darknet是如何對數據集做預處理的
- 2019 年 10 月 3 日
- 筆記
在準備數據集時,darknet並不要求我們預先對圖片resize到固定的size. darknet自動幫我們做了圖像的resize.
darknet訓練前處理
本文所指的darknet版本:https://github.com/AlexeyAB/darknet
./darknet detector train data/trafficlights.data yolov3-tiny_trafficlights.cfg yolov3-tiny.conv.15
main函數位於darknet.c
訓練時的入口函數為detector.c里
void train_detector(char *datacfg, char *cfgfile, char *weightfile, int *gpus, int ngpus, int clear, int dont_show, int calc_map, int mjpeg_port, int show_imgs) { load_args args = { 0 }; args.type = DETECTION_DATA; args.letter_box = net.letter_box; load_thread = load_data(args); loss = train_network(net, train); } 函數太長,只貼了幾句關鍵的.注意args.type = DETECTION_DATA;
data.c中
void *load_thread(void *ptr) { //srand(time(0)); //printf("Loading data: %dn", random_gen()); load_args a = *(struct load_args*)ptr; if(a.exposure == 0) a.exposure = 1; if(a.saturation == 0) a.saturation = 1; if(a.aspect == 0) a.aspect = 1; if (a.type == OLD_CLASSIFICATION_DATA){ *a.d = load_data_old(a.paths, a.n, a.m, a.labels, a.classes, a.w, a.h); } else if (a.type == CLASSIFICATION_DATA){ *a.d = load_data_augment(a.paths, a.n, a.m, a.labels, a.classes, a.hierarchy, a.flip, a.min, a.max, a.size, a.angle, a.aspect, a.hue, a.saturation, a.exposure); } else if (a.type == SUPER_DATA){ *a.d = load_data_super(a.paths, a.n, a.m, a.w, a.h, a.scale); } else if (a.type == WRITING_DATA){ *a.d = load_data_writing(a.paths, a.n, a.m, a.w, a.h, a.out_w, a.out_h); } else if (a.type == REGION_DATA){ *a.d = load_data_region(a.n, a.paths, a.m, a.w, a.h, a.num_boxes, a.classes, a.jitter, a.hue, a.saturation, a.exposure); } else if (a.type == DETECTION_DATA){ *a.d = load_data_detection(a.n, a.paths, a.m, a.w, a.h, a.c, a.num_boxes, a.classes, a.flip, a.blur, a.mixup, a.jitter, a.hue, a.saturation, a.exposure, a.mini_batch, a.track, a.augment_speed, a.letter_box, a.show_imgs); } else if (a.type == SWAG_DATA){ *a.d = load_data_swag(a.paths, a.n, a.classes, a.jitter); } else if (a.type == COMPARE_DATA){ *a.d = load_data_compare(a.n, a.paths, a.m, a.classes, a.w, a.h); } else if (a.type == IMAGE_DATA){ *(a.im) = load_image(a.path, 0, 0, a.c); *(a.resized) = resize_image(*(a.im), a.w, a.h); }else if (a.type == LETTERBOX_DATA) { *(a.im) = load_image(a.path, 0, 0, a.c); *(a.resized) = letterbox_image(*(a.im), a.w, a.h); } else if (a.type == TAG_DATA){ *a.d = load_data_tag(a.paths, a.n, a.m, a.classes, a.flip, a.min, a.max, a.size, a.angle, a.aspect, a.hue, a.saturation, a.exposure); } free(ptr); return 0; }根據a.type不同,有不同的加載邏輯.在訓練時,args.type = DETECTION_DATA,接着去看load_data_detection().
load_data_detection()有兩套實現,用宏#ifdef OPENCV區別開來.我們看opencv版本
load_data_detection() { src = load_image_mat_cv(filename, flag); image ai = image_data_augmentation(src, w, h, pleft, ptop, swidth, sheight, flip, jitter, dhue, dsat, dexp); }注意load_image_mat_cv()中imread讀入的是bgr順序的,用cv::cvtColor做了bgr–>rgb的轉換.
if (mat.channels() == 3) cv::cvtColor(mat, mat, cv::COLOR_RGB2BGR);這裡有個讓人困惑的地方,為什麼是cv::COLOR_RGB2BGR而不是cv::COLOR_BGR2RGB,實際上這兩個enum值是一樣的,都是4.
