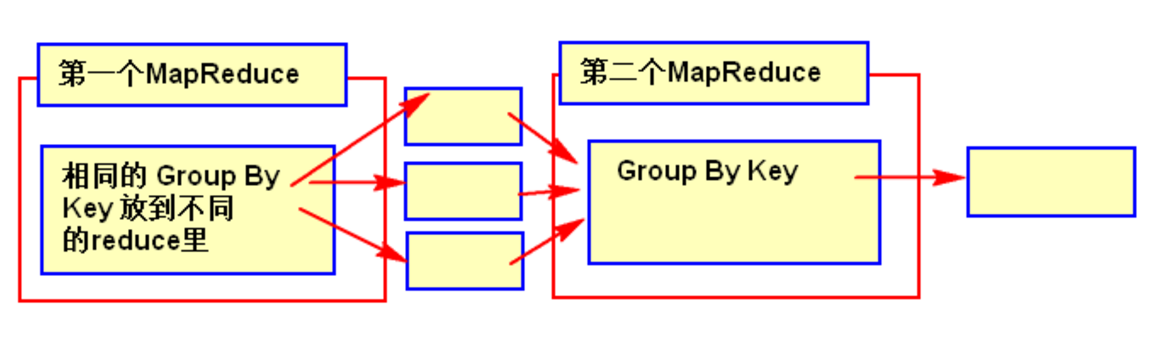
SNIP的升級版SNIPER(效果比Mosaic更佳)
1. 前言
前面介紹了在小目標檢測上另闢蹊徑的SNIP算法,這一節來介紹一下 SNIP 的升級版 SNIPER 算法,這個算法的目的是減少 SNIP 的計算量。並且相比於 SNIP,基於 Faster RCNN(ResNet101 作為 Backbone)的實驗結果顯示 SNIPER 的 mAP 值比 SNIP 算法提升了4.6個百分點,所以效果也還是非常不錯的。在單卡 V100 上,每秒可以處理5漲圖像,這個速度在 two-stage 的算法中來看並不快,但是效果是非常好。
2. 介紹
SNIP 算法借鑒了多尺度訓練的思想進行訓練,所謂多尺度訓練就是用圖像金字塔作為模型的輸入,這種做法雖然可以提高模型效果,但是計算量的增加也非常明顯,因為模型需要需要處理每個尺度的圖像的每個像素。
針對這一缺點,SNIPER(Scale Normalization for Image Pyramids with Efficient Resampling)算法通過引入context-regions這個概念(論文中使用chips這個單詞來表示這些區域,chips的中文翻譯就是碎片,比較形象)使得模型不再需要處理每個尺度圖像的每個像素點,而是選擇那些對檢測最有幫助的區域進行訓練,這樣就大大減少了計算量。
這些chips主要分為2個類別:
- positive chips 這些
chips包含Ground Truth。 - neigative chips 這是從 RPN 網絡輸出的 ROI 抽樣獲得的,這些
chips可以理解為是難分類的背景,而那些容易分類的背景就沒必要進行多尺度訓練了。
最後,模型只處理這2類chips,而不是處理整個圖像,這樣既可以提升效果也可以提升速度。因此,論文的核心就是如何選擇positive chips 和 neigative chips。
3. 算法原理
3.1 positive chip 的選擇過程
