nodejs简单抓包工具
- 2019 年 10 月 3 日
- 笔记
就是简简单单写程序的我为什么需要抓包?
其实在平时写demo的时候需要用到一些图片和文本的资源的,但是需求量比较大,这个时候就想去网站上面直接复制啊,然后图片另存为啊,什么的一系列繁琐的操作。
但是现在不需要了,你只要看到这篇文章,你就很轻松了。
本项目Github地址: https://github.com/xiaoqiuxiong/reptileDemo
1.在你的电脑桌面新建一个reptileDemo文件夹。
然后进入文件夹,然后在改文件夹目录下打开cmd。输入下图所示回车,连续按回车即可。
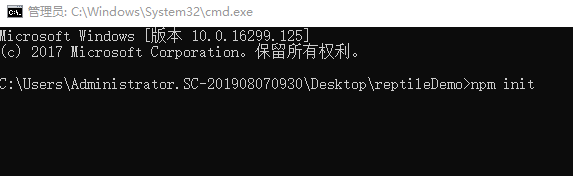
初始化完之后,你会在文件夹里面看下package.json文件,里面就是一些基本的包管理基本配置。
2.cmd输入下图所示,然后回车

这步是安装cheerio模块,主要是用来解释html和使用jqueryAPI来操作请求返回的html。
3.cmd输入下图所示,然后回车

这步是安装request模块,主要是用来发请求处理的。
4.文件夹内添加一个data文件夹,用来存放抓包的数据。
5.文件夹内新建app.js文件。添加内容如下:
let fs = require('fs'); let cheerio = require('cheerio'); let request = require('request'); let path = require('path'); let i = 0; let j = 0; //初始需要抓取的页面url let url = "http://www.silver.org.cn/cjyw/list_p_1.html"; let http = url.includes('https') ? require('https') : require('http'); function startRequest(x) { // 采用http模块向服务器发起一次get请求 http.get(x, function(res) { // 用来存储请求网页的整个html内容 var html = ''; var titles = []; // 防止中文乱码 res.setEncoding('utf-8'); // 监听data事件,每次取一块数据 res.on('data', function(chunk) { html += chunk; }); // 监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数 res.on('end', function() { // 采用cheerio模块解析html var $ = cheerio.load(html); j = 0; savedContent($); i++; console.log('抓包页码:' + i); // 限制请求页数 if (i <= 10) { fetchPage(`http://www.silver.org.cn/cjyw/list_p_${i}.html`); } else { console.log('抓包完成'); }; }); }).on('error', function(err) { console.log(err); }); } //保存内容 function savedContent($) { var item = $('.lt_col li')[j] // 标题 var x = $(item).find('h2').text().trim(); // 内容 var y = $(item).find('p').text().trim(); // 图片地址 var z = $(item).find('img').attr('src'); // 图片文件名 var o = path.basename(z); // 创建文件夹 fs.mkdir(`./data/${x}`, err => { if (!err) { // 保存文本 fs.appendFile(`./data/${x}/index.txt`, `标题:${x}n内容:${y}`, 'utf-8', err => { if (err) { console.log(`****创建txt失败****: ${x}`); } }); // 保存图片 request.head(z, (err, res, body) => { if (err) { console.log(`****请求图片失败****: ${x}`); } }); // 写图片到本地 request(z).pipe(fs.createWriteStream(`./data/${x}/${o}`)); j++; if (j <= $('.lt_col li').length - 1) { savedContent($) } } }) } startRequest(url); //主程序开始运行
本项目主要是抓取一个新闻网站的新闻列表数据,有标题,内容和图片。
6.package.json修改如下:
"scripts": { "test": "echo "Error: no test specified" && exit 1", "dev": "node app.js" },
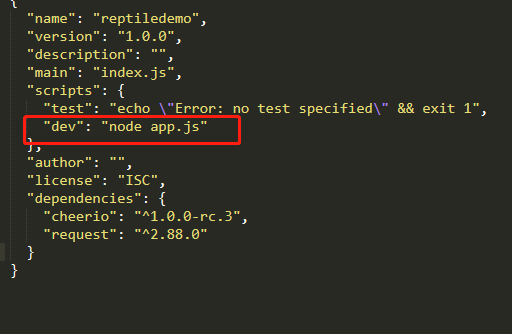
完结。
做完上面操作之后你就可以使用cmd,然后输入

预览


这样就搞定了,是不是很爽啊。
