操作系统学习笔记8 |段页式内存管理
多进程图像中的CPU管理已经告一段落,接下来要介绍另一大方面——内存管理。首先我们也来看看内存是如何被使用起来的。最后介绍段页式内存管理的实现过程。
参考资料:
-
课程:哈工大操作系统(本部分对应 L20 && L21 && L22 && L23)
-
这一部分的难度仅次于学习笔记5
1. 内存的使用与分段
1.1 内存管理的直观想法
冯·诺依曼的存储程序思想:取指执行。这种体系结构下的内存使用即程序放到内存中,PC指向开始地址。
下面从一段程序开始,如下图:
程序编译成汇编后,里面的标号偏移是从0开始的,例如 enrty 是 0,_main 的偏移是 40。而 40 就是 main函数开始的地方。
- 接下来需要将程序放入内存中。
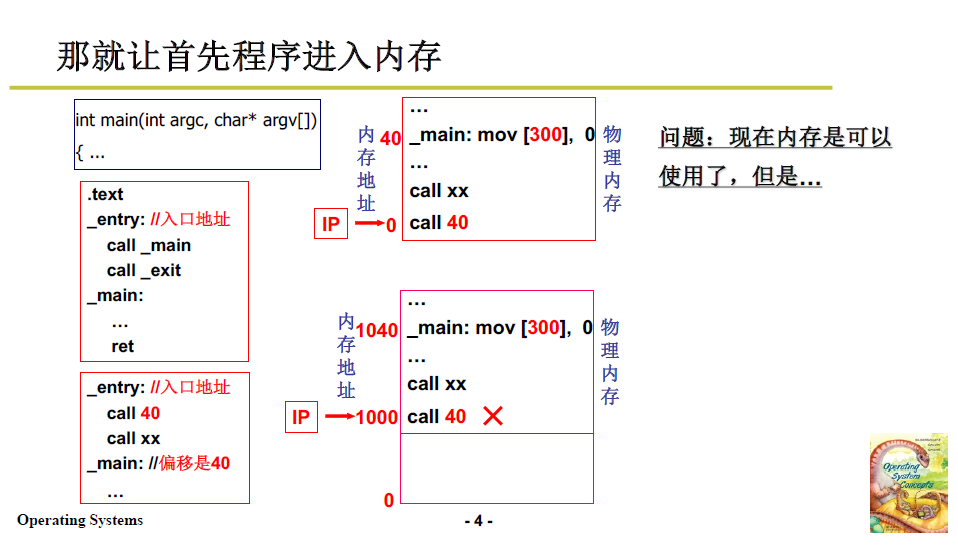

用磁盘读,就可以将指令读入内存,但是最重要的问题是把程序放到内存的哪个地方。
-
最直观的想法是 按照偏移放到物理内存的对应位置,这段程序也就必须放到物理内存的0地址处
-
但是问题很明显:前面也提到过,0地址一般是操作系统使用的,并不空闲;而且,按照这样的约定,所有的程序起始地址都是0,这不就冲突了?
-
所以实际上应当是在内存中找一段空闲的单元,再将程序加载进来。
-
但是这样,地址就对不上了,如上图,按照指令跳到了40,但40处是系统程序/不空闲,本应当跳到1040.
-
所以必须要修改上图程序中的 40.
将程序中的 逻辑地址/相对地址 重新定位到 真实的物理地址。
!重定位!
1.2 重定位
什么时候做重定位?
-
编译时:
-
这种需要在编译时就知道哪里是空闲的,并且编译时空闲不代表装入时空闲。
-
因此需要预定,而预定就比较难做。
-
对于嵌入式系统(静态系统),烧入程序后不再改变,那么编译时重定位就没有上述缺点。
扩展资料:PE文件结构重定位表
-
-
载入时:
- 在载入程序时,根据内存的空余情况统一进行地址换算,更灵活,更适用于PC机等通用设备。
- 因为载入过程中需要修改,比较慢。
两种方式的特点:
- 编译时重定位程序只能放在内存的固定位置;
- 载入时重定位程序一旦载入内存就不能动了。
因此载入时重定位还有问题,因为程序载入内存后还需要移动。


操作系统为了合理利用内存,程序载入内存后,如果进入阻塞或者睡眠,很可能会被 交换 到磁盘上,临时给别的程序腾出空间,再交换回内存后,不一定是原来的位置了。


1.3 运行时重定位
因此,载入时重定位也不好,应当是 运行时重定位。
-
在运行每条指令时才完成重定位,每执行一条指令都要从逻辑地址算出物理地址,也叫地址翻译
跟前面的两种方式不同,不是修改程序中的地址,而是动态地将地址翻译为物理地址(根据Base + 逻辑地址)
有个问题就是,base放在哪里?
-
每个进程都有自己的基址,并且,每次进程由等待队列进入CPU执行时的基址都会相应发生改变
-
因此,base 放在 PCB中。
-
对应的有相应的基地址寄存器,专门用来存放基地址,在硬件层面进行加速;
在进程切换的时候,会将PCB中的基地址放到基地址寄存器中,之后这个进程执行的每条指令的寻址,都会加上这个基地址.


1.4 小总结:上述过程梳理
梳理一下上文的过程。
- 由于多进程图像,进程1的程序自地址2000起始,进程2的程序从地址1000开始存放。分别把 2000 和 1000 放入各自PCB。
- 在取指执行时,指令进入CPU,100 的逻辑地址加上 2000 这个 基地址,就对地址为 2100 的数据进行了操作。
- 当进程切换时,将进程2 PCB 中的基地址 替换进程1的 基地址寄存器。
- 接下来执行进程2 时,逻辑地址100 就会加上 基地址 1000,处理进程2的数据。


1.5 程序分段
程序是整个放入/载入内存中的吗?
- 在程序员眼中,程序不是完整一块儿,而是由若干 部分/段 组成的。如下图中的代码段、变量集data段、函数段。
- 每个段都有各自的用途和特点:比如代码段只读,代码段/数据段不会动态增长,栈段可以动态地单向增长,函数库段可能不会在一开始就载入,并且有也不是所有函数库都载入;
- 每个段的逻辑地址都从0开始;
- 引入段后的地址定位是 <段号,段内偏移>
- 所以采用分治思想可以使得用户单独考虑每个段如何存放数据,使得操作更有针对性和灵活性;


所以我们拟采用 将程序分段放入内存 的方法。对于堆栈段来讲,分段的优点:
-
栈是可以动态增长的,如果空间不够了,那么栈段可以单独的再重新分配,而不需要给整个程序的数据重新分配
这里的背景知识是给程序分配的内存不够了怎么办?处理方法是整段搬迁。如果程序不分段,就是整个程序空间的搬迁,这样效率很低。
采用这种方法的相应措施是寻址方式的相应调整:
-
PCB中存储所有段的基地址
-
寻址:段地址+段内偏移
比如第1段的300和第3段的300 ,重定位后的物理地址并不同。
-
进程执行时,PCB中的段地址赋值给各自的段基址寄存器
- 如数据段是DS,指令段是CS
- 有一个表来记录:下图中,PCB中有一个进程段表,保存了每个段的段号、基址、长度、读写标志
jmpi 100,cs(cs=0),这时就是从基址180再偏移100进行寻址。