positive chip 選擇的出發點是希望一個chip中儘可能包含尺度合適的ground truth box。這裡假設有n個scale,並且這n個scale用{s_1,s_2,…,s_n}來表示,C^i表示每張圖像在尺度為i時獲得的chip集合。另外用C_{pos}^{i}表示positive chip 集合,用C_{neg}^{i}表示neigative chip 集合。
假設一個區域的範圍是R_{i}=[r_{min}^i,r_{max}^i],其中i\in [1, n],表示尺度,R_i表示對於尺度i來說,哪些尺寸範圍的ground truth box 才可以被選中選進chip,在R^i表示範圍內的ground truth box集合用G_i表示,每個chip都希望可以儘可能多的包含ground truth box ,而且只有當某個ground truth box 完全包含在一個chip中才說明該chip包含了這個ground truth box ,這樣得到的尺度i的positive chip集合就是C_{pos}^i。
最後,每個ground truth box就能以一個合適的尺度存在於chip中,這樣就可以大大減少模型對背景區域的處理。
下面我們來看看 SNIPER 究竟是如何選擇positive chip的,如Figure 1所示。
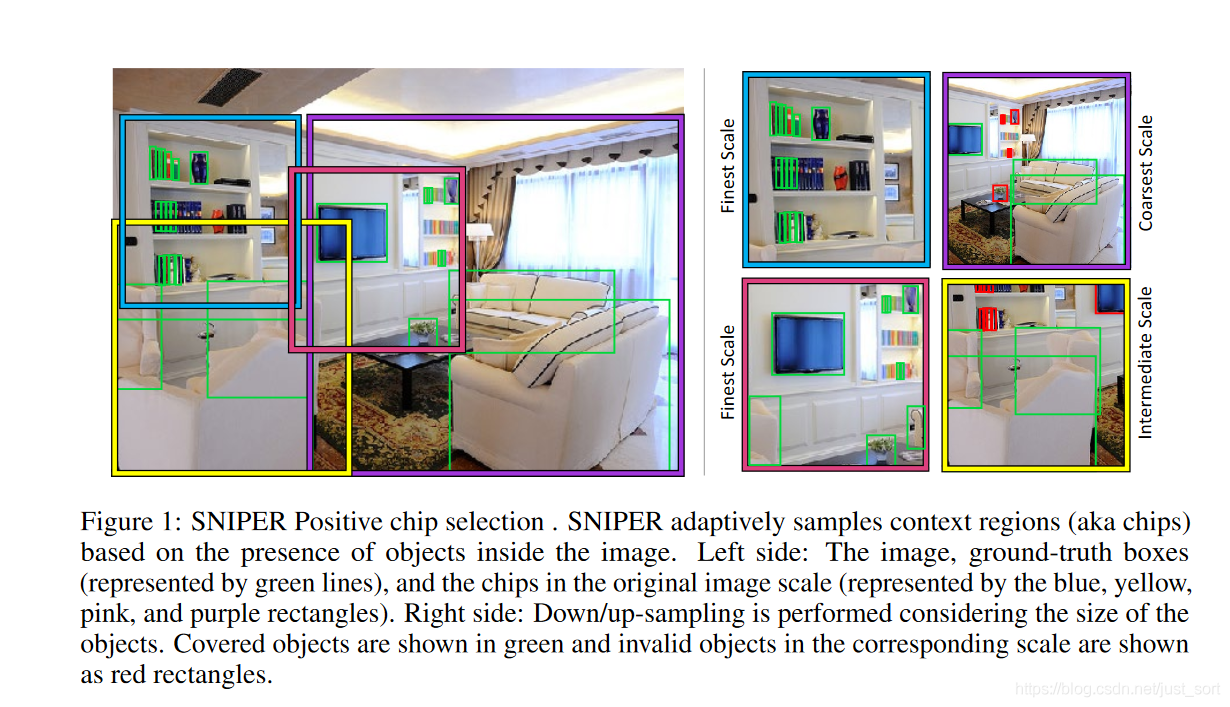
上圖中左邊的綠色實線表示了ground truth,各種顏色加粗的框(一共4個)表示 SNIPER 算法基於原圖生成的chips,這些chips包含了所有的ground truth。而右邊圖是這4個 Chips 的具體內容,其中綠色實線框表示對於該chip來說有效的 ground truth,而紅色實線框表示對該chip而言無效的 ground truth。因為不同scale圖像的R_i範圍有重疊,所以一個 ground truth box 可能會屬於不同尺度的多個chip中,而且同一個ground truth box在同一個尺度中也可能屬於多個chip。
3.2 negtive chip 的選擇過程
