flink系列-10、flink保證數據的一致性
本文摘自書籍《Flink基礎教程》
一、一致性的三種級別
當在分佈式系統中引入狀態時,自然也引入了一致性問題。一致性實際上是「正確性級別」的另一種說法,即在成功處理故障並恢復之後得到的結果,與沒有發生任何故障時得到的結果相比。在流處理中,一致性分為 3 個級別。
- at-most-once:數據最多被處理一次。這其實是沒有正確性保障的委婉說法——故障發生之後,計數結果可能丟失。
- at-least-once:數據最少被處理一次。這表示計數結果可能大於正確值,但絕不會小於正確值。也就是說,計數程序在發生故障後可能多算,但是絕不會少
- exactly-once:數據只被處理一次(最優)。這指的是系統保證在發生故障後得到的計數結果與正確值一致。
曾經, at-least-once 非常流行。第一代流處理器(如 Storm 和 Samza)剛問世時只保證 at-least-once,原因有二:
- 保證 exactly-once 的系統實現起來更複雜。這在基礎架構層(決定什麼代表正確,以及 exactly-once 的範圍是什麼)和實現層都很有挑戰性。
- 流處理系統的早期用戶願意接受框架的局限性,並在應用層想辦法彌補(例如使應用程序具有冪等性,或者用批量計算層再做一遍計算)。
最先保證 exactly-once 的系統(Storm Trident 和 Spark Streaming)在性能和表現力這兩個方面付出了很大的代價:
- 為了保證 exactly-once,這些系統無法單獨地對每條記錄運用應用邏輯,而是同時處理多條(一批)記錄,保證對每一批的處理要麼全部成功,要麼全部失敗。
- 這就導致在得到結果前,必須等待一批記錄處理結束。
- Flink 的一個重大價值在於,它既保證了 exactly-once,也具有低延遲和高吞吐的處理能力。
二、檢查點,保證exactly-once
- Flink使用一種被稱為「檢查點」的特性,在出現故障時將系統重置回正確狀態。
- 檢查點是Flink最有價值的創新之一,因為它使Flink可以保證exactly-once,並且不需要犧牲性能。
- Flink檢查點的核心作用是確保狀態正確,即使遇到程序中斷,也要正確。記住這一基本點之後,我們用一個例子來看檢查點是如何運行的。Flink為用戶提供了用來定義狀態的工具。
- 例如,以下這個Scala程序按照輸入記錄的第一個字段(一個字符串)進行分組並維護第二個字段的計數狀態。
val mapData: DataStream[(String, Int)] = dataSource.flatMap(f => f.split(" ")).map((_, 1))
val mapWithStageData: DataStream[(String, Int)] = mapData.keyBy(_._1).mapWithState((in: (String, Int), count: Option[Int]) => {
count match {
case Some(c) => ((in._1, c + in._2), Some(c + in._2))
