“三剑客”之sed手中有剑
一、sed介绍
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器。sed是操作、过滤和转换文本内容的强大工具。常用功能包括对文件实现快速增删改查(增加、删除、修改、查询),其中查询的功能中最常用的两大功能是过滤(过滤指定字符串)、取行(取出指定行)
sed通过执行下面的循环来操作输入流中的每一行: 首先,sed读取输入流中的一行,移除该行的尾随换行符,并将其放入到pattern space中。然后对pattern space中的内容执行SCRIPT中的sed命令,每个sed命令都可以关联一个地址:地址是一种条件判断代码,只有符合条件的行才会执行相应的命令。当执行到SCRIPT(指的是我们定义的操作)的尾部时,除非指定了”-n”选项,否则pattern space中的内容将写到标准输出流中,并添加回尾随的换行符。然后进入下一个循环开始处理输入流中的下一行。
但有些特殊命令(如”D”命令)会进入多行模式,使得SCRIPT循环结束 时将数据锁在pattern space中不输出也不清空,甚至在SCRIPT循环还没结束时就强行进入下一 轮SCRIPT循环,其实就相当 于在上面的while循环结构中加上了”continue”关键字。此外还有命令(如”d”)可以直接退出 SCRIPT循环进入下一个sed循环,就像是在while循环中加上了”break”一样。甚至还有直接退出 sed循环的命令(只有2个这样的命令:”q”和”Q”),就像是加上了”exit”一样。
sed的执行过程是一个循环的过程:
- 读取输入流的一行到模式空间。
- 对模式空间中的内容进行匹配和处理。(这里一般都是我们进行操作的地方,增删改查等)
- 自动输出模式空间内容。
- 清空模式空间内容。
二、基本选项
命令格式:
sed的命令格式:sed [options] 'command' file(s);
sed的脚本格式:sed [options] -f scriptfile file(s);
基本选项如下:
-e :直接在命令行模式上进行sed动作编辑,此为默认选项;
-f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作;
-i :直接修改文件内容,sed是通过创建一个临时文件并将输入写入到该临时文件,然后重命名为源文件来实现的
-n :只打印模式匹配的行;
-r :支持扩展表达式,sed所支持的扩展正则表达式和egrep一样
-s : 考虑为多个单独的文件,而不是把多个文件作为一个流进行输入
-h或--help:显示帮助;
-V或--version:显示版本信息。
实例练习:首先我们准备文件test.txt,内容如下
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
5、It was fun 。I had a very happy weekend。
[root@lgh test]# sed -n '3p' test.txt #打印第三行
3、I did my homework and watched TV。 On Sunday morning ,
[root@lgh test]# sed '=' test.txt #打印行号
1
1、Last weekend, I was busy。
2
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3
3、I did my homework and watched TV。 On Sunday morning ,
4
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
5
5、It was fun 。I had a very happy weekend。
[root@lgh test]# sed -r -n '/[a-z]*ing/p' test.txt #正则匹配ing字符串
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
三、定址选择
这里所说的地址选择就是我们要处理一个文档中的哪些行?比如第1行到第3行,这就是用来选择匹配我们需要进行处理的行。
当sed将输入流中的行读取到模式空间后,就需要对模式空间中的内容进行匹配,如果能匹配就能执行对应的命令,如果不能匹配就直接输出、清空模式空间并进入下一个sed循环读取下一行。
定址表达式有多种,其格式为[ADDR1][,ADDR2]。这可以分为3种方式:
- ADDR1和ADDR2都省略时,表示所有行都能被匹配上。
- 省略ADDR2时,表示只有被ADDR1表达式匹配上的行才符合条件。
- 不省略ADDR2时,是范围地址。表示从ADDR1匹配成功的行开始,到ADDR2匹配成功的行结束。
‘NUMBER’:指定一个行号,sed将仅只匹配该行。(需要注意,除非使用了”-s”或”-i”选项,sed将对所有输入文件的行连续计数。)
‘FIRST~STEP’:FIRST和STEP都是非负数。该定址表达式表示从第FIRST行开始,每隔STEP行就再取一次。要选择所有的奇数行,使用“1~2”;
‘$’:该符号匹配的是最后一个文件的最后一行,如果指定了”-i”或”-s”,则匹配的是每个文件的最后一行。
‘/REGEXP/‘:该定址表达式将选择那些能被正则表达式REGEXP匹配的所有行。如果REGEXP中自身包含了字符”/”,则必须使用反斜线进行转义,即”\/”。