如果只基於前面的postive chip,那麼會存在大量的背景區域沒有參與訓練,這就容易造成誤檢,傳統的多尺度訓練方法因為有大量背景區域參與訓練所以誤檢率沒那麼高,但因為大多數背景區域都是非常容易分類的,所以可以想個辦法來避免這部分計算,這就用到了negtive chip 的選擇。接下來我們的問題就變成怎麼判斷哪些背景是容易的,那些背景是困難的,論文使用了一種相對簡單的辦法,即基於 RPN 網絡的輸出來構建negtive chip。
我們知道在 Faster RCNN 裏面 RPN 網絡是用來生成候選框的,這些候選框表示最有可能存在目標的區域,因為這些候選框是基於 RPN 粗篩選得到的,如果某個背景區域連候選框都沒有,那說明這個背景區域是非常容易分類的,這些區域就沒必要再參加訓練了,真正參與訓練的negtive候選框都是容易被誤判的,這樣就能減少誤檢率。
下面的Figure2展示了 SNIPER 的negative chip選擇過程:

第一行表示輸入圖像和ground truth信息,第二行圖像中的紅色小圓點表示沒有被positive chips(Chips) 包含的negative候選框,因為候選框較多,用框畫出來的話比較繁雜,所以這裡用紅色小圓點表示。
橘色的框表示基於這些negtive候選框生成的negtive chips,也即是C_{neg}^i。每個negative chip的獲得過程如下:
- 首先移除包含在C_{pos}^i的區域候選框
- 然後在R_i範圍內,每個
chip都至少選擇M個候選框。 - 在訓練模型時,每一張圖像的每個
epoch都處理固定數量的negative chip,這些固定數量的negative chip 就是從所有尺度的negative chip中抽象獲得的。
總的來說,SNIPER 要考慮的東西主要有label assignments, valid range tuning, positive/negative chip selection, 作者是在 MxNet 實現的,如果要自己剝離出來(比如在 Pytorch 上)還是比較麻煩的,希望後續 mmdection 會提供一下實現,或者哪位好心人去剝離一下。