此前 学习笔记1的setup.s理解 中曾提到过 jmpi 0,8,接着就是使用GDT表进行查表跳转(8相当于CS是段的基地址,0是偏移量)。
GDT 表实际上就是 进程段表,只不过GDT对应的是OS(看做一个进程)对应的段表,GDT唯一;而每个进程都对应一个自己的进程段表 LDT表。
LDT: Local Descriptor table
1.6 真正的寻址:GDT + LDT
上面1.5中 简略形象的进程段表在具体程序中的表现就是GDT表的格式;如下图右上所示:
GDT 里放 操作系统的各个段 和 LDT,LDT 放进程的各个段基址及其他情况。


总结梳理一下:
- 程序按照数据的不同用途分成多个段,每个段分别加载到内存的空闲区域,每个段的基址、长度等信息存放在LDT表中
- 初始化好的 LDT 赋值给 PCB,可以通过 PCB 找到该进程的LDT表,接着在执行指令时通过 LDT 表查出段基址,加上指令本身的偏移就得到了物理地址
- 段基址+程序中的相对地址 = 物理内存地址
- ldtr寄存器是做什么用的?
- 存放段编号,是查找LDT表的索引 (相当于数组下标)
- 之前讲学习笔记5中拆解线程和内存管理的时候,提到的内存映射表,就是LDT表
1.7 补充:Linux 0.11 的分段处理方式
-
根据此前进程的相关学习,Linux0.11 下 TCB/PCB 的实现都是靠一个 task_struct 结构体;这个结构体里面还有一个结构体 tss
-
tss里面放的内容可以理解为是当前进程的CPU快照,存储了CPU所有寄存器的值,也就保存了当前进程的状态。
-
由于进程切换,段寄存器的内容就放在task_struct 里的 tss了
1.8 简单总结
-
内存使用 -> 程序分段装入内存 -> 重定位 -> 运行时重定位 -> LDT&GDT查表
-
对于其他进程,也是同样的流程。
-
进程切换时,切换LDT表,这也就是此前提到过的内存映射表。
注意:LDT 是一个硬件概念,是一组寄存器。
这部分内容对应实验六。
2. 内存分区与分页
- 上面从程序员视角、程序装入内存的角度,我们将程序分成不同的段;
- 下面从内存的角度,看一看内存本身是怎么分区的。
2.1 内存使用过程
上面第一部分的学习角度,对于内存使用过程而言,还有缺陷;
-
编译时,程序分成了多个段:代码段、数据段…
-
在内存中找到若干块空闲的区域,用于存放多个段;
段可以不连续。
问题是内存为什么可以一块一块的被找到呢(内存怎么分割)?如何找到空闲的区域呢?这就是第二部分内存分区要解决的问题。
-
将程序的各个段从磁盘中载入到找到的空闲内存区域中,并初始化LDT表,与PCB关联起来
这部分涉及磁盘管理和设备驱动,需要后续讲。
初始化 LDT 以及与 PCB 关联,就是第一部分后半截讲到的内容。
2.2 内存分区
2.2.1 分区策略
内存分区有两种思路:固定分区 和 可变分区:
- 固定分区:在操作系统初始化时将可用内存等长划分,但很显然不合适,因为程序各不相同,每个程序的段也有大有小;
- 可变分区:根据段请求的需求进行内存划分。
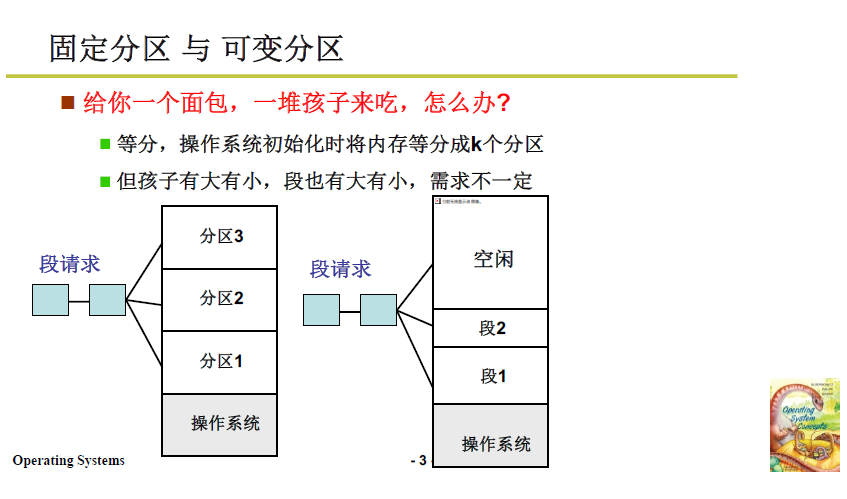

2.2.2 可变分区的管理思路
想法其实非常简单,对已分配和未分配的区域分别进行打表(数据结构),每次段请求时就查阅表格,分出相应内存时再将表格进行对应的修改。整个过程就跟 记账取物 差不多。
- 首先是用已分配分区表记录 被占用内存区域的起始地址和长度。
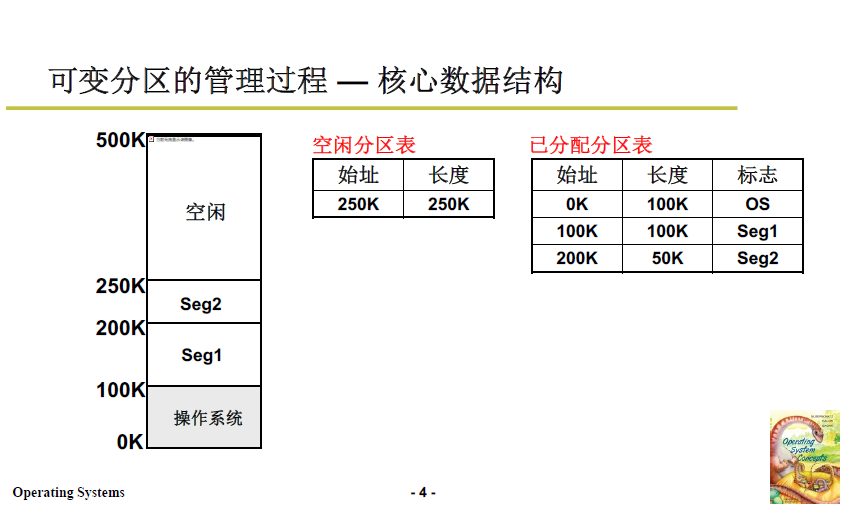