‘/REGEXP/I’:正则表达式的修饰符”I”是GNU的扩展功能,表示REGEXP在匹配时不区分大小写。
‘/REGEXP/M’:可以让sed直接匹配多行模式下(multi-line mode)的位置。该修饰符使得正则表达式的元字符”^”和”$”匹配分别匹配每个新行后的空字符和新行前的空字符。还有另外两个特殊的字符序列(\`和\’,分别是反斜线加反引号,反斜线加单引号),它们总是匹配buffer空间中的起始和结束位置。此外,元字符点”.”不能匹配多行模式下的换行符。
(注:在单行模式下,使用M和不使用M是没有区别的,但在多行模式下各符号匹配的位置将和通常的正则表达式元字符匹配的内容不同,各符号的匹配位置如下图所示)
‘0,/REGEXP/’:使用行号0作为起始地址也是支持的,就像此处的”0,/REGEXP/”,这时sed会尝试对第一行就匹配REGEXP。换句话说,”0,/REGEXP/”和”1,/REGEXP/”基本是相同的。但以行号0作为起始行时,如果第一行就能被ADDR2匹配,范围搜索立即就结束,因为第二个地址已经搜索到了;如果以行号1作为起始行,会从第二行开始匹配ADDR2,直到匹配成功。
‘ADDR1,+N’:匹配ADDR1和其后的N行。
‘ADDR1,~N’:匹配ADDR1和其后的行直到出现N的倍数行,倍数可为随意整数倍。 (注:可以是任意倍,只要N的倍数是最接近且大于ADDR1的即可。如ADDR1=1,N=3匹配1到3行,ADDR1=5,N=4匹配5-8行。
注意:sed采用计数器计算,每读取一行,计数器加1,直到最后一行。因此在读到最后一行前,sed是不知道这次输入流中总共有多上行,也不知道最后一行是第几行。”$”符号表示最后一行,它只是一个特殊的标识符号。当sed读取到输入流的尾部时,sed就会为该行打上该标记。无法使用”$”参与数学运算,例如无法使用$-1表示倒数第二行,因为sed在读到最后一行前,它并不知道这是倒数第二行,此时也还没打”$”标记,因此$-1是错误的定址表达式。另一方面,sed只能通过一次输入流,这意味着已经读取过的行无法再次被读取,所以sed不提供往回取数据的定址表达式
常用的正则匹配模式:
^ 匹配行开始,如:/^sed/匹配所有以sed开头的行;
$ 匹配行结束,如:/sed$/匹配所有以sed结尾的行;
. 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d;
* 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行;
[] 匹配一个指定范围内的字符,如/[ss]ed/匹配sed和Sed;
[^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行;
\(..\) 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers;
& 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**;
\< 匹配单词的开始,如:/\
\> 匹配单词的结束,如/love\>/匹配包含以love结尾的单词的行;
x\{m\} 重复字符x,m次,如:/0\{5\}/匹配包含5个0的行;
x\{m,\} 重复字符x,至少m次,如:/0\{5,\}/匹配至少有5个0的行;
x\{m,n\} 重复字符x,至少m次,不多于n次,如:/0\{5,10\}/匹配5~10个0的行;
实例 :
[root@lgh test]# sed -n 1,3p test.txt #输出1-3行
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
[root@lgh test]# sed -n 1p test.txt #输出第一行
1、Last weekend, I was busy。
[root@lgh test]# sed -n 1,/On/p test.txt #输出第一行到匹配到On字符串的行
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
[root@lgh test]# sed -n 1,/[a-z]*ing/p test.txt #输出第一行到匹配到ing字符串的行
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
[root@lgh test]# sed -r -n 1,/[a-z]*ing/p test.txt
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
[root@lgh test]# sed -r -n 1,+2p test.txt #输出从第一行开始以及后两行
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
[root@lgh test]# sed -n 1,~2p test.txt #从第一行开始输出到2的倍数行
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
[root@lgh test]# sed -n 3,~2p test.txt #从第3行开始输出到2的倍数行
3、I did my homework and watched TV。 On Sunday morning ,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
