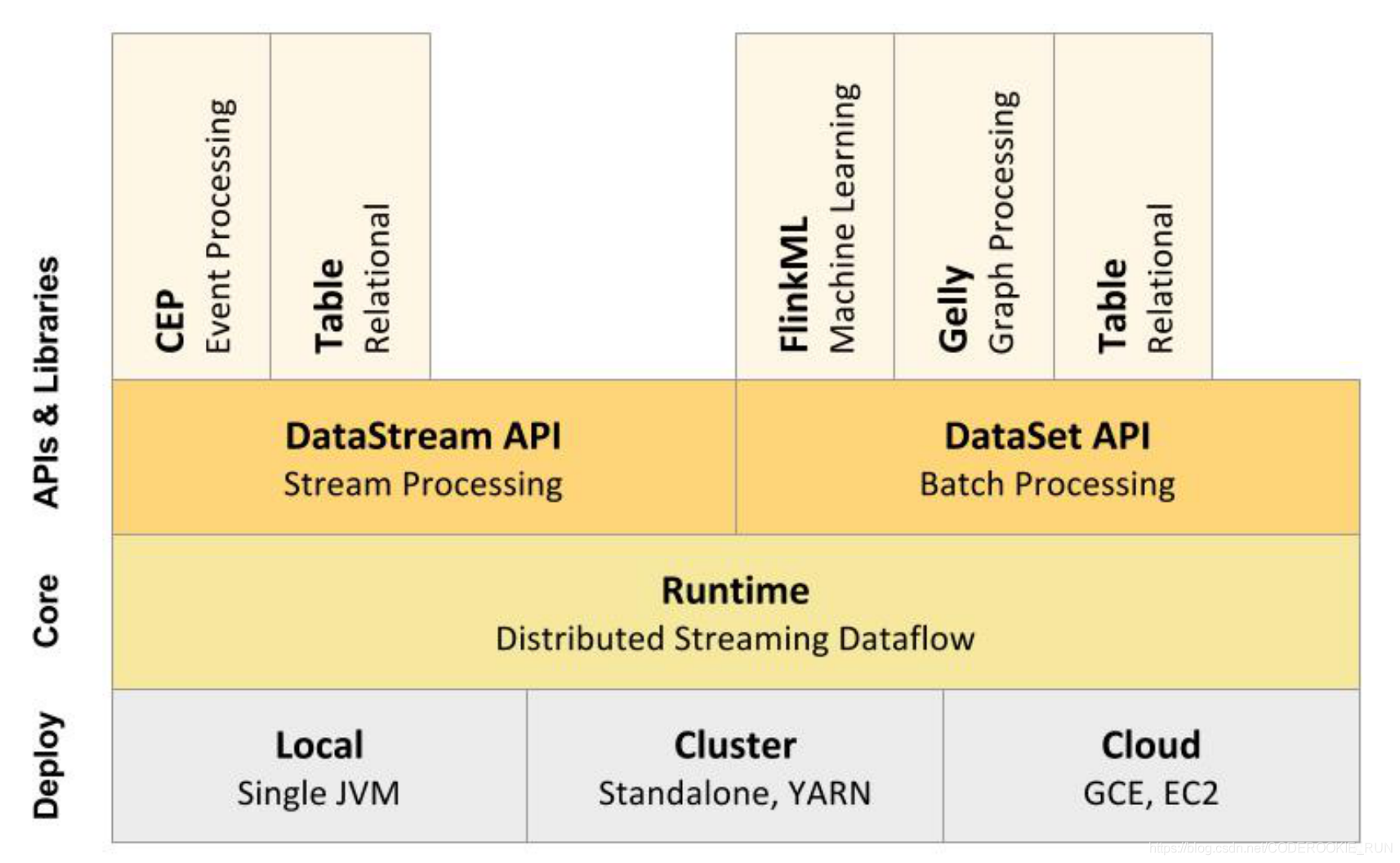
從上圖可以看出,底層是Flink的集群部署選擇,不僅可以運行在包括 YARN、 Mesos、Kubernetes 在內的多種資源管理框架上,還支持在裸機集群上獨立部署。在啟用高可用選項的情況下,它不存在單點失效問題。
核心計算架構是Runtime執行引擎,它是一個分佈式系統,能夠接 受數據流程序並在一台或多台機器上以容錯方式執行。
DataStream API用於流處理,DataSet API用於批處理。

- 流處理特性
1.支持高吞吐、低延遲、高性能的流處理
2.支持帶有事件時間的窗口(Window)操作
3.支持有狀態計算的 Exactly-once 語義
4.支持高度靈活的窗口(Window)操作,支持基於 time、count、session,以及 data-driven 的窗口操作
5.支持具有 Backpressure 功能的持續流模型
6.支持基於輕量級分佈式快照(Snapshot)實現的容錯
7.一個運行時同時支持 Batch on Streaming 處理和 Streaming 處理
8.Flink 在 JVM 內部實現了自己的內存管理
9.支持迭代計算
10.支持程序自動優化:避免特定情況下 Shuffle、排序等昂貴操作,中間結果有必要進行緩存 - 批處理特性