- 当段请求到来,根据请求从空闲内存划分相应区域;并修改空闲分区表和已分配分区表;
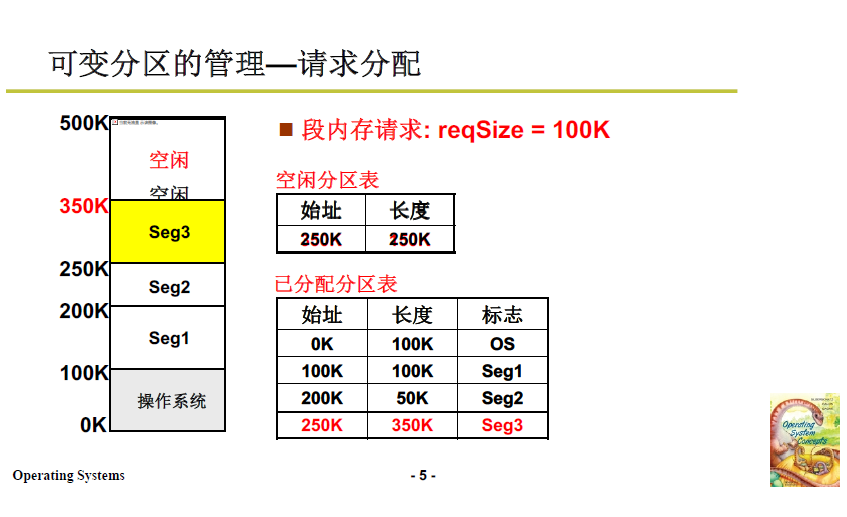

- 当某段程序不再需要,如下图段2(200K到250K),则在空闲分区表增加一项,在已分配分区表中去除第三项。
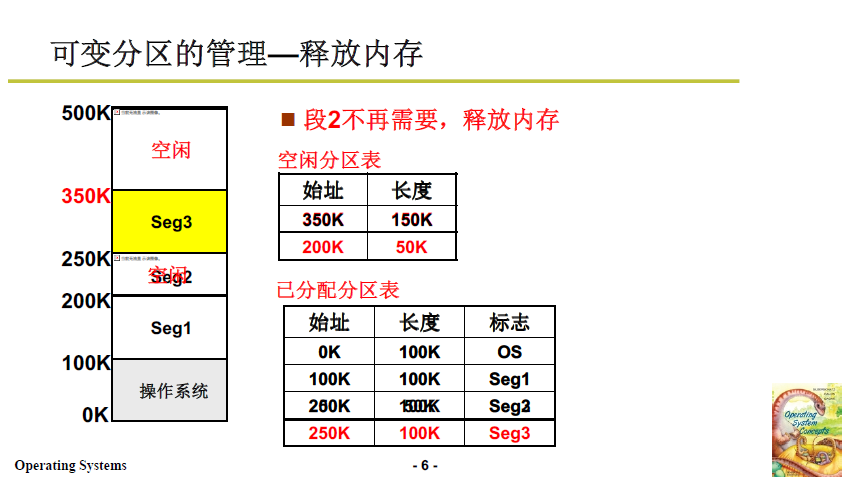

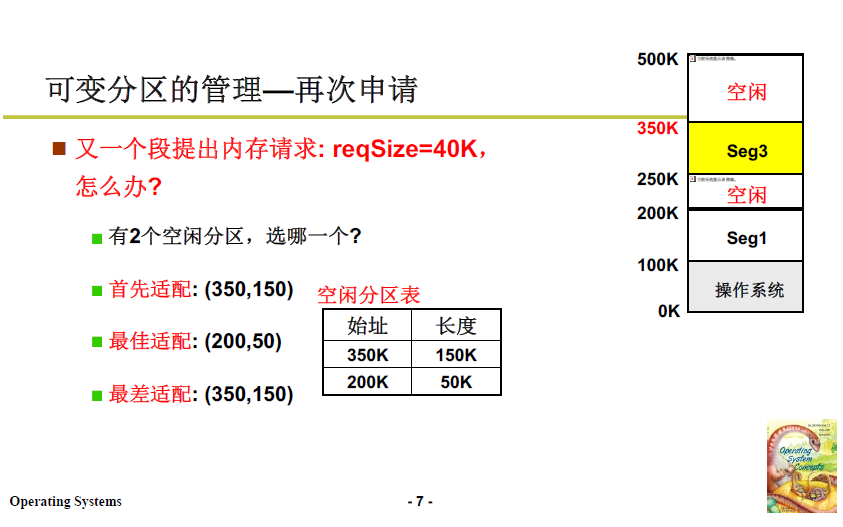
当段请求再次到来 reqSize = 40K,此时有两个空闲区域,且都能满足需要,应该分配到哪一块中?接下来就涉及算法了。
2.2.3 空闲分区选择算法
- 最佳适配:
- 找到跟请求大小最接近的区域,即下图中的50K大小的区域;
- 空闲分区会越割越细,越割越碎。
- 最差适配:
- 找到跟请求大小最不适配的区域,即下图长度150K的区域;
- 空闲分区会趋于均匀。
- 首先适配:
- 找到第一个满足请求大小的区域就放入;
- 这样时间复杂度很低。
可见这几种算法个有特点,很难说哪个更为优秀,只能讲合不合适。

这里 2.3 和 2.4 就是 数据结构(表) + 算法(选择算法) 的结合
现代操作系统并不是通过内存分区来做的,而是通过内存分页。分区算法实际上是虚拟内存的划分方式,这个留待后话。
段对应的虚拟内存中的分区,虚拟内存又要对应的分页的物理内存上,这个后面讲了段页结合的内存管理就理解了
2.3 内存分页
2.3.1 分区的问题
内存分区带来的问题也显而易见,无论哪种分区选择算法,最后都会带来“破碎”的内存,如若最后到来一个大小为160K的段请求,就会出现没有一个空闲分区能够适配的情况,但实际上空闲分区加起来能够超过160K。
当然也是可以解决的:移动内存分区,使内存紧缩,让内存空闲分区扩大。
但是内存紧缩这种方法花费时间较大;并且移动过程要考虑到每个进程的 LDT 修改,内存移动过程中CPU不能执行上层用户程序,相当于死机了。
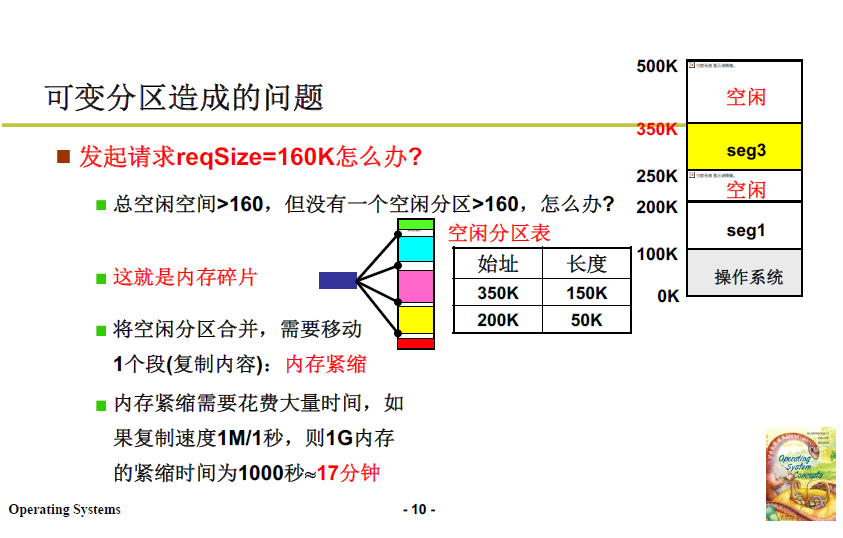