[root@lgh test]# sed -n 1~2p test.txt #输出从第一行开始,步长为的2的行
1、Last weekend, I was busy。
3、I did my homework and watched TV。 On Sunday morning ,
5、It was fun 。I had a very happy weekend。
[root@lgh test]# sed -n /on/I,/with/Ip test.txt #输出匹配on到with的行,忽略大小写
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
我们知道匹配到我们需要操作的行的时候,开始进行我们需要的操作,请继续看下文
四、常用命令
常用命令如下:
a 在当前行下面插入文本;
i 在当前行上面插入文本;
c 把选定的行改为新的文本;
d 删除,删除选择的行;
D 删除模板块的第一行;
s 替换指定字符;
h 拷贝模板块的内容到内存中的缓冲区;
H 追加模板块的内容到内存中的缓冲区;
g 获得内存缓冲区的内容,并替代当前模板块中的文本;
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面;
l 列表不能打印字符的清单;
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令;
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码;
p 打印模板块的行。 P(大写) 打印模板块的第一行;
q 退出Sed;
b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾;
r file 从file中读行;
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
w file 写并追加模板块到file末尾;
W file 写并追加模板块的第一行到file末尾;
! 表示后面的命令对所有没有被选定的行发生作用;
= 打印当前行号;
# 把注释扩展到下一个换行符以前;
1、强制输出命令p
默认情况下sed会输出所有的行,使用-n可以禁用默认的输出,然后使用p指定自己想输出的行。
[root@lgh test]# sed 1,2p test.txt #没事使用-n,所以1,2行重复答应,两种输出模式不冲突
1、Last weekend, I was busy。
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
5、It was fun 。I had a very happy weekend。
[root@lghtest]# sed -n 1,2p test.txt #输出1,2行
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
2、删除命令d
命令”d”用于删除整个模式空间中的内容,并立即退出当前SCRIPT循环,进入下一个sed循环,即读取下一行
[root@lgh test]# sed 3,5d test.txt #删除第3行到第5行的数据
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
修改test.txt内容如下:
#!/bin/bash
#test
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
5、It was fun 。I had a very happy weekend。
[root@lghtest]# sed '/^#/{1!d}' test.txt #删除以#开头的行,第一行例外
#!/bin/bash
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
5、It was fun 。I had a very happy weekend。
如果”d”后面还有命令,在删除模式空间后,这些命令不会执行,因为会立即退出当前SCRIPT循环
3、退出命令q或者Q
“q”和”Q”命令的作用是立即退出当前sed程序,使其不再执行后面的命令,也不再读取后面的行。因此,在处理大文件或大量文件时,使用”q”或”Q”命令能提高很大效率。它们之间的不同之处在于”q”命令被执行后还会使用自动输出动作输出模式空间的内容,除非使用了”-n”选项。而”Q”命令则会立即退出,不会输出模式空间内容。另外,可以为它们指定退出状态码,例如”q 1″
[root@lgh test]# sed '3q' test.txt #输出钱3行,类似 head -3
#!/bin/bash
#test
1、Last weekend, I was busy。
[root@lgh test]# sed -n '/[a-z]*ing/{p;q}' test.txt #找到一条ing的字符串,输出并退出
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
4、输出行号=
“=”命令用于输出最近被读取行的行号。在sed内部,使用行号计数器进行行号计数,每读取一行,行号计数器加1。
[root@lgh test]# sed -n '/[a-z]*ing/{p;=;q}' test.txt #找到一条ing的字符串,输出行并输出行号,然后退出