見https://docs.opencv.org/3.1.0/d7/d1b/group__imgproc__misc.html
image_data_argmentation()的主要邏輯
cv::Mat cropped(src_rect.size(), img.type()); //cropped.setTo(cv::Scalar::all(0)); cropped.setTo(cv::mean(img)); img(new_src_rect).copyTo(cropped(dst_rect)); // resize cv::resize(cropped, sized, cv::Size(w, h), 0, 0, cv::INTER_LINEAR);其實主要就是cv::resize. 這裡cropped的img是在原圖上隨機截取出來的一塊區域(當然是有範圍的).
在load_data_detection()中有這樣一段邏輯,生成pleft,pright,ptop,pbot. 這些參數被傳遞給image_data_argmentation(),用以截取出cropped image.
int oh = get_height_mat(src); int ow = get_width_mat(src); int dw = (ow*jitter); int dh = (oh*jitter); if(!augmentation_calculated || !track) { augmentation_calculated = 1; r1 = random_float(); r2 = random_float(); r3 = random_float(); r4 = random_float(); dhue = rand_uniform_strong(-hue, hue); dsat = rand_scale(saturation); dexp = rand_scale(exposure); flip = use_flip ? random_gen() % 2 : 0; } int pleft = rand_precalc_random(-dw, dw, r1); int pright = rand_precalc_random(-dw, dw, r2); int ptop = rand_precalc_random(-dh, dh, r3); int pbot = rand_precalc_random(-dh, dh, r4); int swidth = ow - pleft - pright; int sheight = oh - ptop - pbot; float sx = (float)swidth / ow; float sy = (float)sheight / oh; float dx = ((float)pleft/ow)/sx; float dy = ((float)ptop /oh)/sy;這麼做的目的是,參考作者AlexeyAB大神的回復:
https://github.com/AlexeyAB/darknet/issues/3703
Your test images will not be the same as training images, so you should change training images as many times as possible. So maybe one of the modified training images of the object coincides with the test image.
這裡,我此前一直有個錯誤的理解,在train和test時對image的preprocess應該是完全一致的.大神的回復意思是,並非如此,在train的時候應該儘可能多地使訓練圖片產生一些變化,因為測試圖片不可能與訓練圖片是完全一致的,這樣的話,才更有可能使測試圖片與某個隨機變化後的訓練圖片吻合.
但是之前,我在issue里有看到有人訓練出來的模型效果並不好,改變了image的preprocess以後,效果就好了.這一點還有待研究.
原始的darknet里圖像的preprocess用的是letterbox_image(),AlexeyAB的版本里用的是resize.據作者說這一改變使得對小目標的檢測效果更好.
參考https://github.com/AlexeyAB/darknet/issues/1907 https://github.com/AlexeyAB/darknet/issues/232#issuecomment-336955485
resize()並不會保持寬高比,letterbox_image()會保持寬高比.作者認為如果你的dataset的train和test中圖像分辨率一致的話,是沒有必要保持寬高比的.
darknet 推導前處理
detector.c中
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh, float hier_thresh, int dont_show, int ext_output, int save_labels, char *outfile) { image im = load_image(input, 0, 0, net.c); image sized = resize_image(im, net.w, net.h); }這裡的resize_image是用C實現的,和cv::resize功能相同
/******update 20190821*********************/
darknet數據預處理
- 數據加載入口函數void load_thread(void ptr)
根據args.type不同有不同加載邏輯 - 餵給模型的輸入並不是你訓練圖片的原始矩陣,darknet自己會做一些數據增強的操作,比如調整對比度,色相,飽和度,對圖片旋轉角度,翻轉圖像等等.
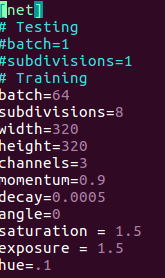
這些是配置在配置文件中的.
具體做了哪些數據增強,要自己看源代碼,args.type不同,加載邏輯也略有差異
以./darknet detector train ….,即做目標檢測的訓練為例的話,對色相/飽和度/對比度的調整代碼如下,位於image.c中

基本上前處理的代碼都位於data.c,image.c中,image.c里是對圖像矩陣的具體操作函數,data.c里是一些調用這些函數的控制流程.
當訓練圖片特別小時,不同的preprocess對餵給模型的代表圖片的矩陣的影響就很大.所以最好先手動resize到模型的input size.