case None => ((in._1, in._2), Some(in._2))
}
})
該程序有兩個算子:keyBy算子用來將記錄按照第一個元素(一個字符串)進行分組,根據該key將數據進行重新分區,然後將記錄再發送給下一個算子:有狀態的map算子(mapWithState)。map算子在接收到每個元素後,將輸入記錄的第二個字段的數據加到現有總數中,再將更新過的元素髮射出去。
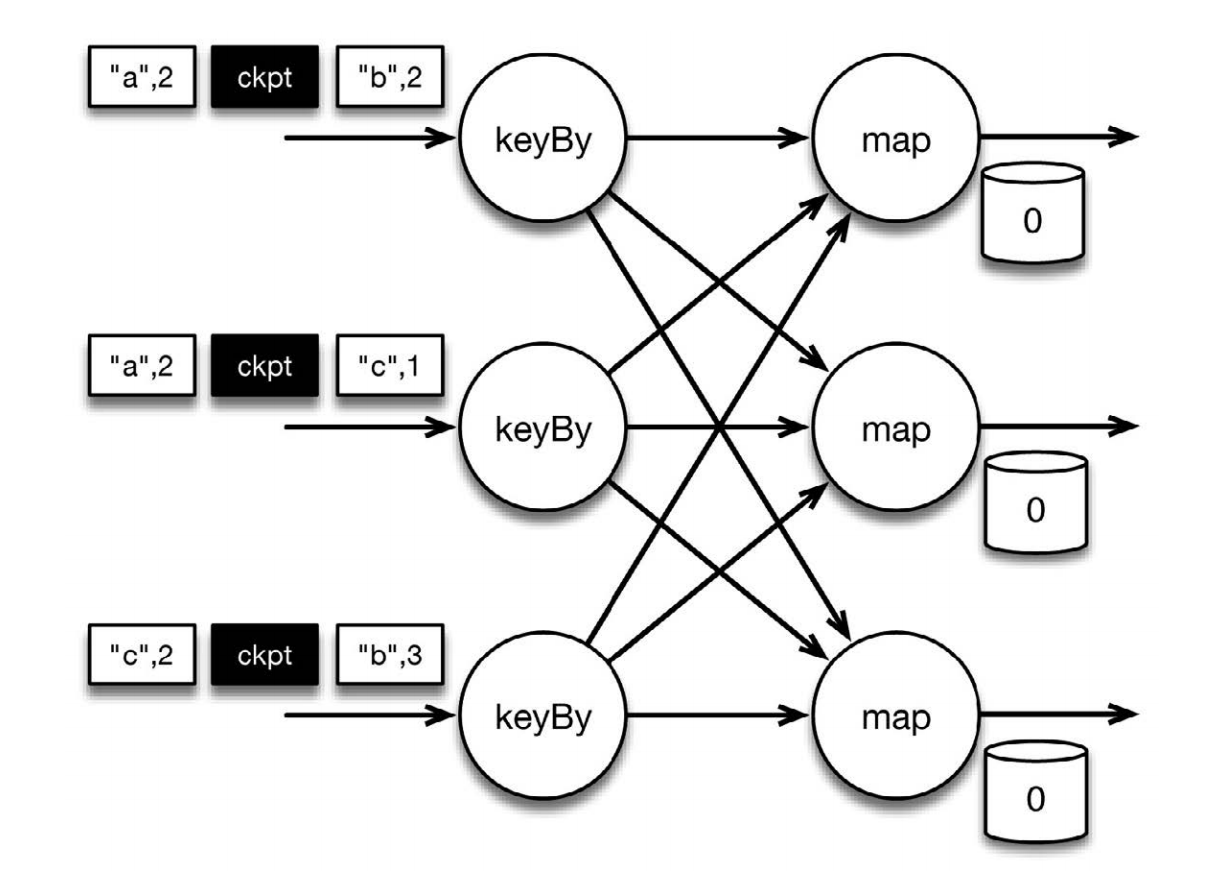
上圖表示程序的初始狀態:輸入流中的6條記錄被檢查點屏障(checkpoint barrier)隔開,所有的map算子狀態均為0(計數還未開始)。所有key為a的記錄將被頂層的map算子處理,所有key為b的記錄將被中間層的map算子處理,所有key為c的記錄則將被底層的map算子處理。其中 [“b”,2] 在檢查點之前被處理, [“a”,2] 則在檢查點之後被處理
當該程序處理輸入流中的 6 條記錄時,涉及的操作遍布 3 個並行實例(節點、 CPU 內核等)。那麼,檢查點該如何保證 exactly-once 呢?檢查點屏障和普通記錄類似。它們由算子處理,但並不參與計算,而是會觸發與檢查點相關的行為。當讀取輸入流的數據源(在本例中與 keyBy 算子內聯)遇到檢查點屏障時,它將其在輸入流中的位置保存到穩定存儲中。如果輸入流來自消息傳輸系統(Kafka 或 MapR Streams),這個位置就是偏移量。 Flink 的存儲機制是插件化的,穩定存儲可以是分佈式文件系統,如HDFS、 S3 或 MapR-FS。下圖展示了這個過程。