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
4
5、字符一一对应替换命令”y”
该命令和”tr”命令的映射功能一样,都是将字符进行一一替换
[root@lghtest]# sed 'y/ing/ING/' test.txt #把文档中的ing一一对应替换成ING
#!/bIN/bash
#test
1、Last weekeNd, I was busy。
2、ON Saturday morNING, my classmate aNd I had Math traINING class。 Saturday afterNooN,
3、I dId my homework aNd watched TV。 ON SuNday morNING ,
4、I weNt to HaNG zhou MeteorolGIcal ExperIeNce Hall wIth my famIly。
5、It was fuN 。I had a very happy weekeNd。
6、读取下一行命令”n”
在sed的循环过程中,每个sed循环的第一步都是读取输入流的下一行到模式空间中,这是我们无法控制的动作。但sed有读取下一行的命令”n”。
[root@lgh test]# sed -n '/[a-z]*ing/{p;n;p}' test.txt #输出匹配到ing字符串的一行和下一行
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
[root@lgh test]# sed -n '/[a-z]*ing/{p;n;n;p}' test.txt #输出匹配到ing字符串的一行和下下行
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
7、替换命令s
命令格式:s/REGEXP/REPLACEMENT/FLAGS
功能就是替换,首先需要匹配,然后再替换,常用的选项如下:
g 表示行内全面替换;
p 表示打印行;
\1 子串匹配标记;
& 已匹配字符串标记;
修改test.txt的内容如下:
#!/bin/bash
#test test1 test2 test3
#test4 test5 test6 test7
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
5、It was fun 。I had a very happy weekend。
[root@lgh test]# sed -n 's/test/TEST/p' test.txt #替换并打印,默认替换第一列
#TEST test1 test2 test3
#TEST4 test5 test6 test7
[root@lgh test]# sed -n 's/test/TEST/gp' test.txt #全局替换
#TEST TEST1 TEST2 TEST3
#TEST4 TEST5 TEST6 TEST7
[root@lgh test]# sed -n 's/test/TEST/2p' test.txt #指定列替换
#test TEST1 test2 test3
#test4 TEST5 test6 test7
[root@lgh test]# sed -n '5,$s/ing/***&***/p' test.txt #给匹配到的字符串添加*
2、On Saturday morn***ing***, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morn***ing*** ,
[root@lgh test]# sed -n '5,$s/^/#/p' test.txt #在第5行到最后一行添加注释
#2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
#3、I did my homework and watched TV。 On Sunday morning ,
#4、I went to Hang zhou Meteorolgical Experience Hall with my family。
#5、It was fun 。I had a very happy weekend。
[root@mvxl2685 test]# echo 'cmd1 && cmd2 || cmd3' | sed 's%&&\(.*\)||\(.*\)%\&\&\2||\1%' #cmd1 && cmd2 || cmd3"的cmd2和cmd3命令对调个位置
cmd1 && cmd3|| cmd2
8、追加(a)、插入(i)、修改(c)
三种格式是”[a|i|c] TEXT”,表示将TEXT内容队列化到内存中,当有输出流或者说有输出动作的时候,半路追上输出流,分别追加、插入和替换到该输出流然后输出。追加是指追加在输出流的尾部,插入是指插入在输出流的首部,替换是指将整个输出流替换掉。”c”命令和”a”、”i”命令有一丝不同,它替换结束后立即退出当前SCRIPT循环,并进入下一个sed循环,因此”c”命令后的命令都不会被执行。
[root@mvxl2685 test]# sed '/ing/a good job' test.txt #在匹配行后面追加
#!/bin/bash
#test test1 test2 test3
#test4 test5 test6 test7
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
