4.mysql-进阶
- 2022 年 11 月 17 日
- 笔记
- python全栈开发-mysql 学习
1.事务
将多个操作步骤变成一个事务,任何一个步骤失败,则回滚到事务的所有步骤之前状态,大白话:要成功都成功;要失败都失败。
如转账操作,A扣钱。B收钱,必须两个步骤都成功,才认为转账成功
innodb引擎中支持事务,myisam不支持。
CREATE TABLE `users` ( `id` int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY, `name` varchar(32) DEFAULT NULL, `amount` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
事务的具有四大特性(ACID):
-
原子性(Atomicity)
原子性是指事务包含的所有操作不可分割,要么全部成功,要么全部失败回滚。 -
一致性(Consistency)
执行的前后数据的完整性保持一致。 -
隔离性(Isolation)
一个事务执行的过程中,不应该受到其他事务的干扰。 -
持久性(Durability)
事务一旦结束,数据就持久到数据库
python代码操作
import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root123', charset="utf8", db='userdb') cursor = conn.cursor() # 开启事务 conn.begin() try: cursor.execute("update users set amount=1 where id=1")cursor.execute("update tran set amount=2 where id=2") except Exception as e: # 回滚 conn.rollback() else: # 提交 print("提交") conn.commit() cursor.close() conn.close()
2.锁
在用MySQL时,不知你是否会疑问:同时有很多做更新、插入、删除动作,MySQL如何保证数据不出错呢?
MySQL中自带了锁的功能,可以帮助我们实现开发过程中遇到的同时处理数据的情况。对于数据库中的锁,从锁的范围来讲有:
– 表级锁,即A操作表时,其他人对整个表都不能操作,等待A操作完之后,才能继续。
– 行级锁,即A操作表时,其他人对指定的行数据不能操作,其他行可以操作,等待A操作完之后,才能继续。
MYISAM支持表锁,不支持行锁;
InnoDB引擎支持行锁和表锁。
即:在MYISAM下如果要加锁,无论怎么加都会是表锁。
在InnoDB引擎支持下如果是基于索引查询的数据则是行级锁,否则就是表锁。
所以,一般情况下我们会选择使用innodb引擎,并且在 搜索 时也会使用索引(命中索引)。
接下来的操作就基于innodb引擎来操作:
CREATE TABLE `L1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `count` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
在innodb引擎中,update、insert、delete的行为内部都会先申请锁(排它锁),申请到之后才执行相关操作,最后再释放锁。
所以,当多个人同时像数据库执行:insert、update、delete等操作时,内部加锁后会排队逐一执行。
而select则默认不会申请锁。
2.1 排它锁
import pymysql import threading def task(): conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root123', charset="utf8", db='userdb') cursor = conn.cursor(pymysql.cursors.DictCursor) # cursor = conn.cursor() # 开启事务 conn.begin() cursor.execute("select id,age from tran where id=2 for update") # fetchall ( {"id":1,"age":10},{"id":2,"age":10}, ) ((1,10),(2,10)) # {"id":1,"age":10} (1,10) result = cursor.fetchone() current_age = result['age'] if current_age > 0: cursor.execute("update tran set age=age-1 where id=2") else: print("已售罄") conn.commit() cursor.close() conn.close() def run(): for i in range(5): t = threading.Thread(target=task) t.start() if __name__ == '__main__': run()