所以还有一种想法,即将请求大小 160K 打散。
2.3.2 分页的处理方法
上面分区的方法中,内存就像面包,被切碎,最后剩下了谁都不想要的碎屑;而分页的考虑就是,将面包切成片,将内存分成页。
-
操作系统初始化时,将物理内存分为大小一定的页;
- 实际上就是限制最小可划分的内存单元,避免过小碎片的产生;
- 在 学习笔记1的main.c部分 中的 mem_map 就是完成上述的初始化工作,将内存打成 4k 为单位的页,若被使用则为1,空闲则为0.
-
针对每个段的内存请求,系统一页一页地分配给这个段,并向上取整。
-
这样就避免了内存分区效率低的问题,并且不需要内存紧缩。由于设置了最小可分单元–页,一个程序最多浪费 4K-1 的内存空间。


物理内存的角度要求内存浪费尽可能少,而用户/程序员 角度更能理解分段的思想。所以后续会继续介绍分页和分段结合起来的综合办法。
2.3.3 寻址方式
段被打散为页,但跟分区一样,程序在以页为单位的内存中同样需要被寻址才能被执行。
-
比如,我们需要执行一个
jmp 40这个指令,我们需要知道 40 被分配到了哪一页上。 -
假设页的大小为100,那么40在第0页;
同段的页共用一套逻辑地址,因为是同一个程序中的地址。比如页1的地址就是从100~199
-
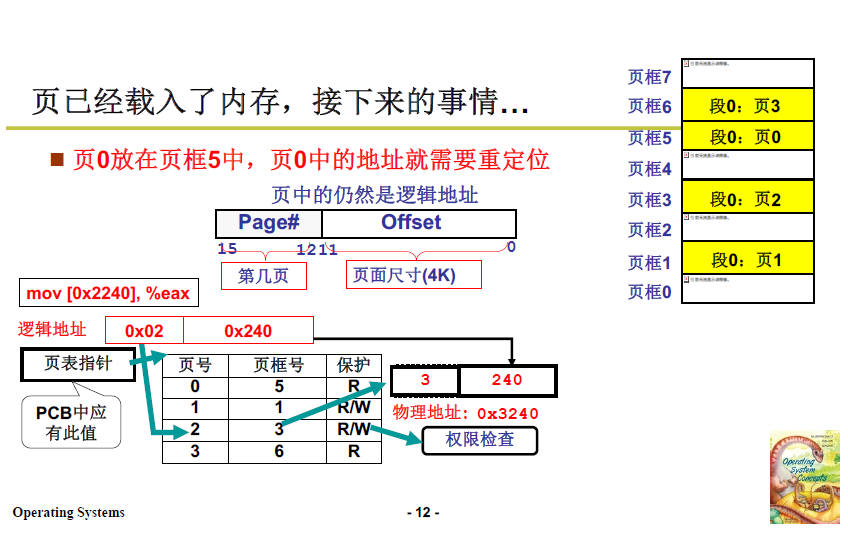
物理地址怎么算?第0页放在第5页框(物理内存度量),所以实际上应当是540.
逻辑地址结构如下图所示:一共16位,高4位表示查询页表的索引,低12位是偏移量,也意味着页的大小(最大偏移)为 4K。
4K 的设计在16进制中正好是3位,对于一个地址来说,右移3位即可得到它所在的页。
寻址过程如下图所示:
页表索引寄存器 cr3 存储页表相关信息(之前的段表索引寄存器是ldtr),同样的,PCB 关联了页表(有指向页表的指针),在切换进程时,用 PCB 指向的页表对 CR3 进行赋值。
页表索引寄存器 CR3 存储 页号、页框号和权限检查。
表用来建立逻辑地址与物理地址的联系。
实际的物理地址=物理页框号对应的物理基地址+逻辑地址的低12位。
实例:
-
对于指令
mov [0x2240],%eax,首先寻址 [0x2240]; -
0x2240 右移3位(4k)得到0x2,余数为 0x240,这表示地址所在的页号为2,页内偏移为240;
-
拿着页号 2 查找页表索引,得到页框号 3;
还是注意区分页号和页框号。页号是逻辑地址的分页,页框号是物理地址的分块单元(也意味着首地址)。
-
3*4k + 240 即为真实物理地址 3240。
-
上述寻址过程由 MMU,内存管理单元 在硬件层面完成。

2.4 简单总结
程序分段,如果按段放入内存,内存会出现无法利用的大量碎片,所以建立最小内存划分单元–页,按照页响应段请求。页的寻址需要建立页表,页表与 PCB 关联。
3. 多级页表与快表
3.1 问题
上述思路,已经趋于完善,但是在实际系统中还是存在问题:
- 为了提高内存空间利用率,页应当小,但是页小的话数量增加,据此建立的页表就会变大。
- 页太多了的话,页表太大 维护和查询页表的开销就大了:
- 比如32位程序(4G内存),如果页大小为4K,则有1M / 220个页。
- 这里的1M仅是页号,与之相应的页表项还有 页框号 和 保护位,每个页表项4个字节。页表整体就占用4M内存。
- 每个进程都需要同样的页表,如果有 100 个进程,则占用 400M 内存。
3.2 尝试1:去除无用表项
但实际上 每张页表可能并不需要 4M 这么大的内存。因为单个进程并不会把 4G 内存全用上,也就是说 1M 个页表项并不会全部派上用场。
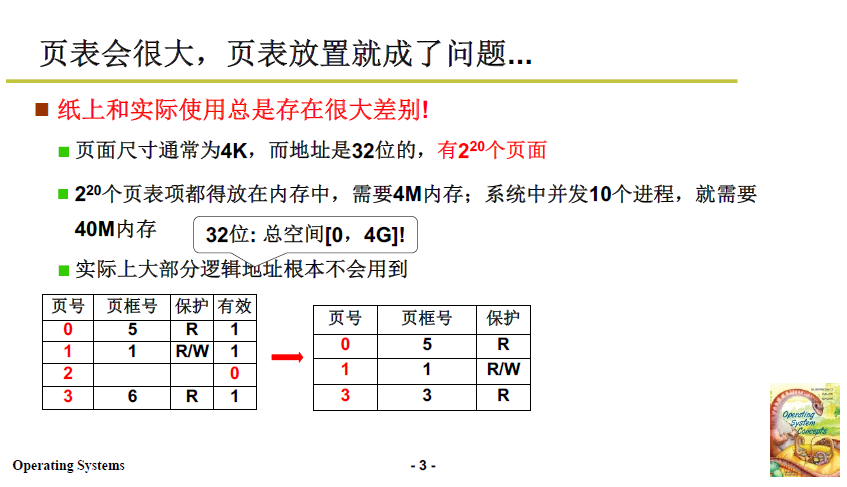