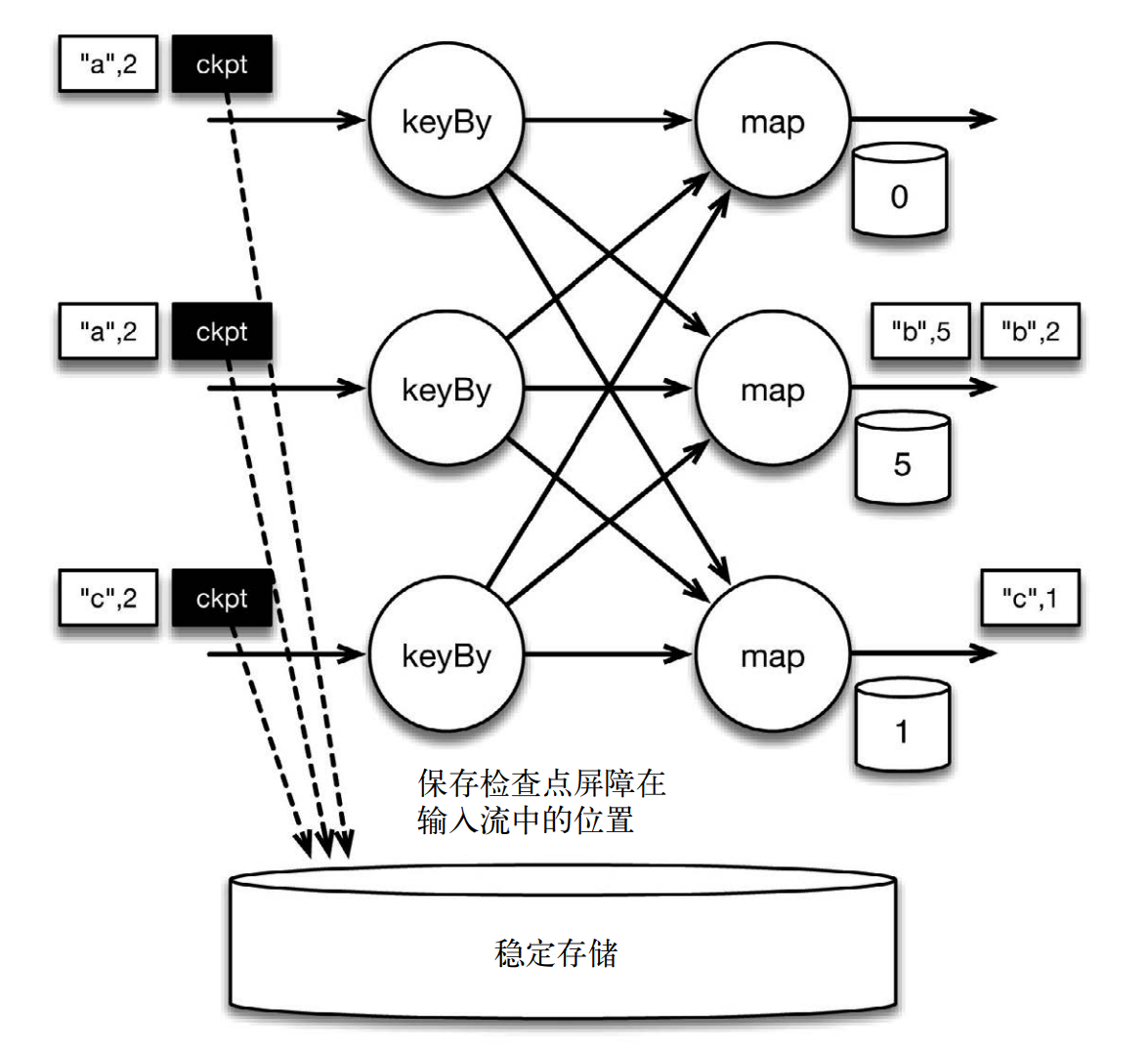
如下圖所示:位於檢查點之前的所有記錄([“b”,2]、 [“b”,3] 和 [“c”,1])被 map 算子處理之後的情況。此時,穩定存儲已經備份了檢查點屏障在輸入流中的位置(備份操作發生在檢查點屏障被輸入算子處理的時候)。 map 算子接着開始處理檢查點屏障,並觸發將狀態異步備份到穩定存儲中這個動作。檢查點屏障像普通記錄一樣在算子之間流動。當 map 算子處理完前 3 條記錄並收到檢查點屏障時,它們會將狀態以異步的方式寫入穩定存儲。
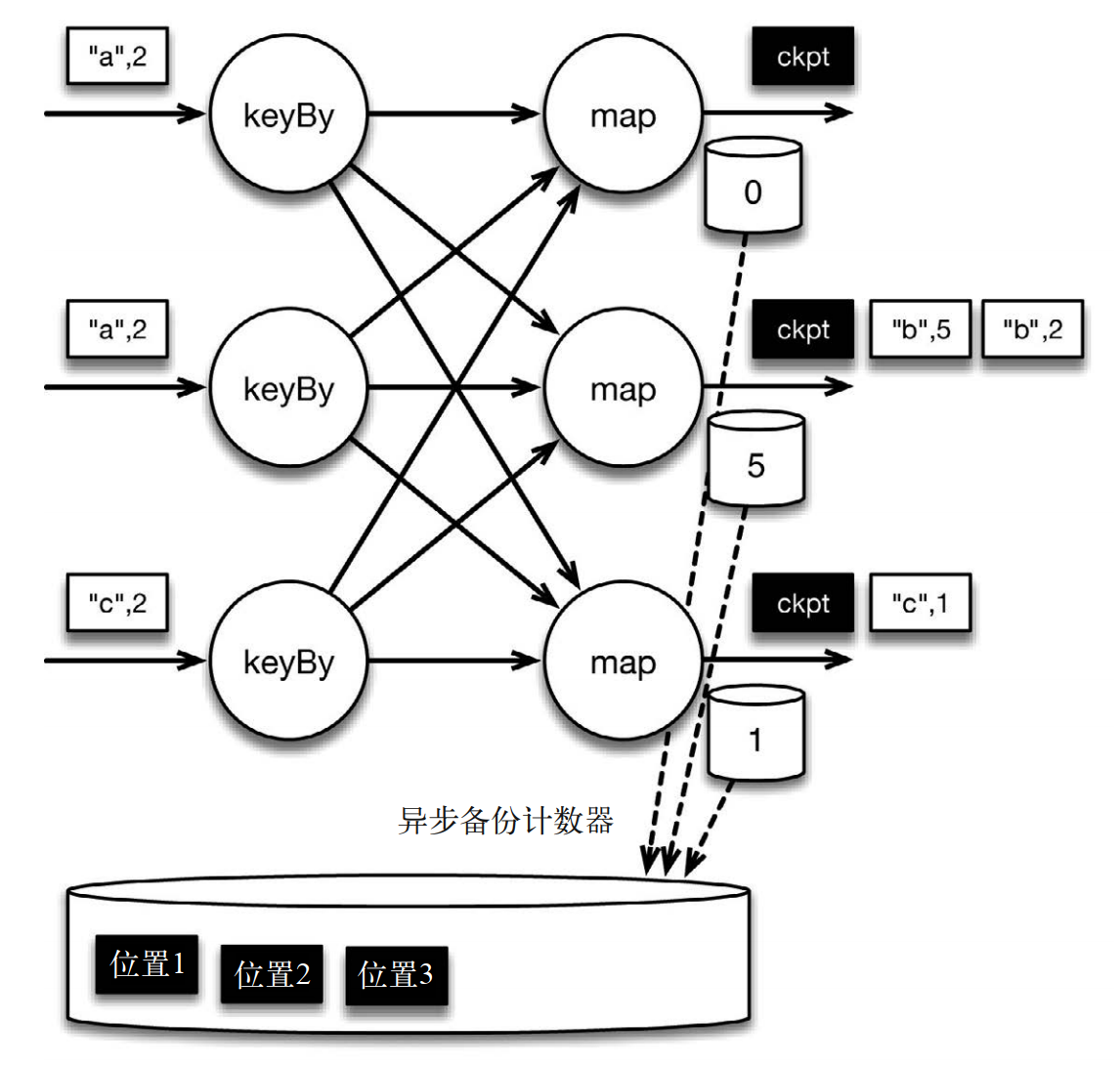
當 map 算子的狀態備份和檢查點屏障的位置備份被確認之後,該檢查點操作就可以被標記為完成,如下圖所示。我們在無須停止或者阻斷計算的條件下,在一個邏輯時間點(對應檢查點屏障在輸入流中的位置)為計算狀態拍了快照。通過確保備份的狀態和位置指向同一個邏輯時間點,從而保證 exactly-once。值得注意的是,當沒有出現故障時, Flink 檢查點的開銷極小,檢查點操作的速度由穩定存儲的可用帶寬決定。值得注意的是,備份的狀態值與實際的狀態值是不同的。備份反映的是檢查點的狀態
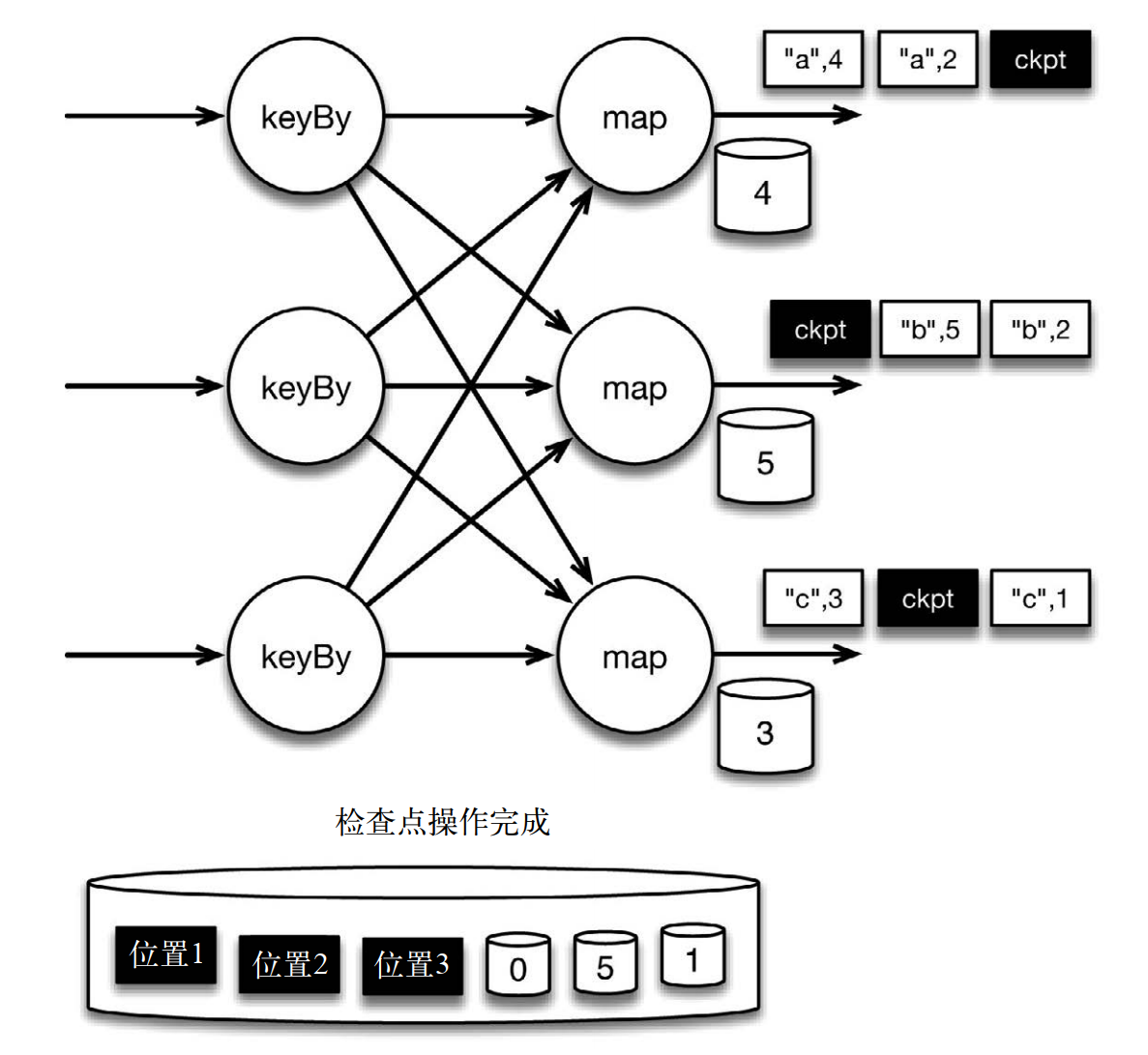