2.2 共享锁
共享锁( lock in share mode),可以读,但不允许写。
加锁之后,后续其他事物可以可以进行读,但不允许写(update、delete、insert)
SELECT * FROM parent WHERE NAME = 'Jones' LOCK IN SHARE MODE;
3.数据库连接池
3.1 连接池创建
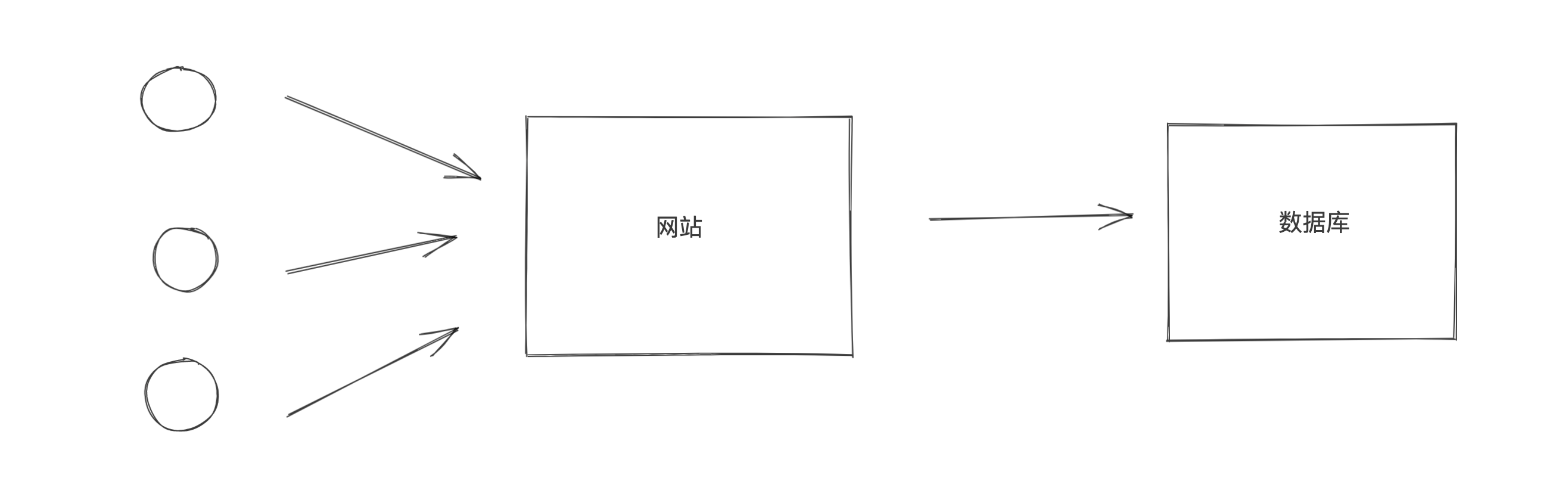
在操作数据库时需要使用数据库连接池。数据库池可以避免频繁的连接和断开数据库带来的损耗
pip install pymysql
pip install dbutils
import threading import pymysql from dbutils.pooled_db import PooledDB MYSQL_DB_POOL = PooledDB( creator=pymysql, # 使用链接数据库的模块 maxconnections=5, # 连接池允许的最大连接数,0和None表示不限制连接数 mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建 maxcached=3, # 链接池中最多闲置的链接,0和None不限制 blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错 setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."] ping=0, # ping MySQL服务端,检查是否服务可用。 # 如:0 = None = never, 1 = default = whenever it is requested, # 2 = when a cursor is created, 4 = when a query is executed, 7 = always host='127.0.0.1', port=3306, user='root', password='root123', database='userdb', charset='utf8' ) def task(): # 去连接池获取一个连接 conn = MYSQL_DB_POOL.connection() cursor = conn.cursor(pymysql.cursors.DictCursor) cursor.execute('select sleep(2)') result = cursor.fetchall() print(result) cursor.close() # 将连接交换给连接池 conn.close() def run(): for i in range(10): t = threading.Thread(target=task) t.start() if __name__ == '__main__': run()
3.2 SQL工具类的使用
3.2.1 基于模块创建单例模式
# db.py import pymysql from dbutils.pooled_db import PooledDB class DBHelper(object): def __init__(self): # TODO 此处配置,可以去配置文件中读取。 