Spark面试题(四)
- 2021 年 11 月 7 日
- 笔记
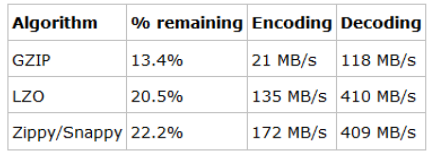
1、Spark中的HashShufle的有哪些不足? 1)shuffle产生海量的小文件在磁盘上,此时会产生大量耗时的、 …
Continue Reading1、Spark中的HashShufle的有哪些不足? 1)shuffle产生海量的小文件在磁盘上,此时会产生大量耗时的、 …
Continue Reading
一、spark structured-streaming 介绍 我们都知道spark streaming …
Continue Reading1、为什么要进行序列化序列化? 可以减少数据的体积,减少存储空间,高效存储和传输数据,不好的是使用的时候要反序列化,非常 …
Continue Reading首发于我的个人博客:Spark面试题(二) 1、Spark有哪两种算子? Transformation(转化)算子和Ac …
Continue Reading
1、spark的有几种部署模式,每种模式特点?(☆☆☆☆☆) 1)本地模式 Spark不一定非要跑在hadoop集群 …
Continue Reading问题描述:DataFrame的join结果不正确,dataframeA(6000无重复条数据) join datafra …
Continue Reading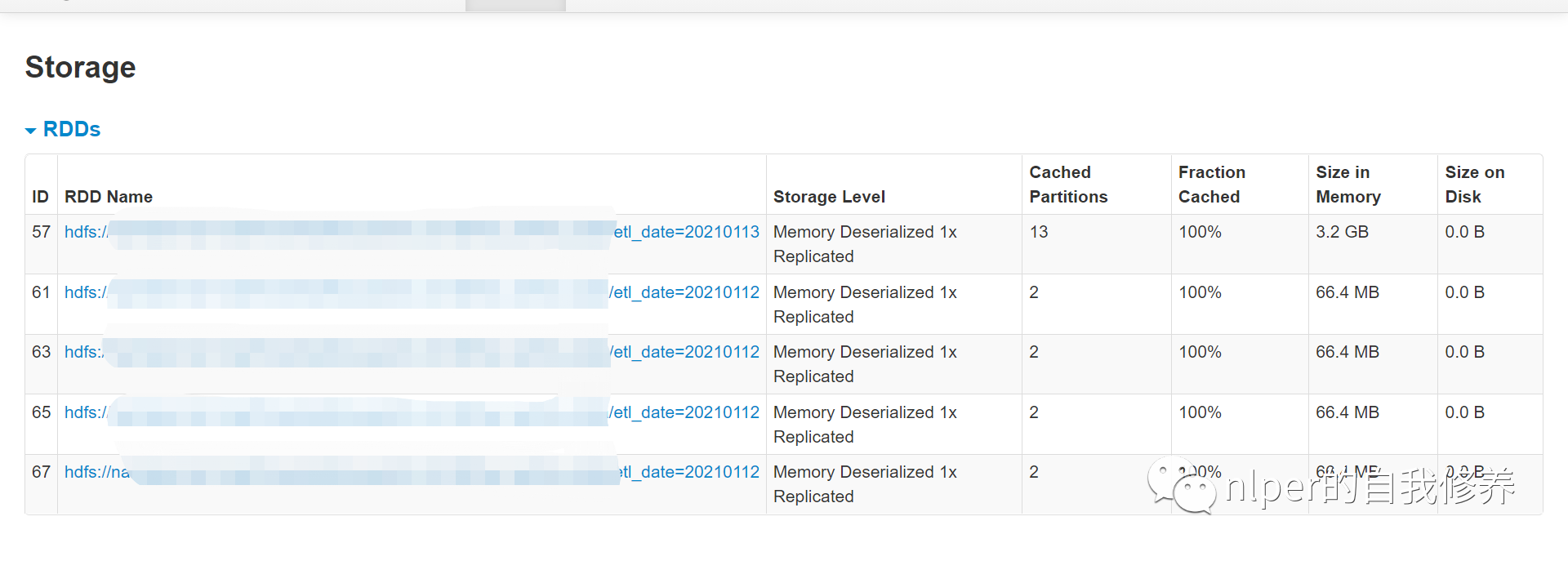
本文内容说明 初始化配置给rdd和dataframe带来的影响 repartition的相关说明 cache&p …
Continue Reading
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境。 本文分享自华为云社区《基于Jupyt …
Continue Reading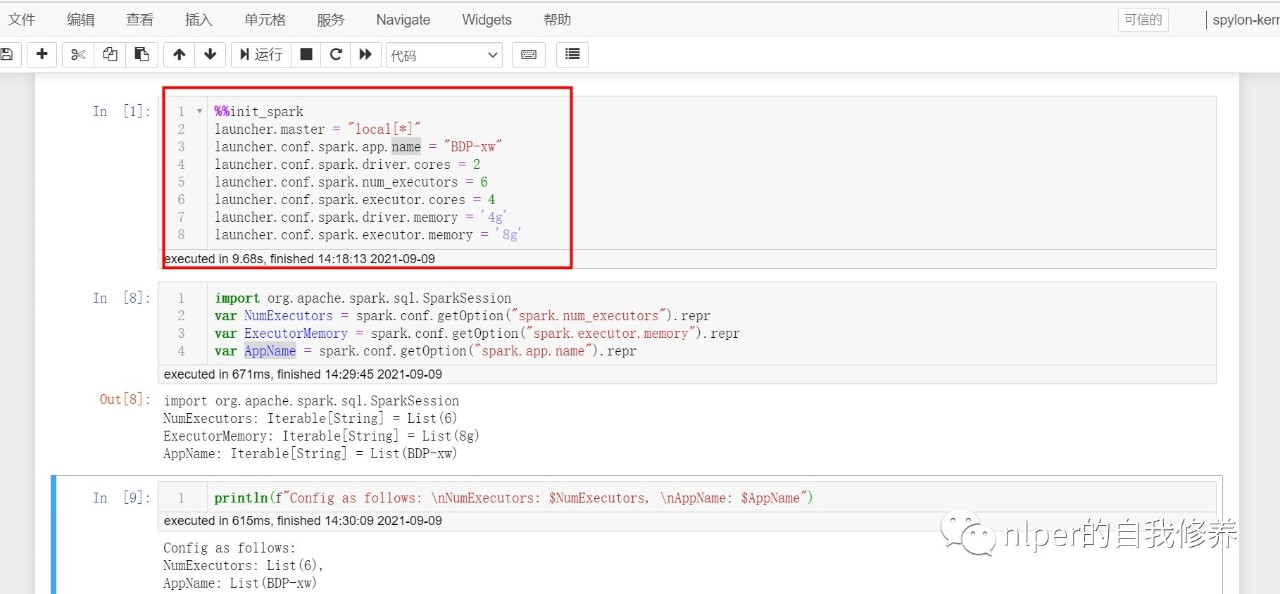
本文环境说明 centos服务器 jupyter的scala核spylon-kernel spark-2.4.0 sca …
Continue Reading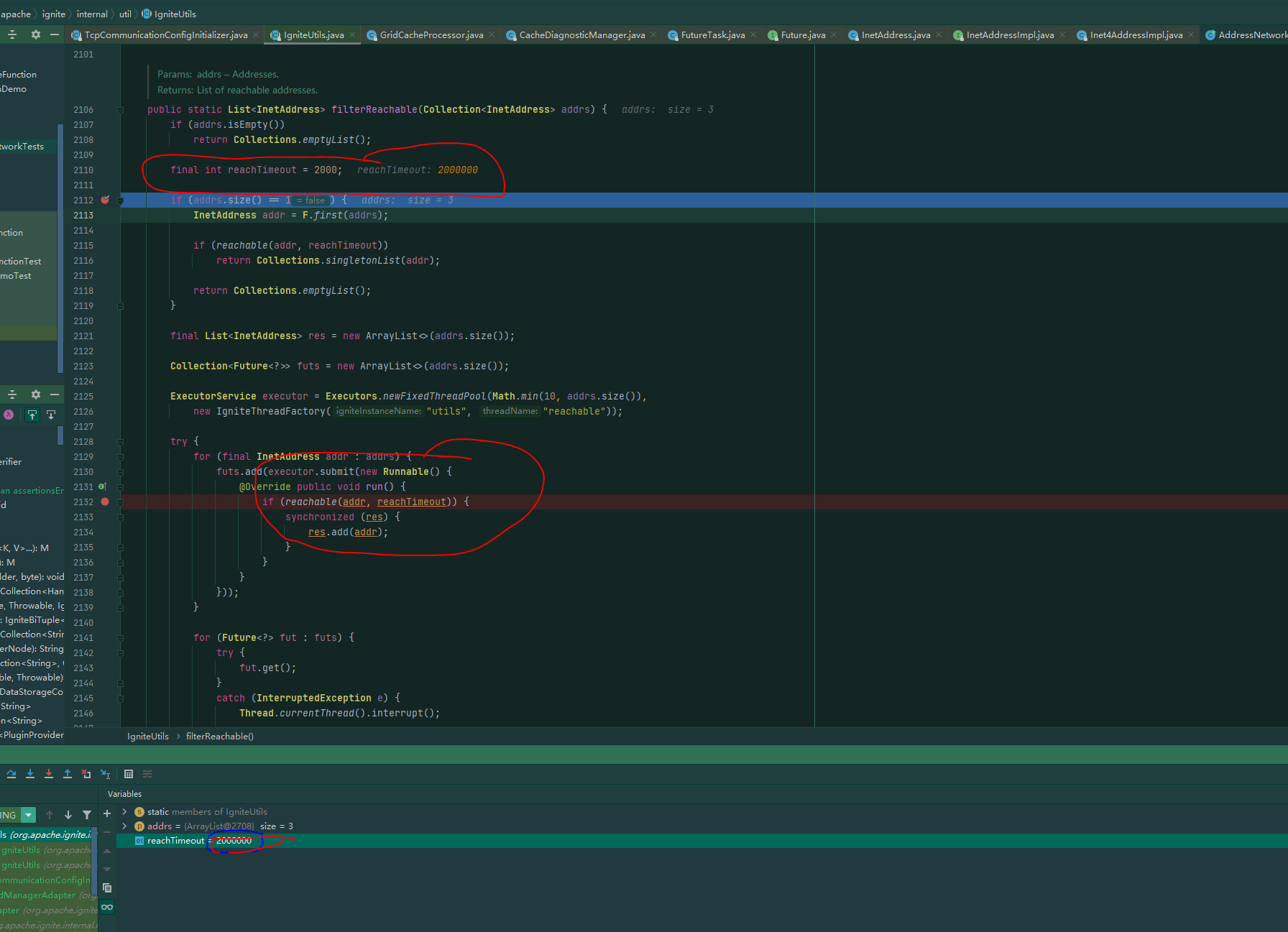
Ignite spark 踩坑记录 简述 ignite访问数据有两种模式: Thin Jdbc模式; Jdbc 模式和I …
Continue Reading