单线程Redis性能为何如此之高?
- 2019 年 10 月 3 日
- 笔记
文章原创于公众号:程序猿周先森。本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号。

实际项目开发中现在无法逃避的一个问题就是缓存问题,而缓存问题也是面试必问知识点之一,如果面试官好一点可能会简单的问你二八定律或者热数据和冷数据,但是如果问的深入一点可能就会问到缓存更新、降级、预热、雪崩、穿透等问题,而这些问题可能会拦下大部分平时不怎么关注缓存的朋友,这些问题实际上都和缓存服务器息息相关,我们日常中经常使用的缓存服务器一般有两种:Redis和Memcached。本篇开始正式进入Redis系列文章,本篇主要讲讲Redis使用单线程为何速度还能如此之快?
既然谈到缓存服务器有两种,那我们为何要选择Redis呢?Redis与Memcached两者之间有何区别呢?
Redis 和 Memcached 的区别
-
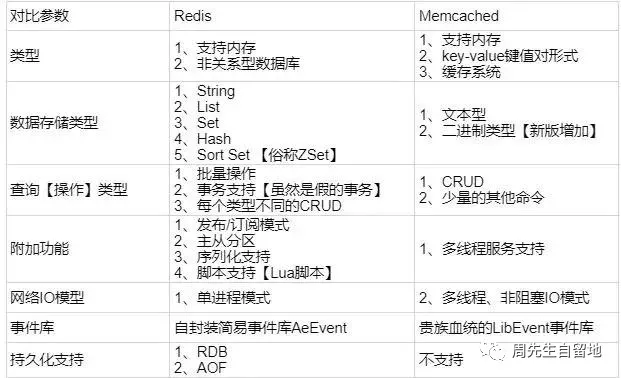
Redis支持常见数据类型:Redis 不仅仅支持简单的 key/value 类型的数据,同时还提供string(字符串)、list(链表)、set(集合)、zset(有序集合)和hash(哈希类型)等数据结构的存储。而Memcache 只支持简单的数据类型 String。
-
Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中。
-
集群模式:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 Cluster 模式的。
-
Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。
Redis是一个key-value存储系统。它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了主从同步。简单来说 Redis 就是一个数据库,不过与传统数据库不同的是 Redis 的数据是存在内存中的,所以存写速度非常快,因此 Redis 被广泛应用于缓存方向。Redis 也经常用来做分布式锁。Redis 提供了多种数据类型来支持不同的业务场景。除此之外,Redis 支持事务 、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。Redis中常用的数据类型实际上只有5种:String、Hash、List、Set、ZSet,我们可以先看下这五种基本数据类型的用法:
String
- 常用命令:set、get、decr、incr、mget 等。
String 数据结构是简单的 Key-Value 类型,Value 可以是string或者数字。常规 Key-Value 缓存应用;常规计数:博客数,阅读数等。
Hash
- 常用命令:hget、hset、hgetall 等。
Hash 特别适合用于存储对象。
List
- 常用命令:lpush、rpush、lpop、rpop、lrange 等。
链表是 Redis 最重要的数据结构之一,Redis List 为一个双向链表,支持反向查找和遍历,更方便操作,不过带来了额外的内存开销。
Set
- 常用命令:sadd、spop、smembers、sunion 等。
Set 其实和List都是列表的选项,Set 是可以自动去重的。当需要存储一个不出现重复数据的列表数据,Set 是一个最好的选择。你可以基于 Set 轻易实现交集、并集、差集的操作。
Sorted Set
- 常用命令:zadd、zrange、zrem、zcard 等。
Sorted Set 相比Set增加了一个权重参数 Score,使得集合中的元素能够按 Score 进行有序排列。
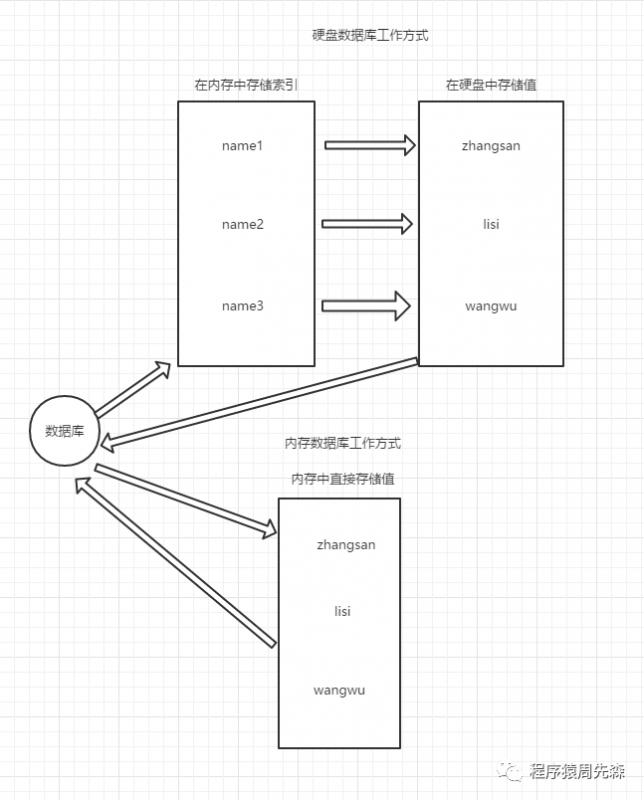
数据库工作模式如果按照存储方式进行划分可以分成两种:硬盘数据库和内存数据库。Redis读写数据之所以如此之快实际上就是由于Redis将数据存储在内存中,所以在读写数据时不会受到硬盘I/O速度限制,所以读写速度自然很快。而硬盘数据库则是在内存中储存一个索引,然后根据索引去硬盘中查询对应的值,所以效率肯定会相对更慢。
Redis基于内存采用单线程单进程模型的Key-Value数据库,经过官方测试每秒查询次数可以高达100000+,那为什么Redis如此快呢?最关键的一点其实刚才已经提到过,因为Redis完全基于内存,Redis接收到的大部分请求都是直接操作内存就可以完成的,所以处理请求非常迅速,而且Redis中使用单线程,避免了不必要的上下文切换和竞争锁机制,也不会出现频繁切换线程导致CPU消耗,不会存在多线程的死锁等一系列问题。在Redis中使用多路复用I/O模型,而不是非阻塞I/O,非阻塞I/O之前在Nginx提到过,所以我们不重复介绍,我们重点看看多路I/O复用模型。
多路I/O复用模型实际上是使用select、poll、epoll同时监听多个流的I/O事件,在无I/O事件时也就是空闲状态下会将线程阻塞,当有I/O事件需要处理时,线程就是从阻塞状态下唤醒,然后使用epoll轮询一遍所有发生I/O事件的流。多路复用实际上还就是说多个网络连接复用同一个线程,采用多路I/O复用技术可以让单个进程高效的处理多个连接请求,且Redis在内存中对数据进行操作,所以数据操作速度非常快,所以速度不会受到瓶颈,所以Redis才可以具有很高的吞吐量及性能。Redis的瓶颈主要来源于机器内存或网络带宽,CPU不是Redis的瓶颈所在,再加上单线程更易于实现,所以顺理成章Redis采用单线程的方式,但是使用单线程的方式是无法发挥多核CPU的优势的,比如在进行比较耗时的操作时会使得Redis并发量下降,因为单线程所以某一时刻只能处理一个操作,所以执行耗时操作会导致并发量的下降,有一个简单的解决方案就是在多核CPU下可以单机开多个Redis实例来解决这个问题。
欢迎关注公众号:程序猿周先森。