self.pool = PooledDB( creator=pymysql, # 使用链接数据库的模块 maxconnections=5, # 连接池允许的最大连接数,0和None表示不限制连接数 mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建 maxcached=3, # 链接池中最多闲置的链接,0和None不限制 blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错 setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."] ping=0, # ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always host='127.0.0.1', port=3306, user='root', password='root123', database='userdb', charset='utf8' ) def get_conn_cursor(self): conn = self.pool.connection() cursor = conn.cursor(pymysql.cursors.DictCursor) return conn, cursor def close_conn_cursor(self, *args): for item in args: item.close() def exec(self, sql, **kwargs): conn, cursor = self.get_conn_cursor() cursor.execute(sql, kwargs) conn.commit() self.close_conn_cursor(conn, cursor) def fetch_one(self, sql, **kwargs): conn, cursor = self.get_conn_cursor() cursor.execute(sql, kwargs) result = cursor.fetchone() self.close_conn_cursor(conn, cursor) return result def fetch_all(self, sql, **kwargs): conn, cursor = self.get_conn_cursor() cursor.execute(sql, kwargs) result = cursor.fetchall() self.close_conn_cursor(conn, cursor) return result db = DBHelper()
3.2.2 基于上下文使用数据库池
如果你想要让他也支持 with 上下文管理。
# db_context.py import threading import pymysql from dbutils.pooled_db import PooledDB POOL = PooledDB( creator=pymysql, # 使用链接数据库的模块 maxconnections=5, # 连接池允许的最大连接数,0和None表示不限制连接数 mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建 maxcached=3, # 链接池中最多闲置的链接,0和None不限制 blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错 setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."] ping=0, host='127.0.0.1', port=3306, user='root', password='root123', database='userdb', charset='utf8' ) class Connect(object): def __init__(self): self.conn = conn = POOL.connection() self.cursor = conn.cursor(pymysql.cursors.DictCursor) def __enter__(self): return self def __exit__(self, exc_type, exc_val, exc_tb): self.cursor.close() self.conn.close() def exec(self, sql, **kwargs): self.cursor.execute(sql, kwargs) self.conn.commit() def fetch_one(self, sql, **kwargs): self.cursor.execute(sql, kwargs) result = self.cursor.fetchone() return result def fetch_all(self, sql, **kwargs): self.cursor.execute(sql, kwargs) result = self.cursor.fetchall() return result
4.索引