good job
3、I did my homework and watched TV。 On Sunday morning ,
good job
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
5、It was fun 。I had a very happy weekend。
[root@mvxl2685 test]# sed '/ing/i good job' test.txt #在匹配行前面插入
#!/bin/bash
#test test1 test2 test3
#test4 test5 test6 test7
1、Last weekend, I was busy。
good job
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
good job
3、I did my homework and watched TV。 On Sunday morning ,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
5、It was fun 。I had a very happy weekend。
[root@mvxl2685 test]# sed '/ing/c good job' test.txt #修改匹配行
#!/bin/bash
#test test1 test2 test3
#test4 test5 test6 test7
1、Last weekend, I was busy。
good job
good job
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
5、It was fun 。I had a very happy weekend。
9、多行模式命令”N”、”D”、”P”
- “N”命令:读取下一行内容追加到模式空间的尾部。其和”n”命令不同之处在于:”n”命令会输出模式空间的内容(除非使用了”-n”选项)并清空模式空间,然后才读取下一行到模式空间,也就是说”n”命令虽然读取了下一行到模式空间,但模式空间仍然是单行数据。而”N”命令在读取下一行前,虽然也有自动输出和清空模式空间的动作,但该命令会把当前模式空间的内容锁住,使得自动输出的内容为空,也无法清空模式空间,然后读取下一行追加到当前模式空间中的尾部。追加时,原有内容和新读取内容使用换行符”\n”分隔,这样在模式空间中就实现了多行数据。即所谓的”多行模式”。 另外,当无法读取到下一行时(到了文件尾部),将直接退出sed程序,使得”N”命令后的命令不会再执行,这和”n”命令是一样的。
- “D”命令:删除模式空间中第一个换行符”\n”之前的内容,然后立即回到SCRIPT循环的顶端,即进入下一个SCRIPT循环。如果”D”删除后,模式空间中已经没有内容了,则SCRIPT循环自动退出进入下一个sed循环;如果模式空间还有剩余内容,则继续从头执行SCRIPT循环。也就是说,”D”命令后的命令不会被执行。
- “P”命令:输出模式空间中第一个换行符”\n”之前的内容
[root@mvxl2685 test]# cat test.txt #查看文件内容
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
5、It was fun 。I had a very happy weekend。
[root@mvxl2685 test]# sed -n 'n;p' test.txt
#首先把第一行加载到模式空间,然后执行n,把第二行加载到模式空间,覆盖了第一条,然后执行p进行打印,输出第2条数据,继续自动加载第3条到模式空间,执行n,加载第4条覆盖第3条,输出第4条
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
[root@mvxl2685 test]# sed -n 'N;p' test.txt
#加载第一条到模式空间,执行N,把第2条也加载进去,执行p,一起答应两条,然后接着加载3,N命令加载4,p打印两条,接着加载5,N命令执行为空,到了尾部,直接结束sed命令
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
[root@mvxl2685 test]# sed -n '$!N;p' test.txt
#加载第一条到模式空间,执行N,把第2条也加载进去,执行p,一起答应两条,然后接着加载3,N命令加载4,p打印两条,接着加载5,到了尾部,跳过N命令,执行p,打印第5条
1、Last weekend, I was busy。
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
5、It was fun 。I had a very happy weekend。
[root@mvxl2685 test]# sed -n '$!N;P' test.txt
#加载第一条到模式空间,执行N,把第2条也加载进去,执行P,这里只打印\n前的数据,也就是第一条,然后接着加载3,覆盖模式空间,N命令加载4,P打印第3条,接着加载5,到了尾部,跳过N命令,执行P,打印第5条
1、Last weekend, I was busy。
3、I did my homework and watched TV。 On Sunday morning ,
5、It was fun 。I had a very happy weekend。