如果檢查點操作失敗, Flink 會丟棄該檢查點並繼續正常執行,因為之後的某一個檢查點可能會成功。雖然恢復時間可能更長,但是對於狀態的保證依舊很有力。只有在一系列連續的檢查點操作失敗之後, Flink 才會拋出錯誤,因為這通常預示着發生了嚴重且持久的錯誤。
在這種情況下, Flink 會重新拓撲(可能會獲取新的執行資源),將輸入流倒回到上一個檢查點,然後恢復狀態值並從該處開始繼續計算。
二、保存點: 狀態版本控制
檢查點由 Flink 自動生成,用來在故障發生時重新處理記錄,從而修正狀態。 Flink 用戶還可以通過另一個特性有意識地管理狀態版本,這個特性叫作保存點(savepoint)
- 保存點與檢查點的工作方式完全相同,只不過它由用戶通過 Flink 命令行工具或者 Web 控制台手動觸發,而不由 Flink 自動觸發。
- 和檢查點一樣,保存點也被保存在穩定存儲中。
- 用戶可以從保存點重啟作業,而不用從頭開始。
- 保存點可以被視為作業在某一個特定時間點的快照(該時間點即為保存點被觸發的時間點)。
- 對保存點的另一種理解是,它在明確的時間點保存應用程序狀態的版本。這和用版本控制系統保存應用程序的版本很相似。最簡單的例子是在不修改應用程序代碼的情況下,每隔固定的時間拍快照,即照原樣保存應用程序狀態的版本。
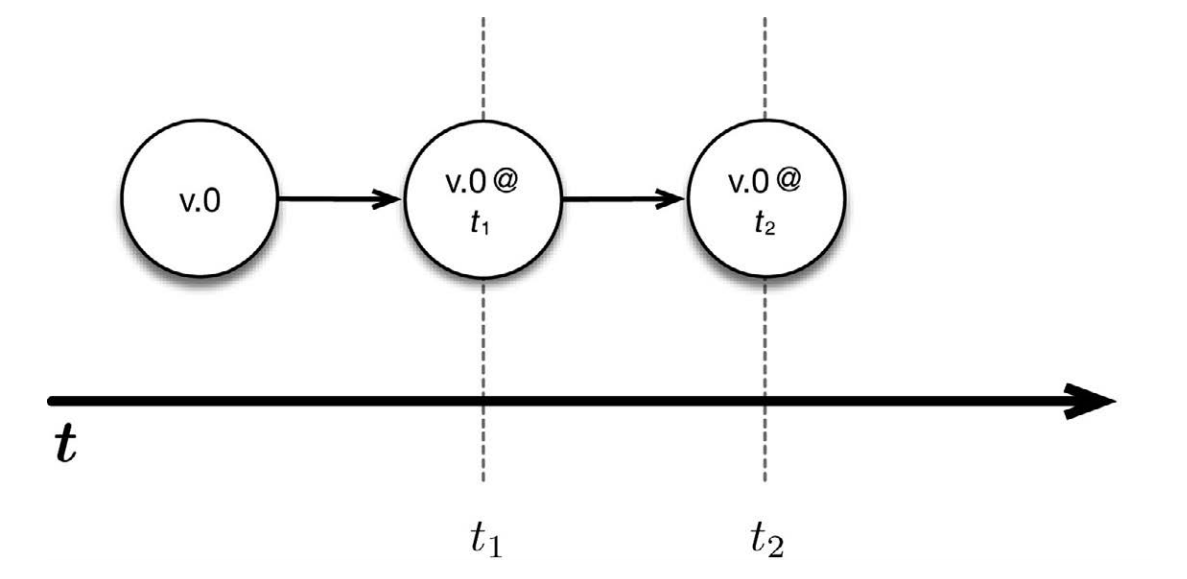
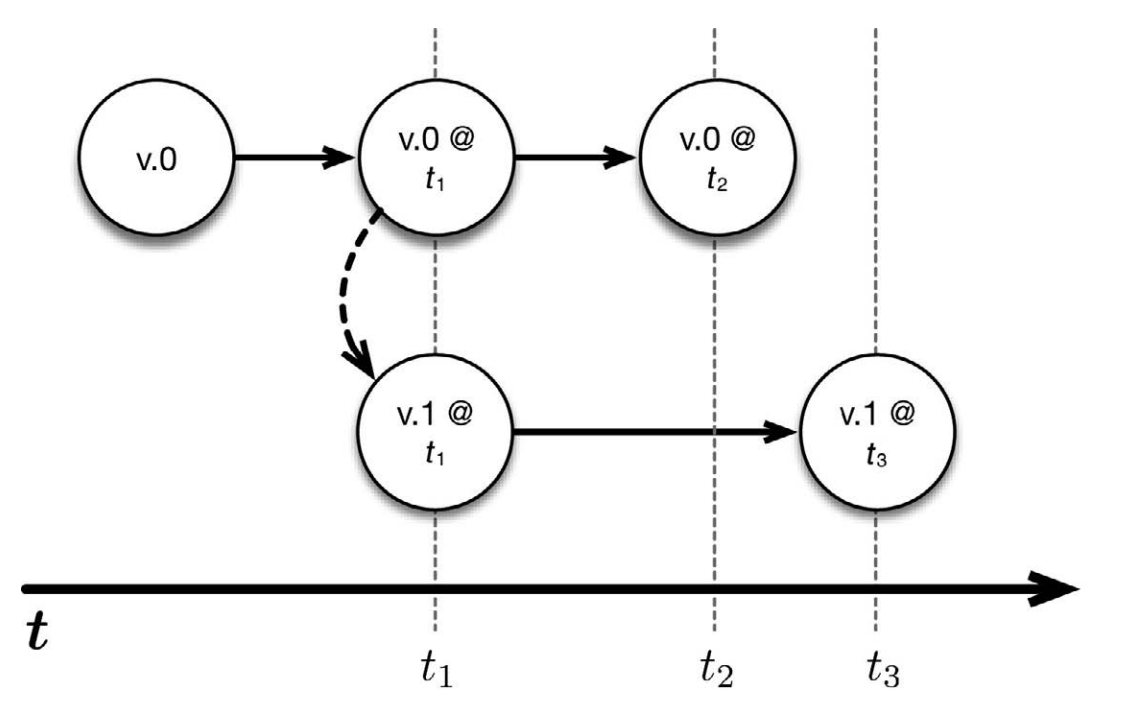