在数据库中索引最核心的功能就是:**加速查找**
4.1 索引的原理
索引的底层是基于B+Tree的数据结构存储的
据库的索引是基于上述B+Tree的数据结构实现,但在创建数据库表时,如果指定不同的引擎,底层使用的B+Tree结构的原理有些不同。
-
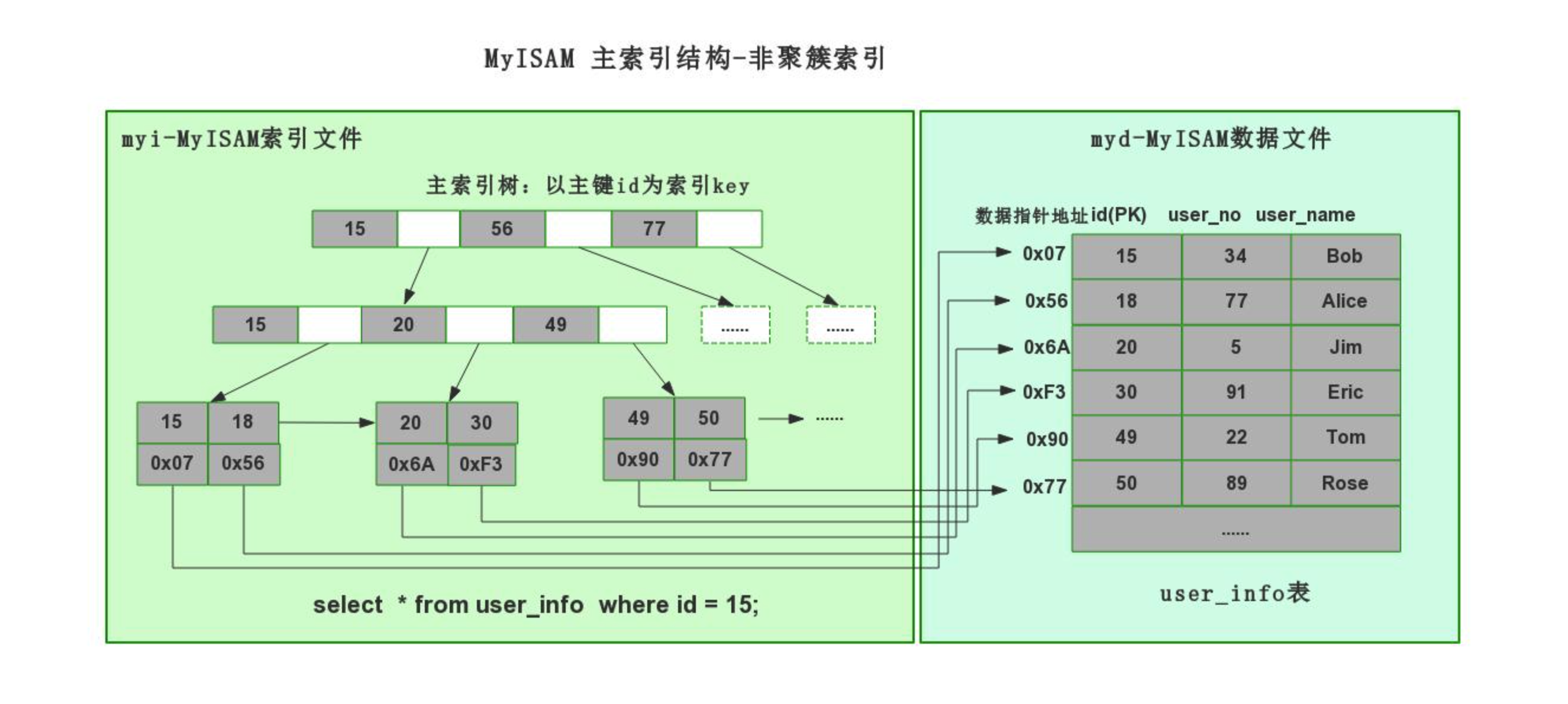
myisam引擎,非聚簇索引(数据 和 索引结构 分开存储)
-
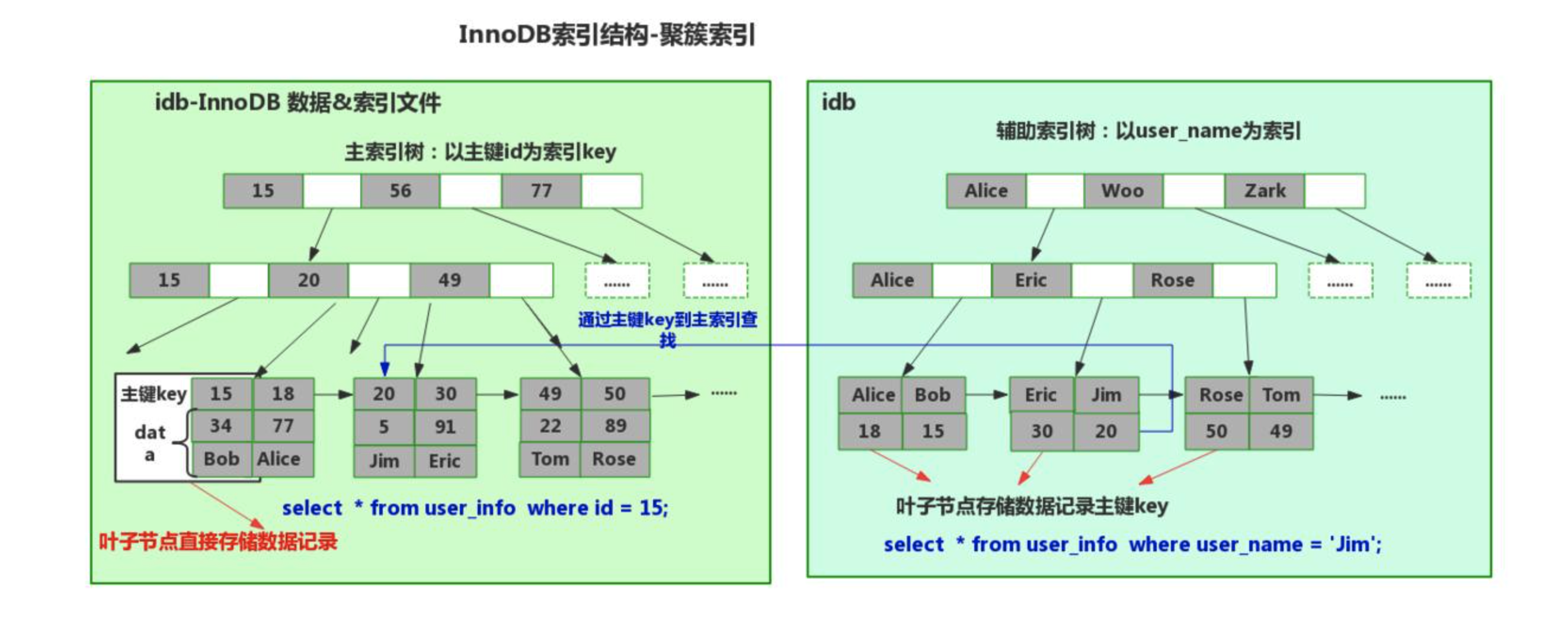
innodb引擎,聚簇索引(数据 和 主键索引结构存储在一起)
在企业开发中一般都会使用 innodb 引擎(内部支持事务、行级锁、外键等特点),在MySQL5.5版本之后默认引擎也是innodb
4.1.1 非聚簇索引(mysiam引擎)
create table 表名( id int not null auto_increment primary key, name varchar(32) not null, age int )engine=myisam default charset=utf8;
4.1.2
create table 表名( id int not null auto_increment primary key, name varchar(32) not null, age int )engine=innodb default charset=utf8;
4.2 常见的索引
**建议不要随意添加索引,因为索引也是需要维护的,太多的话反而会降低系统的性能。**
开发过程中常见的索引类型有:
- 主键索引:加速查找、不能为空、不能重复。
create table 表名( id int not null auto_increment primary key, -- 主键 name varchar(32) not null );
- 唯一索引:加速查找、不能重复。
create table 表名( id int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, unique ix_name (name), -- 唯一索引 unique ix_email (email), );
- 普通索引:加速查找。
create table 表名( id int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, index ix_email (email), -- 普通索引 index ix_name (name),);
- 组合索引
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);
4.3 索引失效
会有一些特殊的情况,让我们无法命中索引(即使创建了索引),这也是需要大家在开发中要注意的。
- 类型不一样
select * from info where name = 123; -- 未命中 特殊的主键: select * from info where id = "123"; -- 命中
- 使用不等于
select * from info where name != "kunmzhao"; -- 未命中 特殊的主键: select * from big where id != 123; -- 命中
- or的使用
当or条件中有未建立索引的列才失效select * from big where id = 123 or password="xx"; -- 未命中
- like的使用
select * from big where name like "%u-12-19999"; -- 未命中 select * from big where name like "wu-%-10"; -- 未命中 特别的: select * from big where name like "wu-1111-%"; -- 命中 select * from big where name like "wuw-%"; -- 命中
- 排序的使用
当根据索引排序时候,选择的映射如果不是索引,则不走索引select * from big order by name asc; -- 未命中 select * from big order by name desc; -- 未命中 特别的主键: select * from big order by id desc; -- 命中