1.有界、持久、大量
2.適合需要訪問全套記錄才能完成的計算工作,一般用於離線統計
Flink和Spark有一點最明顯的不同,就是 Spark應對批處理和流處理採用了不同的技術框架,批處理由SparkSQL實現,流處理由Spark Streaming實現。Flink則可以做到同時實現批處理和流處理, 它的解決辦法就是將批處理(即處理有限的靜態數據)視作是一種特殊的流處理。
Flink支持的拓展庫涉及機器學習(FlinkML)、複雜事件處理(CEP)、圖計算(Gelly) 和分別針對流處理與批處理的 Table API。
架構體系
重要角色
- JobManager
可以認為是Spark中的Master,用於調度task,協調檢查點,協調失敗時的恢復等。至少要存在一個Master處理器,高可用模式下會存在多個Master,一個是leader,剩下的是standby。 - TaskManager
可以認為是Spark中的Worker,用於執行一個dataflow中的task或者特殊的subtask、數據緩衝和data stream的交換。至少要存在一個Worker處理器。
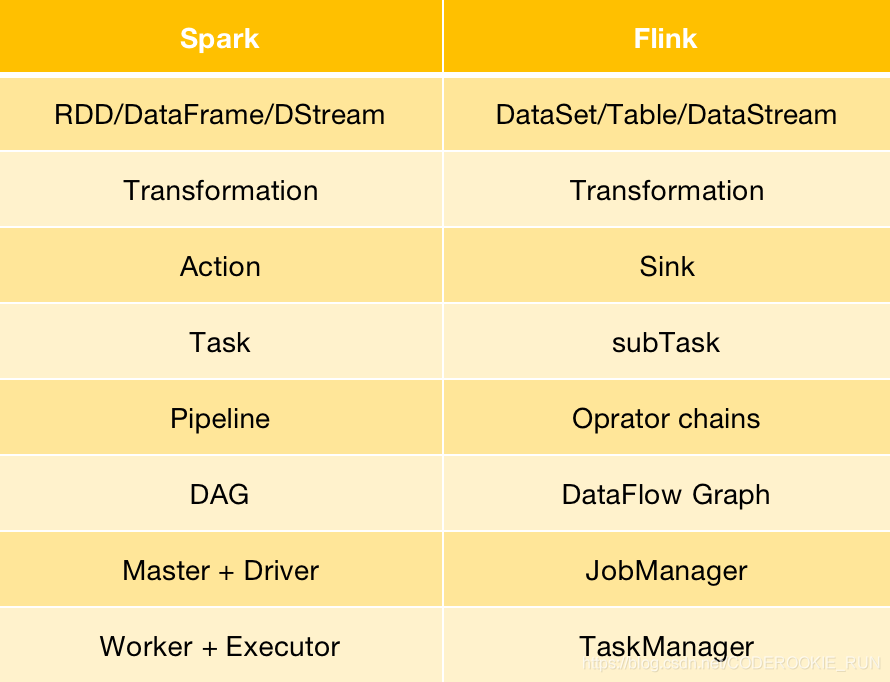
Flink與Spark架構概念轉換