[root@mvxl2685 test]# sed 'N;D' test.txt
#加载第一条到模式空间,执行N,加载第二条到模式空间,D删除\n前面的数据,保留第二条,然后加载第三条,删除第二条,依次类推,
5、It was fun 。I had a very happy weekend。
[root@mvxl2685 test]# sed -n '/training/{N;p}' test.txt #打印匹配行以及下一行
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
3、I did my homework and watched TV。 On Sunday morning ,
[root@mvxl2685 test]# sed -n '/training/{N;s/\n//;p}' test.txt #合并两行
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,3、I did my homework and watched TV。 On Sunday morning ,
[root@mvxl2685 test]# sed -n '/training/{N;s/\n//p}' test.txt #合并两行
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,3、I did my homework and watched TV。 On Sunday morning ,
10、buffer空间数据交换命令”h”、”H”、”g”、”G”、”x”
sed除了维护模式空间(pattern space),还维护另一个buffer空间:保持空间(hold space)。这两个空间初始状态都是空的。
绝大多数时候,sed仅依靠模式空间就能达到目的,但有些复杂的数据操作则只能借助保持空间来实现。之所以称之为保持空间,是因为它是暂存数据用的,除了仅有的这几个命令外,没有任何其他命令可以操作该空间,因此借助它能实现数据的持久性。
保持空间的作用很大,它和模式空间之间的数据交换能实现很多看上去不能实现的功能,是实现sed高级功能所必须的,常用的几个命令如下:
- “h”命令:将当前模式空间中的内容覆盖到保持空间。
- “H”命令:在保持空间的尾部加上一个换行符”\n”,并将当前模式空间的内容追加到保持空间的尾部。
- “g”命令:将保持空间的内容覆盖到当前模式空间。
- “G”命令:在模式空间的尾部加上一个换行符”\n”,并将当前保持空间的内容追加到模式空间的尾部。
- “x”命令:交换模式空间和保持空间的内容。
注意,无论是交换、追加还是覆盖,原空间的内容都不会被删除。
可能理解起来不是很好理解,画个图就轻松易懂了:
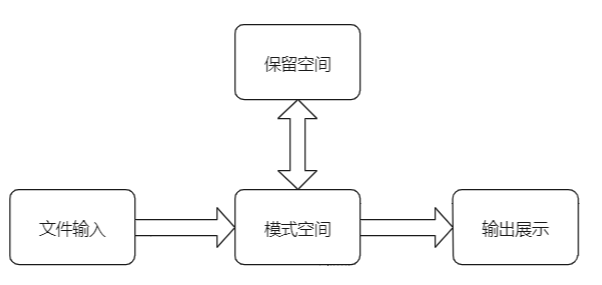
在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。
[root@mvxl2685 test]# sed -n '/training/p' test.txt #打印匹配的行
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
[root@mvxl2685 test]# sed -n '/training/{h;n;G;p}' test.txt #打印匹配的行和下一行,并交换位置
3、I did my homework and watched TV。 On Sunday morning ,
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
[root@mvxl2685 test]# sed -n '/training/{h;G;p}' test.txt #两次打印匹配的行
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
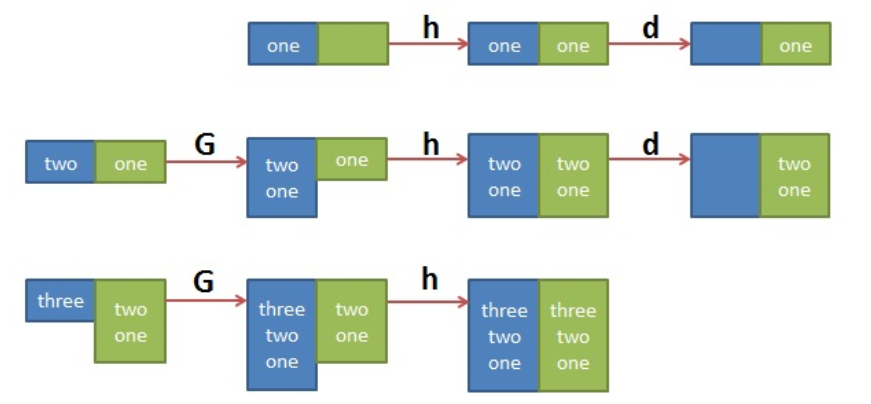
[root@mvxl2685 test]# sed '1!G;h;$!d' test.txt #逆序打印文件
5、It was fun 。I had a very happy weekend。
4、I went to Hang zhou Meteorolgical Experience Hall with my family。
3、I did my homework and watched TV。 On Sunday morning ,
2、On Saturday morning, my classmate and I had Math training class。 Saturday afternoon,
1、Last weekend, I was busy。
逆序打印思路如下:
参考地址:
//www.cnblogs.com/f-ck-need-u/p/7478188.html
//www.cnblogs.com/f-ck-need-u/p/7488469.html
//www.linuxprobe.com/linux-sed-command.html
//blog.csdn.net/weixin_38149264/article/details/78074300
//blog.csdn.net/yangbin1265712/article/details/82994666

