golang实现并发爬虫三(用队列调度器实现)
欲看此文,必先可先看:
上文中的用简单的调度器实现了并发爬虫。
并且,也提到了这种并发爬虫的实现可以提高爬取效率。
当workerCount为1和workerCount为10时其爬取效率是有明显不同的。
然而,文末其实也提到了这个简单调度器实现的爬虫有个不可控或者说是控制力太小了的问题。
究其原因就是因为我们实现的方法是来一个request就给创建一个groutine。
为了让这个程序变得更为可控。得想想怎么可以优化下了。
现在,非常明显,优化点就是我不想要来一个request就创建一个这个实现过程。
那么,我们可以想到队列。
把request放到request队列里。
那么,request队列里一定是会有一个request的头的,我们就可以把这个request的头元素给到worker去做实现。
也就是这样:

but,这样是没有对worker进行一个控制的。
我们希望request可以选择我们想要的一个worker。
那么,我们也可以让scheduler维护一个worker的队列。
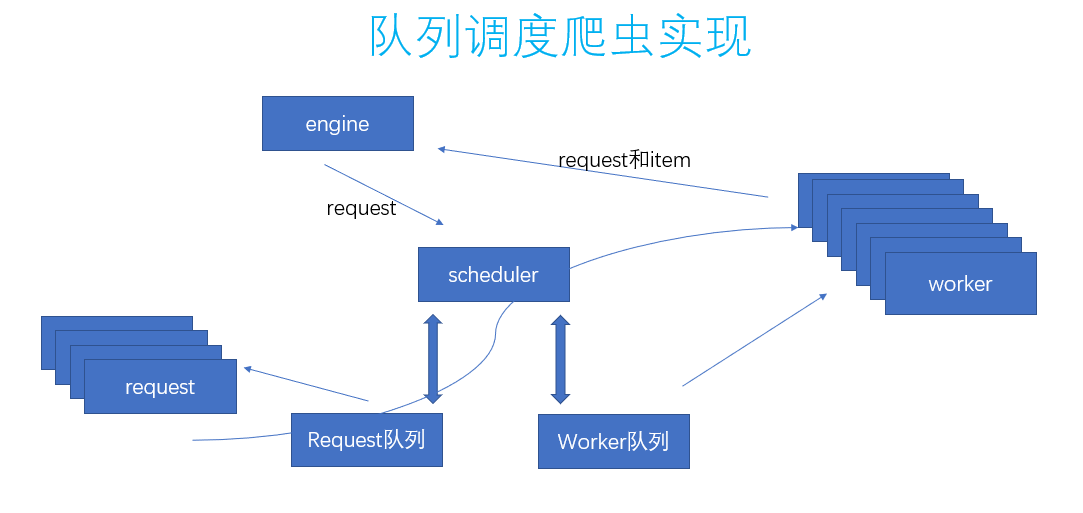
这里用了三个并行的模块:
1.engine 引擎模块。
2.scheduler 调度器模块。
3.worker 工作模块。
这三者通信都是通过channel来通信的。
上图中可知道调度器模块实际上是维护了2个channel,一个是request的channel,一个是worker的channel。
//队列调度器 //这个scheduler与engine和worker之间的通信都是通过channel来连接的。 //故尔它的肚子里应该有request相关的channel和worker相关的channel. //另外注意这里worker的channel的类型是chan Request。 type QueuedScheduler struct { requestChan chan con_engine.Request workerChan chan chan con_engine.Request }
那么,我们就只需要在这个scheduler调度器的两个channel里,各取一个元素,即取request和worker(chan con_engine.Request),把request发给worker就可以了。
一直不断的去取和发送,这就是这个队列调度器要做的事情了。
那个弯曲的箭头也就是指的这个事情了。在request的队列里找到合适的request发给worker队列里合适的worker就好。
这就是一个整体的思想了。
稍微说下关于维护如何两个队列的代码。
重点在于怎么才能做到各读取一个元素。
channel的读取是会阻塞的。
如果我先读取request,如果读取不到,那么在等待的时候就没有办法取到worker了。
解决方案就是用select,因为select会保证一点,select里的每一个case都会被执行到且会很快速的执行。
func (s *QueuedScheduler) Run() { s.requestChan = make(chan con_engine.Request) //指针接收者才能改变里面的内容。 s.workerChan = make(chan chan con_engine.Request) go func() { var requestQ []con_engine.Request var workerQ []chan con_engine.Request for { var activeRequest con_engine.Request var activeWorker chan con_engine.Request if len(requestQ) > 0 && len(workerQ) > 0 { activeRequest = requestQ[0] activeWorker = workerQ[0] } //收到一个request就让request排队,收到一个worker就让worker排队。所有的channel操作都放到select里。 select { case r := <-s.requestChan: requestQ = append(requestQ, r) case w := <-s.workerChan: workerQ = append(workerQ, w) case activeWorker <- activeRequest: requestQ = requestQ[1:] workerQ = workerQ[1:] } } }() }
select就是在做三件事情:
1.从requestChan里收一个request,将这个request存在变量requestQ里。
2.从workerChan里收一个worker,将这个worker存在变量workerQ里。
3.把第一个requestQ里的第一个元素发给第一个workerQ里的第一个元素。
其他代码就感兴趣的同学自己看吧。
作者就先说到这里。
总体调度的思想上面的图中。
具体的实现在源码里。
欢迎大家留言指教。
源码:
//github.com/anmutu/du_crawler/tree/master/04crawler