所以一种自然的想法就是:只对使用到的逻辑页建立页表项。
-
但随之而来的就是页号不连续,如下图右上角。
-
此前上文中本来用硬件索引,只需要对号入座,很快查到对应的表项,现在不连续了,就不能这么做了。
参见上面2.3.3 寻址方式,我们先拿到的是2240这样的地址,上文方法右移三位就可以拿到 2 这个页号,这样做的依据是,页是连续的,我们可以根据页的大小推算页的号码,而页不连续,就不能说2240在第2页,我们需要去查表匹配。
-
必须逐一比较、顺序查找 / 二分查找。
-
而内存访问本身就很慢,每一次访存都需要额外的查找操作(也是访存操作),会降低指令的访存效率。
所以不连续的算法复杂度高于上文提到的连续存放( O(1) ),但是连续存放的页表占用内存太大,会产生浪费。
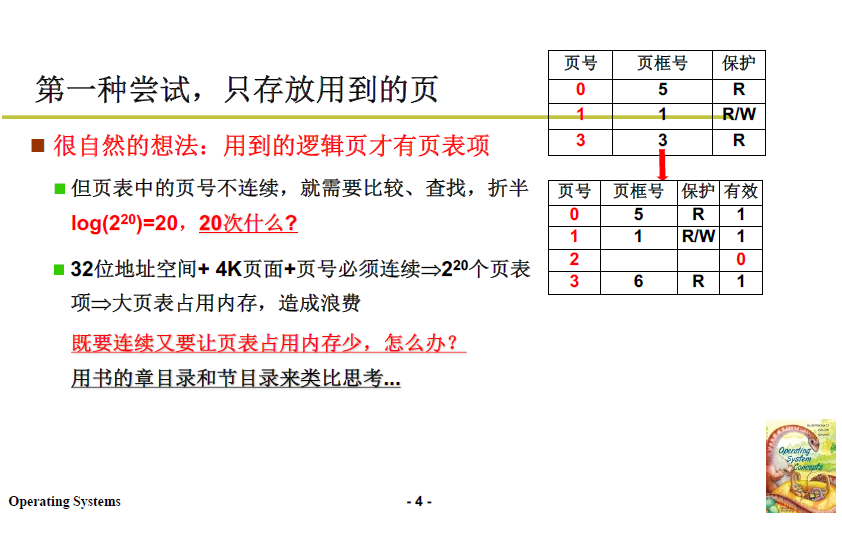

3.3 尝试2:多级页表
解决上述问题,可以参考生活中的书籍的章节目录,我们要查找第五章的第三节(在书中是第20节)就不必查找前四章的目录,直接跳到第五章的目录下继续向下查,大大节约了搜索开销。
在内存管理中,”不必查找” 对应的就是 这些区域 在该进程中不被使用,既减少了无用表项,也保证了大章连续,单节之间也连续。这个尝试是成功的。
具体细节如下图:
-
页目录号 10 位(相当于章),页号10位(相当于节),页内偏移 12 位 / 4k。
-
查找流程就是,找到对应章,在对应章下找对应节,对应节得到物理页框号和偏移量,得到最终真实物理地址。
由于多级页表的连续性,这其中的每一步查找都是O(1),可以直接索引得到。
-
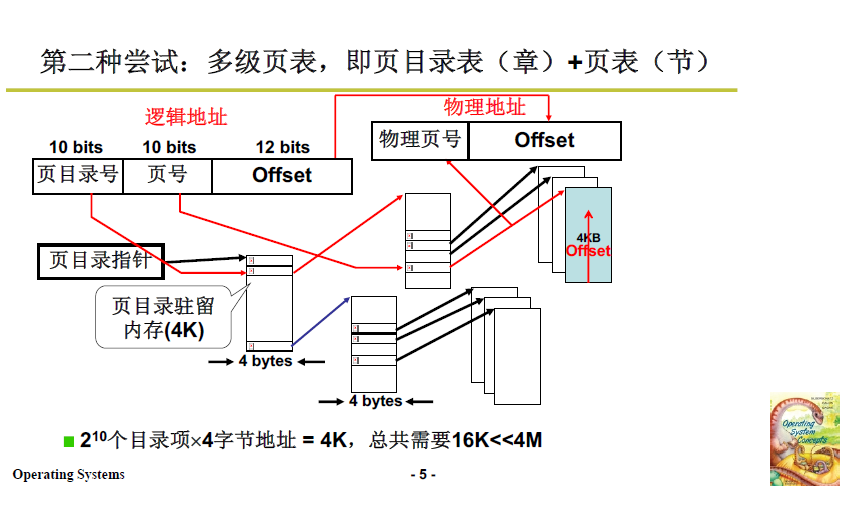
分析:
-
章有10位,也就是页目录号有210个表项,每个表项 4 字节,正好是 4k / 一页;
-
同理,节(页号/二级页)也有 210 个表项,每个表项 4 字节,也是 4k / 一页;
-
一个章/顶级页目录,管理 210个节/二级页,每个节(表项)是4K,所以 一章 管理 4M 空间,下图程序使用了 3 章就使用了 12M 内存。
-
注意:
-
下图程序随意的使用了内存中的三个部分,如果不采用多级页表,则需要将4G空间整体打表才能使用,此时页表的存储需要4M,而其中有许多内存不需要打表(因为不会被用到,下图空白处)。
-
而采用多级页表的页表项使用的空间是 210 个目录项 × 4字节地址 = 4K,总共需要16K远小于4M.
章 / 顶级页目录中,共有 3 个表项是有效的,分别指向3个节 / 二级页目录,所以顶级页目录+3个二级页目录共16K.
-
-
顶级页目录的前两个表项是在低地址空间,后一个表项是在高地址空间,对于这种不连续的逻辑地址的使用也是完美处理的;
也就是说,程序可以使用不连续的逻辑地址空间,但是多级页表仍然是连续的,查找的时间复杂度是O(1)的
-