- 最左前缀原则, 如果是联合索引,要遵循最左前缀原则。
如果联合索引为:(name,password) name and password -- 命中 name -- 命中 password -- 未命中 name or password -- 未命中
5.函数
MySQL中提供了很多函数,为我们的SQL操作提供便利,例如:
CHAR_LENGTH(str) 返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。 对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。 CONCAT(str1,str2,...) 字符串拼接 如有任何一个参数为NULL ,则返回值为 NULL。 CONCAT_WS(separator,str1,str2,...) 字符串拼接(自定义连接符) CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base) 进制转换 例如: SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D) 将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。 例如: SELECT FORMAT(12332.1,4); 结果为: '12,332.1000' INSERT(str,pos,len,newstr) 在str的指定位置插入字符串 pos:要替换位置其实位置 len:替换的长度 newstr:新字符串 特别的: 如果pos超过原字符串长度,则返回原字符串 如果len超过原字符串长度,则由新字符串完全替换 INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len) 返回字符串str 从开始的len位置的子序列字符。 LOWER(str) 变小写 UPPER(str) 变大写 LTRIM(str) 返回字符串 str ,其引导空格字符被删除。 RTRIM(str) 返回字符串 str ,结尾空格字符被删去。 SUBSTRING(str,pos,len) 获取字符串子序列 LOCATE(substr,str,pos) 获取子序列索引位置 REPEAT(str,count) 返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。 若 count <= 0,则返回一个空字符串。 若str 或 count 为 NULL,则返回 NULL 。 REPLACE(str,from_str,to_str) 返回字符串str 以及所有被字符串to_str替代的字符串from_str 。 REVERSE(str) 返回字符串 str ,顺序和字符顺序相反。 RIGHT(str,len) 从字符串str 开始,返回从后边开始len个字符组成的子序列 SPACE(N) 返回一个由N空格组成的字符串。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len) 不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str) 返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。
6.存储过程
储过程,是一个存储在MySQL中的SQL语句集合,当主动去调用存储过程时,其中内部的SQL语句会按照逻辑执行。
- 创建存储过程
delimiter $$ create procedure p1() BEGIN select * from d1; END $$ delimiter ;
- 执行存储过程
call p1();
#!/usr/bin/env python # -*- coding:utf-8 -*- import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root123', db='userdb') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 执行存储过程 cursor.callproc('p1') result = cursor.fetchall() cursor.close() conn.close() print(result)
- 删除存储过程
drop procedure proc_name;