上圖中, v.0 是某應用程序的一個正在運行的版本。我們分別在 t1 時刻和 t2時刻觸發了保存點。因此,可以在任何時候返回到這兩個時間點,並且重啟程序。更重要的是,可以從保存點啟動被修改過的程序版本。舉例來說,可以修改應用程序的代碼(假設稱新版本為 v.1),然後從 t1 時刻開始運行改動過的代碼。這樣一來, v.0 和 v.1 這兩個版本同時運行,並在之後的時間裏獲取各自的保存點。
保存點可用於應對流處理作業在生產環境中遇到的許多挑戰:
- 應用程序代碼升級:假設你在已經處於運行狀態的應用程序中發現了一個 bug,並且希望之後的事件都可以用修復後的新版本來處理。通過觸發保存點並從該保存點處運行新版本,下游的應用程序並不會察覺到不同(當然,被更新的部分除外)。
- Flink 版本更新: Flink 自身的更新也變得簡單,因為可以針對正在運行的任務觸發保存點,並從保存點處用新版本的 Flink 重啟任務。
- 維護和遷移:使用保存點,可以輕鬆地「暫停和恢復」應用程序。這對於集群維護以及向新集群遷移的作業來說尤其有用。此外,它還有利於開發、測試和調試,因為不需要重播整個事件流。
- 假設模擬與恢復:在可控的點上運行其他的應用邏輯,以模擬假設的場景,這樣做在很多時候非常有用。
- A/B 測試:從同一個保存點開始,並行地運行應用程序的兩個版本,有助於進行 A/B 測試
三、端到端的一致性和作為數據庫的流處理器
我們已經通過簡單的計數例子了解了 Flink 如何保證狀態的一致性(即保證exactly-once)。接下來看看端到端的情況,因為在生產環境中可能會部署這種應用程序。