3.4 多级页表的时空复杂度
多级页表增加了访存的次数。每多一级,内存空间的节省越多,但也会多访问一次内存。32位系统或许不太明显,64位系统可能是五、六级的页表,这时时间消耗就会很大,效率降低。
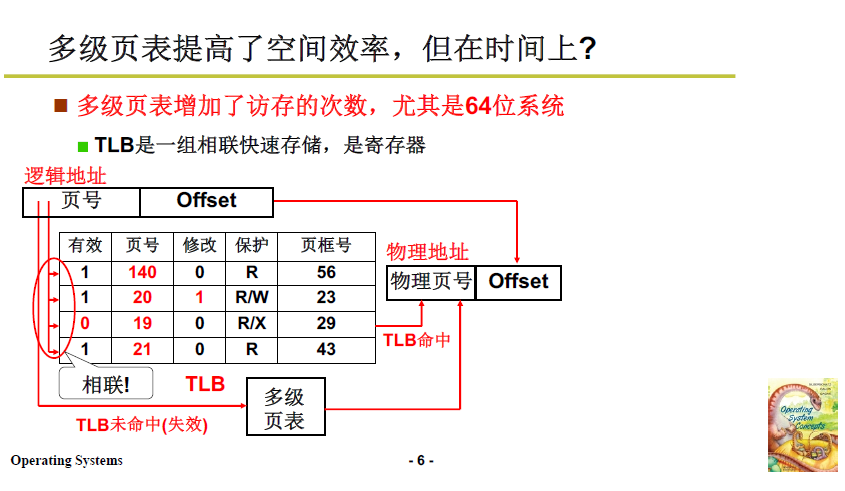
3.5 优化:快表
上述多级页表降低了空间复杂度,但时间复杂度依旧不理想,这里引入了 TLB,快表。
TLB 是一组相联快速存储(快表),是CPU内的寄存器;可以非常快的找到最近使用的逻辑页对应的物理页框号。
TLB: Translation Lookaside Buffer.直译可以翻译为旁路转换缓冲,常称之为快表。
这部分在计组的Cache有讲过,这里相当于是另一种角度来看这个问题。
工作过程:
-
TLB中存放从虚拟地址到物理地址的转换表;项由两部分组成:逻辑地址页号+偏移
-
CPU 需要访存时,优先在TLB中寻址,并且通过硬件组相联的设计,在硬件电路上进行比对,可以达到 近似 O(1) 的查找效果。

TLB能够降低时间开销的原因:
-
公式如下图所示,想办法增加TLB的命中率,就能使有效访存时间降低至近似访存1次;
简单讲就是减少了访问物理内存的次数。
-
下图公式是 TLB + 单级页表的计算公式。


页的个数通常很多,而TLB可以容纳的索引很少,TLB可以有效工作的原理是:
- 程序的地址访问存在局部性,
- 空间局部性:比如程序的循环、顺序结构使得被访问地址周边的地址也很快被访问;
- 时间局部性:有一些变量和语句经常被访问;
- 把这些经常被使用的放入TLB,并采用合适的替换策略,就能够保证TLB的命中率较高,降低访存时间。
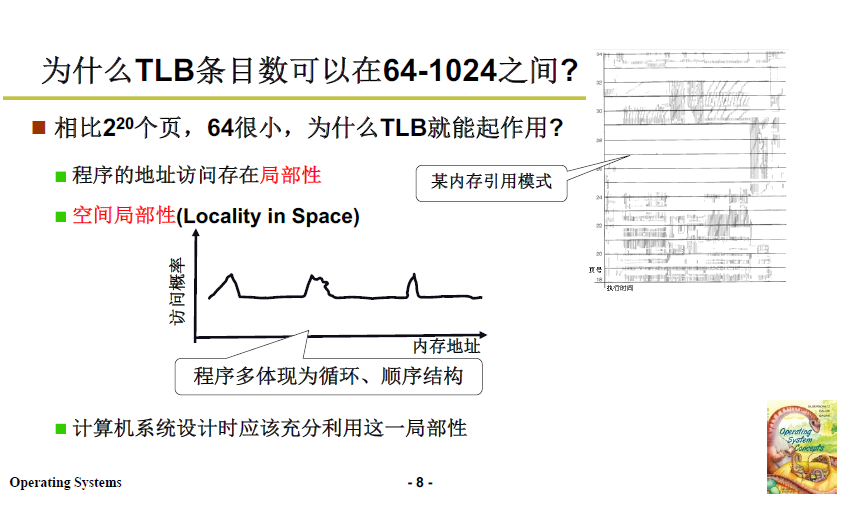

采用 TLB+多级页表 的方法,首先在TLB中寻址存,如果 TLB 未命中,则对多级页表寻址,这样就降低了访存的时空复杂度。
4. 段页结合的内存管理
4.1 虚拟内存
在真实的操作系统中,通常采用段页式存储管理,段面向用户,页面向硬件内存。这一部分就讲解一下第 1 部分的 段 和 第 2 部分的 页 如何结合在一起。
简单的想法是:
-
程序编译为段,段被装入内存分区(这里的内存并不是物理内存,因为前面论证过时空效率不高),依据段表寻址;
分段:代码分段+内存分区+段表,代码映射到程序员眼中的内存
-
而面向物理内存,划分为页,并根据页表/多级页表寻址;
分页:内存分页 + 多级页表
-
在前者和后者之间建立映射关系,即将程序员眼中的内存与物理内存建立映射,就完成了 段 和 页 的结合。
-
这里程序员眼中的内存 就是 虚拟内存。
4.2 段页结合的构成机理
一个很好的参考资料:关于逻辑地址、线性地址、虚拟地址、物理地址的理解
4.2.1 程序放入物理内存
首先是程序放入物理内存的过程。
- 如下图所示,程序的代码段在虚拟内存上按照 2.2 内存分区的方法,找到空闲区域并放入;
- 将虚拟内存上的地址映射到物理内存上。
- 举例:将左侧用户代码段再次打碎放入内存页中。
- 0x00345008 映射为 0x7008,再到物理内存取址;
- 这个映射对用户不可见/透明,所以用户眼中看到的就是下图左侧的虚拟内存。
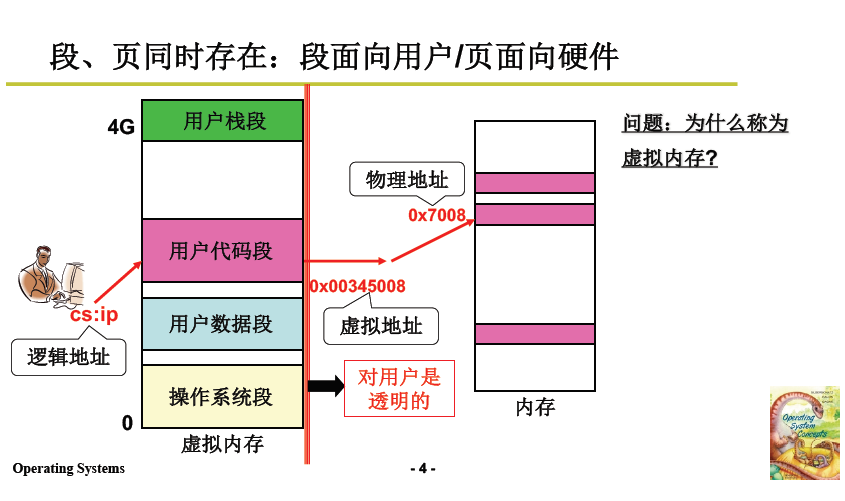

4.2.2 程序如何访存执行
这时的访存问题也就是 段页同时存在时的重定位 / 地址翻译。
- 首先要知道 程序段 在 虚拟内存 上的位置;
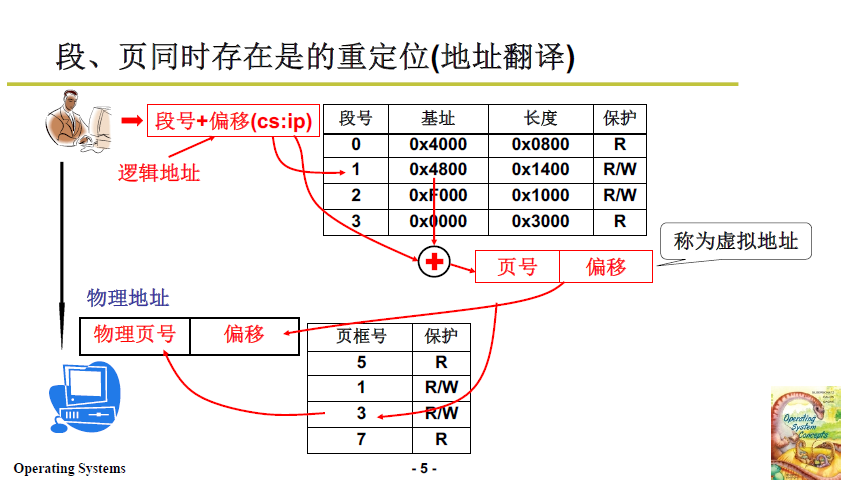
- 用户发出的逻辑地址:段号 + 段内偏移
- 基址:如下图在段表中,根据段号找到 基址 4800
- 虚拟地址:段内偏移+基址
- 虚拟地址向物理内存进行映射,考虑分页机制,再计算真实物理地址;
- 操作系统把真实物理地址发到地址总线,访存完成。
这样,从用户角度看,完全是段的概念,同一代码段是连续的。但从操作系统角度讲,这个段是虚拟的,需要再映射到物理地址上。从物理内存角度讲,虚拟内存的段被打散在不同页上,并且使用了多级页表,提高了时空效率。
几个疑问的解答:
前文第2部分提到过,内存分区会有越分越碎的问题,为什么这里还能用分区的思路来划分虚拟内存呢?
- 答:虚拟内存放在磁盘上,这样用户眼中就会有比实际大得多的内存空间。
引入虚拟内存的优越性,为什么不直接对段分页?
每个用户代码都有多个段,如果直接给段分页,进程的每一个段需要都维护一个页表;
经过虚拟内存的中介,只需要给虚拟内存维护一个页表;
优化碎片问题,进一步提高空间利用效率。
假设一个程序共有2047KB,分为两个段,1个段是1025KB,一个段是1022KB;
如果经过虚拟内存的中介,只需要放到两页上;如果直接给段分页,就要放到3页上

从用户角度看, 能够使用所有的虚拟地址空间。 从物理内存上看, 用户仅仅使用了一些内存页。
4.3 一个段页式内存管理实例
实验6. 下面开始看代码啦。
4.3.1 程序放入内存
- 为程序/进程分配内存:分配段、页,建立段、页表;进程可以带动内存;
- 进程有了自己的内存,程序放入内存:从进程 fork 中的内存分配开始说。

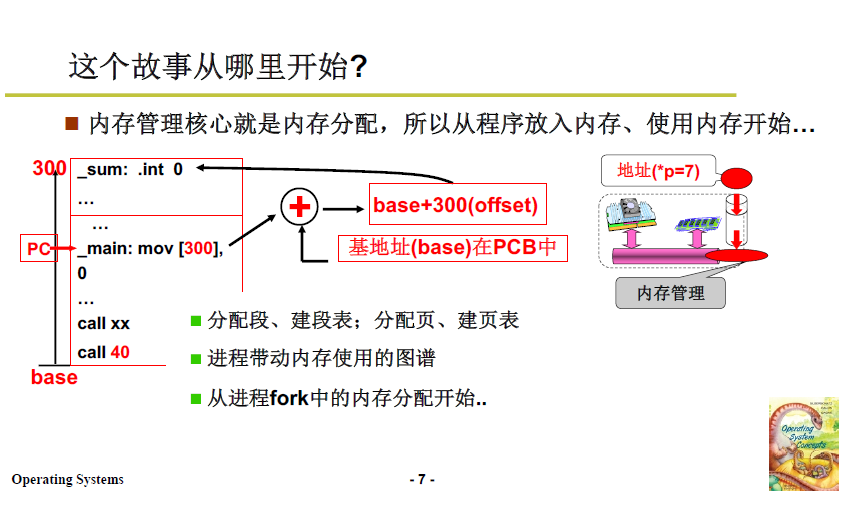
-
段页式内存下程序如何载入内存?
-
需要从虚拟内存中分出空闲区域,将程序段放入
-
对虚拟内存进行分区,使用 2.2.3 中的分区选择算法,对程序的各个段进行适配,建立段表;
-
——————-👆虚拟内存层,物理内存层👇——————
-
对虚拟内存占用的空间进行分页,分配物理内存的页,建立页表,同时程序也就载入了内存;
将用户数据段划分为3片,每一片关联物理内存的页框
-


