论文阅读——LIFT: Learned Invariant Feature Transform
- 2020 年 11 月 29 日
- AI
一、概述
本文是一篇非常经典的基于深度学习的局部特征提取的论文,也是最早将特征检测和描述放在一起优化(即joint learning)的论文之一。此前对于局部特征描述的各个模块,包括兴趣点检测、方向估计和特征描述,均已有相应的基于CNN的方法提出,其中深度特征描述这一方向吸引了大部分关注,而兴趣点检测上的成果相对少一些。本文则认为之前对于单独模块的研究报道的高性能,在实际任务pipeline中可能并不能达到最佳。
局部特征描述任务(以SIFT和Harris等为代表)通常以完整图像为输入,首先提取出其中潜在的兴趣点,然后对兴趣点周围的邻域patch提取固定长度的特征作为其描述。要使用单个神经网络完成该流程,主要难点在于保持梯度流。比如要从检测模块输出的特征图提取出K个兴趣点,这一步通常需要NMS来辅助,而传统的NMS算法并不可微。本文为了完成该流程使用了一系列trick,其中很多trick在后续的patch-based文章中(如LF-Net等)均有沿用。从理解论文的角度来说,搞懂本文对于阅读后续一些流程更复杂的文章比较有帮助。
以下为原文摘要:
我们提出了一种新的深度神经网络结构,该结构实现了完整的特征点处理管道,即兴趣点检测,方向估计和特征描述。 尽管先前的工作已成功地单独解决了每个问题,但我们展示了如何在保持端到端的可区分性的同时以整体的方式完成各个模块的学习。 然后,我们证明了该深度学习的管线在许多基准数据集上无需重新训练,性能即可超过此前的SOTA方法。
二、方法
由于本文插图绘制地比较详细,这一部分就直接结合插图,以算法流程的形式记录LIFT中的主要内容。
首先,本文的CNN以patch为输入,而非全图。作者的解释是这样可以在不损失信息的情况下以更轻量级的方式解决该任务,因为全图中包含关键点的patch数量并不多。因此为了得到patch,作者首先需要对整个训练集通过某种方式提取出兴趣点位置。作者构建数据集的步骤大致如下:
-
选择multi-view的图像来构建训练数据
-
利用SIFT检测每张图像的兴趣点
-
将multi-view图像利用VisualSFM算法进行3D重建,剩下的兴趣点将作为本文算法的GT

以下为LIFT的完整预测流程。可见该流程基本是按照传统的局部特征提取算法设计的。

以下为LIFT的训练过程:




2.1 训练过程
-
LIFT网络在训练时需要输入一个四元对,即P1-4,其中P1和P2代表同一个3D点经不同视角投影得到的2D点对应patch;P3和P1为不同3D点投影的2D点对应patch;P4则为不包含兴趣点的patch。
-
对每个patch先使用检测模块进行预测。该模块较简单,直接用单层卷积+分段线性激活(来自TILDE论文)对原图提取特征并返回一个score map,记为
,其中\mu代表了检测模型的权重。
-
在对
进行训练时,不同于TILDE论文中使用sfm得到的关键点位置作为S的GT,本文认为S在除了sfm产生的兴趣点之外的位置也可以有maxima,这体现在检测模块的损失设计上。
- 本文早期实验发现,强行让检测模块将兴趣点预测为sfm模型得到的位置是有害的。(我的理解应该说的是直接用sfm模型得到的兴趣点生成GT score map,然后做强监督的方式)
-
对DET预测的score map提取关键点。本文提出可以使用softargmax代替nms,在保持可微的同时实现相似的功能。然后根据提取到的特征点x和原patch,送入STL(spatial transformer layer)进行crop,得到refine之后的小p(大写P代表原Patch),该过程记为
-
softargmax是一个用于计算物体质心的函数,其公式如下。softargmax在LF-Net中也有用到。

-
STN在这类任务中扮演着的角色,简单来说就是可微版本的OpenCV warpPerspective函数,通常都不是训练模块。
-
-
将p送入方向估计模块,预测出当前patch的方向θ。然后同4中的做法,利用spatial transformer crop将P进行crop,不同的是这次需要考虑在转换中加入方向信息。记为pθ=Rot(P,x,θ)
-
注意,送入第二个STL的patch是原始输入Patch,而非第一个STL crop的patch。说明第一个STL的patch唯一作用在于预测方向。
-
问题:对p估计出的方向θ,是p->pθ的方向还是pθ->p的方向?这里涉及对STN细节的理解。
-
-
将旋转之后的patch pθ送入特征描述网络,提取出固定维度的embedding d
-
根据输入四元组构建的patch之间的关系,计算检测、方向估计、特征描述三个部分的损失:
-
a. 检测模块:
- 第3步提到,检测模块如果使用sfm得到的GT score map做强监督可能是有害的。故作者利用P1和P2的关系,利用相同兴趣点的可靠性reliability,即最小化d1和d2之间的距离来训练检测模块。即下式:

- 此外,作者认为还需要对某个原本包含兴趣点的patch在预测中漏检的情况进行惩罚,体现在损失函数上为:
 image.png
image.png- 这里的softmax应该是对四个Patch中的每一个,即Pi,输出其包含兴趣点的概率,所以求softmax的维度应该是在??
-
b. 方向估计模块:
-
该模块的优化目标比较隐式,需要反映到下游的特征提取模块。因为方向估计的目的就是为了使同一个3D点在不同视角下的投影点的描述尽可能接近(描述子的可靠性,或者可重复性)

其中,

- 注意这个式子其实和检测模块的
基本一样,唯一的不同在于输入中的x是已经提取出来的兴趣点位置,因此这部分梯度不需要再从x传递到输入P,作者还是很严谨的
- 注意这个式子其实和检测模块的
-
-
c.特征描述模块:
-
本文的特征描述部分损失相对来说是很简单的了,因为patch之间的关系不需要在线构造,而是直接通过输入构造好的。直接给出损失函数的计算:

-
-






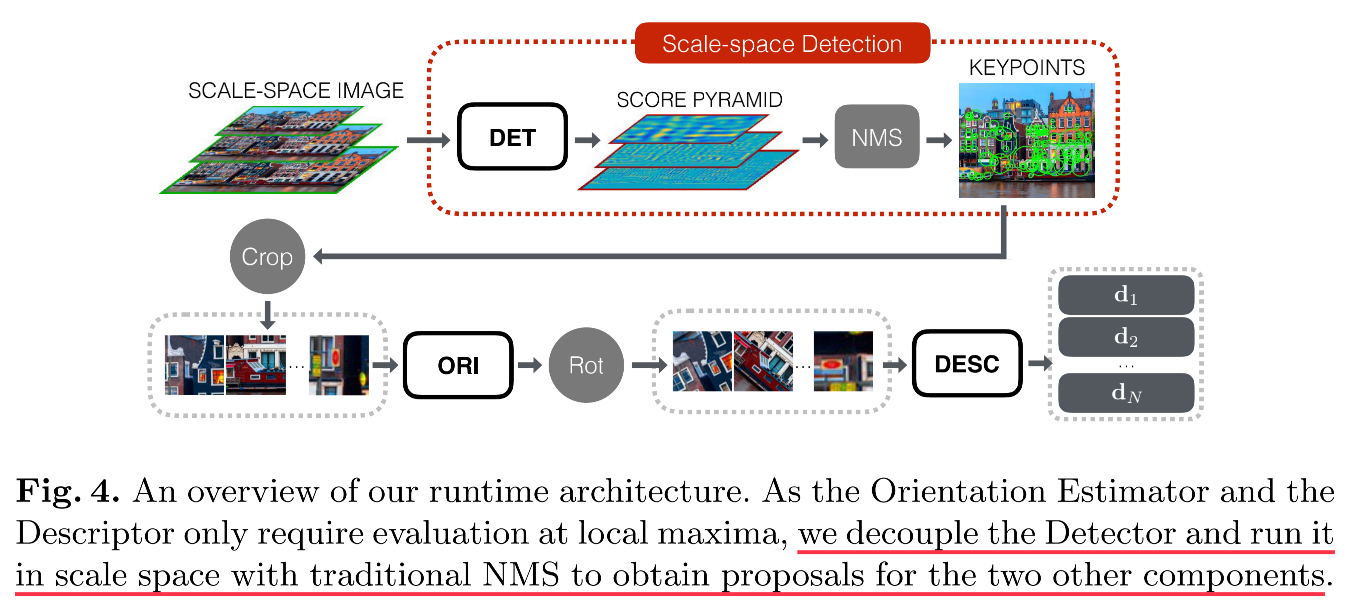
2.2 预测过程
LIFT的预测过程和训练稍有差异。由于方向估计和特征描述模块只需要在局部最大值处运行,作者认为可以在预测时将检测网络和后续两模块解耦:
- 构建原始大图输入的图像金字塔,利用DET预测出score map金字塔(scale space score map,这一概念在LFNet中进一步延伸),然后利用NMS直接估计出所有兴趣点坐标
- 再对各个兴趣点位置提取patch,分别进行方向估计和特征描述。
-

三、实验
-
结果示例(和SIFT对比,每行代表一个测试集)

-
另外,作者做了一个比较有意思的实验:将LIFT的各个模块分别替换成SIFT的组件,并比较在Strecha数据集上的评估指标:

这个实验说明,LIFT和SIFT的模块设计高度一致;将LIFT的任意一个模块替换为SIFT都会导致结果下降。