下面的應用程序架構中,有狀態的 Flink 應用程序消費來自消息隊列的數據,然後將數據寫入輸出系統,以供查詢。底部的詳情圖展示了 Flink 應用程序的內部情況。
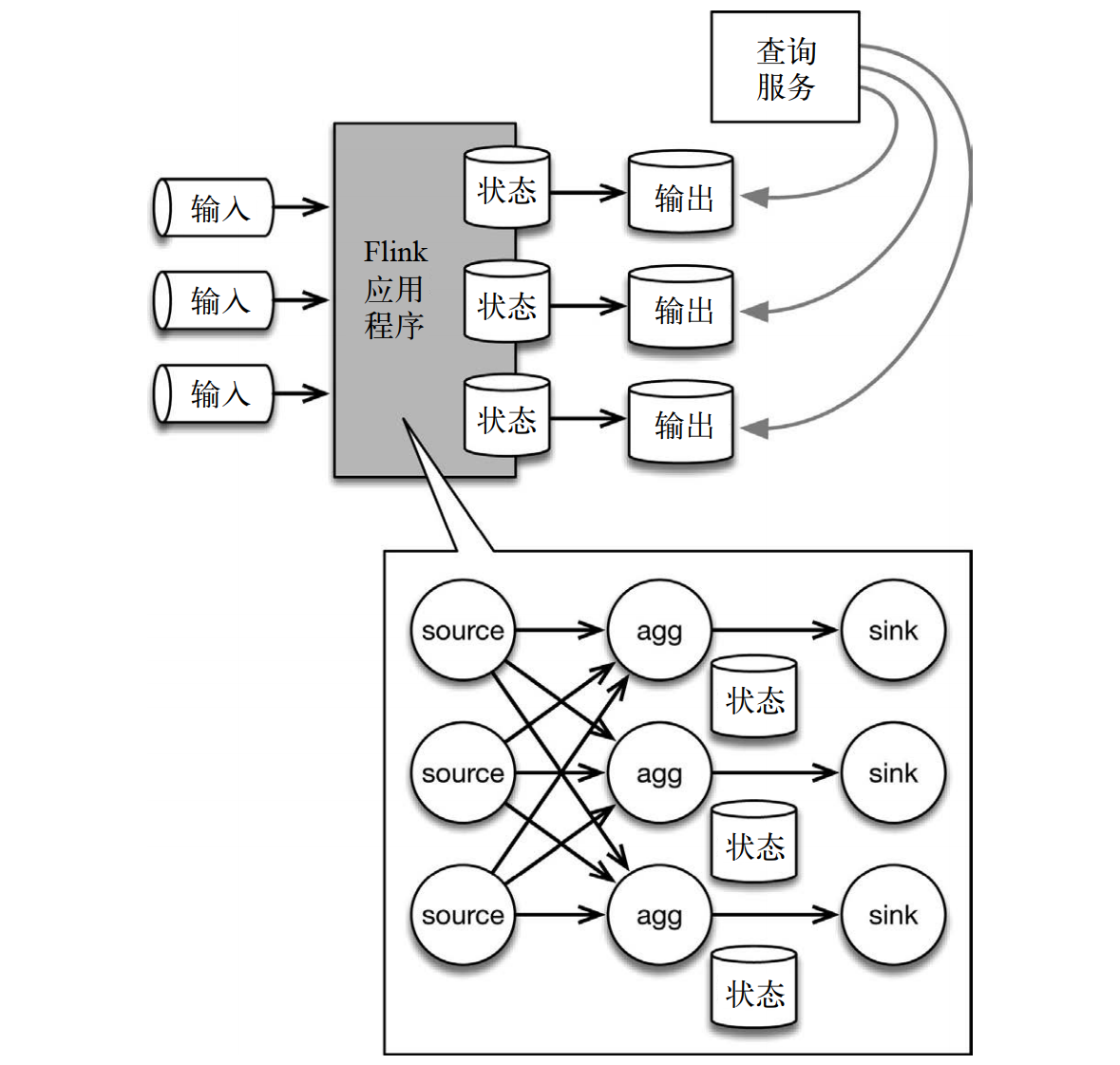
輸入數據來自一個分區存儲系統(如 Kafka 或者 MapR Streams 這樣的消息隊列)。底部的詳情圖展示了 Flink 拓撲,其中包含 3 個算子。source 讀取輸入數據,根據 key 分區,並將數據路由到有狀態的算子實例。有狀態的算子將狀態內容(比如前例中的計數結果)或者一些衍生結果寫入 sink,再由 sink 將結果傳送到輸出存儲系統中(例如文件系統或數據庫)。接着,查詢服務(比如數據庫查詢 API)就可以允許用戶對狀態進行查詢(最簡單的例子就是查詢計數結果),因為狀態已經被寫入輸出存儲系統了。
需要記住的是,在本例中,輸出反映的是截至最近一次寫入狀態之時, Flink 應用程序中的狀態內容。
在將狀態內容傳送到輸出存儲系統的過程中,如何保證 exactly-once 呢?這叫作端到端的一致性。本質上有兩種實現方法,用哪一種方法則取決於輸出存儲系統的類型,以及應用程序的需求:
- 第一種方法是在 sink 環節緩衝所有輸出,並在 sink 收到檢查點記錄時,將輸出「原子提交」到存儲系統。這種方法保證輸出存儲系統中只存在有一致性保障的結果,並且不會出現重複的數據。從本質上說,輸出存儲系統會參與 Flink 的檢查點操作。要做到這一點,輸出存儲系統需要具備「原子提交」的能力。
- 第二種方法是急切地將數據寫入輸出存儲系統,同時牢記這些數據可能是「臟」的,而且需要在發生故障時重新處理。如果發生故障,就需要將輸出、輸入和 Flink 作業全部回滾,從而將「臟」數據覆蓋,並將已經寫入輸出的「臟」數據刪除。注意,在很多情況下,其實並沒有發生刪除操作。例如,如果新記錄只是覆蓋舊紀錄(而不是添加到輸出中),那麼「臟」數據只在檢查點之間短暫存在,並且最終會被修正過的新數據覆蓋。
值得注意的是,這兩種方法恰好對應關係數據庫系統中的兩種為人所熟知的事務隔離級別: 已提交讀(read committed)和未提交讀(read uncommitted)。已提交讀保證所有讀取(查詢輸出)都只讀取已提交的數據,而不會讀取中間、傳輸中或「臟」的數據。之後的讀取可能會返回不同的結果,因為數據可能已被改變。未提交讀則允許讀取「臟」數據;換句話說,查詢總是看到被處理過的最新版本的數據。
某些應用程序可以接受弱一點的語義,所以 Flink 提供了支持多重語義的多種內置輸出算子,如支持未提交讀語義的分佈式文件輸出算子。用戶可以根據輸出存儲系統的能力和應用程序的需求選擇合適的語義。根據輸出存儲系統的類型, Flink 及與之對應的連接器可以一起保證端到端的一致性,並且支持多種隔離級別。
上面的應用程序架構。之所以需要有輸出存儲系統,是因為外部無法訪問 Flink 的內部狀態,所以輸出存儲系統成了查詢目標。但是,如果可以直接查詢狀態,則在某些情況下根本就不需要輸出存儲系統,因為狀態本身就已經包含了查詢所需的信息。這種情況在許多應用程序中真實存在, 直接查詢狀態可以大大地簡化架構,同時大幅提升性能