4.3.2 程序使用内存
使用内存的核心是重定位,抑或是说 寻址。
以上图为例,需要执行 mov [300],0:
- 300是逻辑地址,查找段表,找到虚拟地址为 0x00045300;
- 再将虚拟地址重映射到物理地址,得到真实物理地址 0x0007300;
- 进行访存操作,如上图中,是将 0 放入 该位置。
4.3.3 简单总结 && 思路梳理
上面的思路大致是如下几步,代码实现也是这几个部分:
- 从虚拟内存中划分出空闲区域;
- 建立与段表的关联并修改;
- 物理内存中找空闲页;
- 建立与页表的关联并修改;
- 重定位寻址,即
*p = 7;
4.3.4 具体代码实现1 | fork=>copy_mem
首先 fork 需要实现上述思路的前 4 步。
- fork -> sys_fork -> copy_process 这个过程在学习笔记5的进程切换中已经了解过了;
- copy_process 中调用 copy_mem,将父进程的内存赋值子进程的内存;
copy_mem 做的事情:
-
nr 是进程的编号,p 是PCB;
-
new_data_base 就是每个进程在虚拟内存中的起始地址,每个进程占 64M 虚拟地址空间,互不重叠;
程序中的 0x400_0000 是 64 M ,乘以 nr 就得到了 第 nr 个进程的起始地址。
给 new_data_base 赋值就是在虚拟内存中分区;
这是子进程虚拟内存的起始地址。
-
set_base()就是在设置段表,在这里的实现中,数据段和代码段是同一个(没有像上文那样被划分成程序员熟悉的多段),这一步就是在建立段表; -
这里完成了第 1 步 和 第 2 步。


上面的划分方法,数据段和代码段都是同一个段,所以这种划分虚拟内存的方法比较弱智,但是它比较简单,适合初学者入门。
下一步就是要建立虚拟内存与物理内存的联系,分配页建立页表:
-
由于所有进程的虚拟地址互不重叠,所以所有进程可以共用一套页表;但是现在的操作系统,进程的虚拟地址是会重叠的,所以每个进程应该维护自己的页表;
Linux 0.11 中就是前者,没有切换页表,现代操作系统中就应当切换。如下面所讲的 fork 过程就各自维护各自的页表。


- copy_mem 调用 copy_page_tables,子进程和父进程共用物理内存的页,因此在fork子进程的过程中,没有新分配物理内存,只需要建立新的页表(拷贝旧页表)。

-
下面具体看看 copy_page_tables 建立新页表。
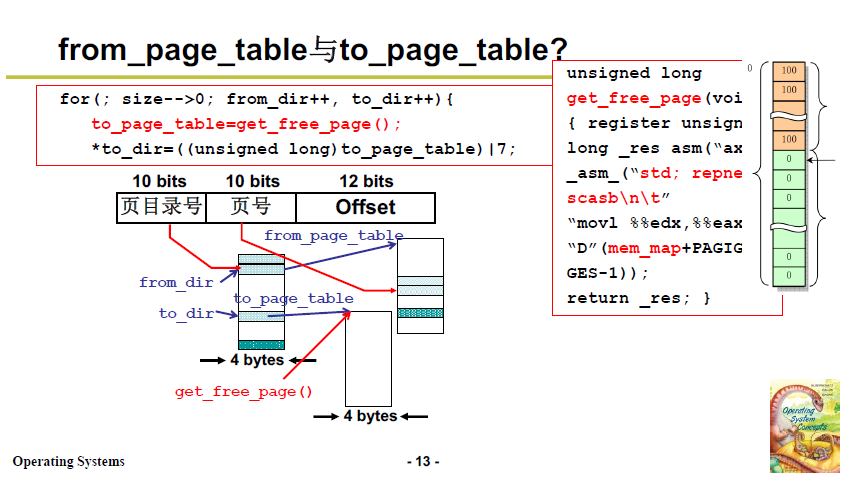
- 32位地址空间,实参 old_data_base 对应形参 from,表示父进程的虚拟内存的起始地址,from 右移20位,和 0xffc 进行位与结果赋给 from_dir(将后两位清为 0);
- 解释:根据虚拟地址结构,右移 22 位,就得到了页目录号,再乘以 4,得到顶级页目录中的索引位置(顶级页目录中的每一项占4字节),所以代码里直接写了右移 20 位再将后两位清 0,这是等价的;
- 现在就找到了 章。
- to_dir 来源同理,找到的子进程的 章。
- from_dir 是章,也就是指向父进程的第一个/节 / 二级页目录的 指针,*from_dir 就是父进程的第一个节 / 二级页目录;
- 同理,to_dir 是子进程的 章,指向子进程的第一个 节的指针;
- size 是 章 的个数。
- 代码见下图;
- 32位地址空间,实参 old_data_base 对应形参 from,表示父进程的虚拟内存的起始地址,from 右移20位,和 0xffc 进行位与结果赋给 from_dir(将后两位清为 0);


-
找到了父进程的章,也找到了子进程的章;接下来根据父进程章下的节建立子进程章下的节,先分配页,再循环复制页目录和页表。
-
循环 size 次,给子进程的节 / 二级目录分配页,每一章的二级目录就分配一页。
-
get_free_page()使用 内嵌汇编(如下图右上角) 从空闲列表中取出一页;这一步相当于分配二级页,上面4.3.3 中思路的第三步。
mem_map 在学习笔记1 中的OS开机过程中的 main.c 中初始化,空闲为0,占用为1,内嵌汇编 做的事情就是找到 mem_map数组的空闲位。
-
分配页后,按照父进程的每一个二级页目录,建立子进程的每一个二级页目录,这就是复制页表项的过程。
这一步相当于根据父进程页表建立页表,上述思路的第 4 步。
this_page = *from_page_table;再将*from_page_table赋值给了to_page_table,相当于拷贝父进程页表内容。由于此时父进程和子进程都指向了同一个物理页,需要将其设置为只读:
this_page = ~2;设置只读:如果一个进程读,另一个进程写,就混乱了。
mem_map[this_page]++,有点像引用计数的概念。
比如这里两个虚拟内存页共享一个物理内存页,数组值就是2。这意味着,其中一个进程释放内存时,不能直接减到0(而是1,减到0就意味着空闲了)。
-
-
这里用了写时复制 的方法。


子进程 一开始 页表 是 copy 父进程页表的,读的时候对应的物理内存都一样,这时读时共享。
直到父子进程有一个进程要用写操作修改物理内存,这时父子进程在物理内存层就不能保证完全一致,再为子进程相应的段分配物理空间。即写的时候要重新修改页表对应的映射 即 写时复制。


最后得到的内存图像如下图所示,进程1 fork 得到进程2,它们的虚拟内存指向了同一块物理内存空间,一页一页对应:


4.3.5 具体代码实现2 | 代码执行
段表、页表建立之后,就可以运行程序,进行第 5 步重定位 / 地址翻译了:
-
当用户程序访存时(读写内存时),查段表、页表进行地址翻译的工作由 MMU 完成;
-
读时共享,写时复制,子进程执行
*p=8,根据虚拟内存的映射会写到新的物理页里面, -
我的理解:子进程如果没有写操作,就可以以只读的方式共享父进程的内存页;如果有写操作,就会使用写时复制,产生子进程独立的内存页,并且需要修改页表


4.4 总结
整体思路其实还是很清晰的,但是代码实现我还不是很理解,特别是最后介绍到的写时复制概念,只是隐约感觉到,通过虚拟内存的一层映射,使得父子进程的逻辑地址的写入实现了分离。
整个段页结合的内存管理思路在 4.3.3 。