另外,最近在知乎上衝浪看到中科院一個大佬提出了一個Stitcher: Feedback-driven Data Provider for Object Detection ,很是有趣啊,簡單來說就是和 Mosaic 相反的一個思路,關於 Mosaic 可以看我們公眾號的這篇文章:【從零開始學習YOLOv3】3. YOLOv3的數據加載機制和增強方法 ,然後這篇文章可以看 如何顯著提升小目標檢測精度?深度解讀Stitcher:簡潔實用、高效漲點。我想說的就是在小目標問題上,有很多前輩做了非常多開腦洞和有意義的東西,這裡向他們表示致敬和感謝。
4. 實驗結果
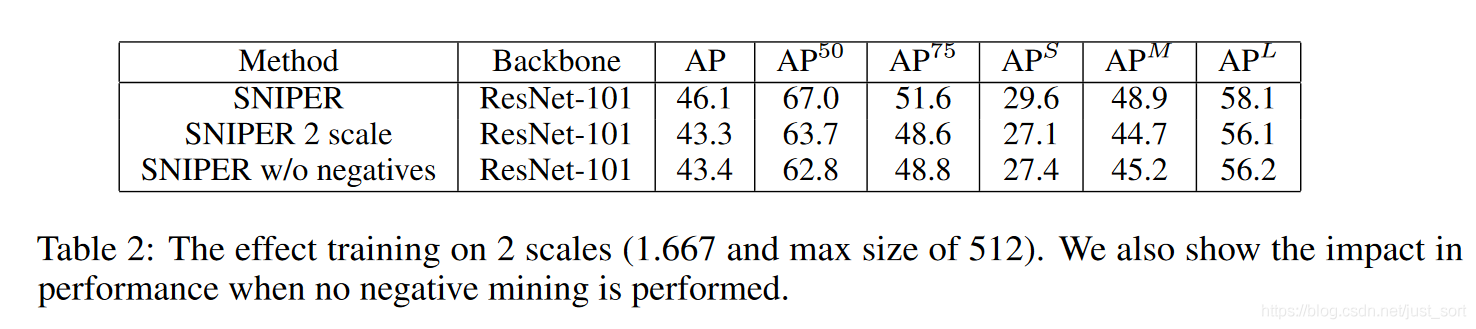
下面的 Table2 展示了是否有negative chip以及scale的個數對實驗結果的影響。因為 AP 值的計算和誤檢是有關的,而沒有negative chip 參與訓練時誤檢會變多,所以 AP 會變低。然後論文採用的默認尺度個數是3,這裡為了測試尺度個數對效果的影響,去掉了最大尺寸的scale,保留了其它兩個scale來訓練,結果顯示 AP 下降明顯。
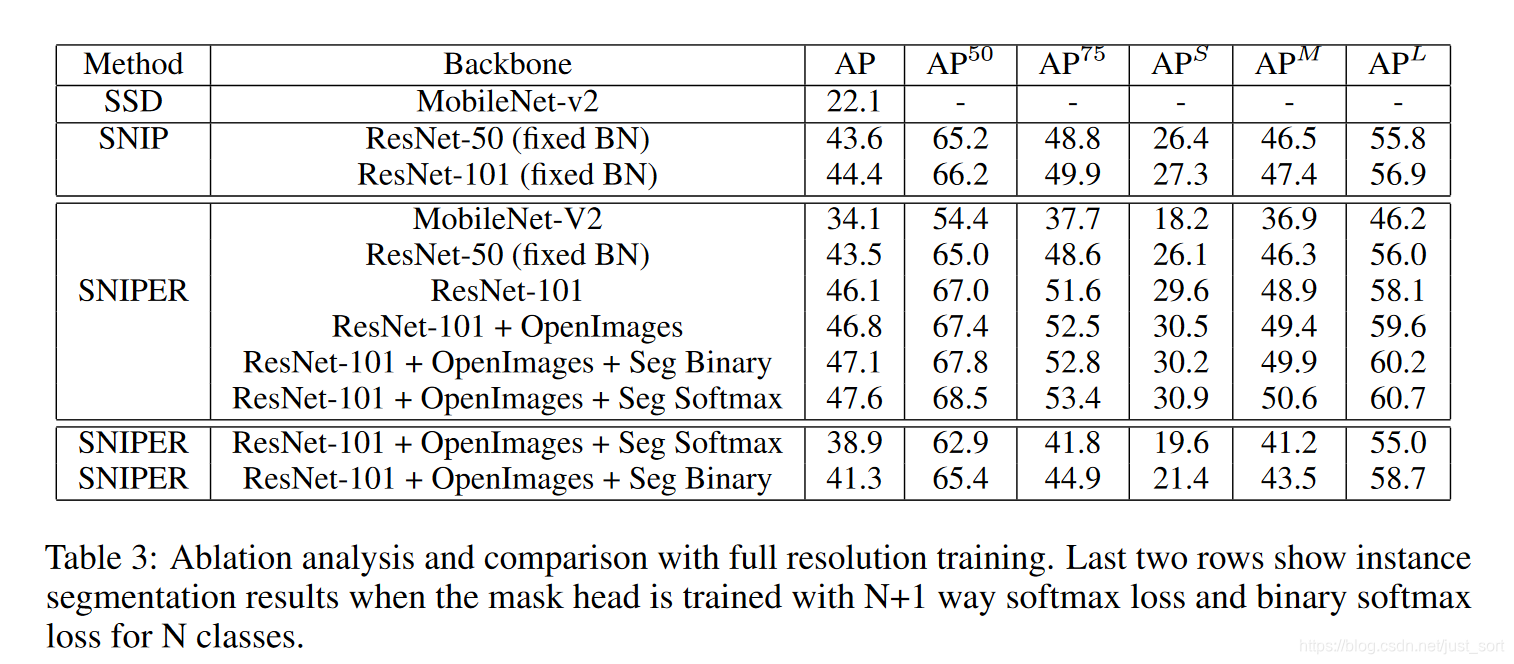
而 Table3 則展示了 SNIPER 算法和其它算法的對比,除了最後兩行是實例分割的結果之外,剩下的都是檢測的結果對比。
5. 總結
簡單來說本文就是在 SNIP 的基礎上加了一個positive/negative chip selection,從實驗結果來看是非常 SOTA 的,可以說碾壓了 Mosaic 反應出來的結果。另外基於 ResNet101 的 Faster RCNN 架構結合 SNIPER,精度超過了 YOLOV4 接近 4 個點,效果是非常好的。有問題可以留言交流。
6. 參考
- //blog.csdn.net/u014380165/article/details/82284128?utm_source=blogxgwz5
- 論文原文://arxiv.org/pdf/1805.09300.pdf
- 官方 MxNet 代碼://github.com/mahyarnajibi/SNIPER
歡迎關注 GiantPandaCV, 在這裡你將看到獨家的深度學習分享,堅持原創,每天分享我們學習到的新鮮知識。( • ̀ ω•́ )✧
有對文章相關的問題,或者想要加入交流群,歡迎添加 BBuf 微信: