Apache Hudi初学者指南
- 2020 年 11 月 27 日
- 笔记
在深入研究Hudi机制之前,让我们首先了解Hudi正在解决的问题。
客户在使用数据湖时通常会问一个问题:当源记录被更新时,如何更新数据湖?这是一个很难解决的问题,因为一旦你写了CSV或Parquet文件,唯一的选择就是重写它们,没有一种简单的机制可以打开这些文件,找到一条记录并用源代码中的最新值更新该记录,当数据湖中有多层数据集时,问题变得更加严重,数据集的输出将作为下次数据集计算的输入。
在数据库中用户只需发出一个更新记录命令就可以完成任务了,所以从数据库的思维模式来看很难理解上述限制,为什么不能在数据湖中完成?首先让我们来看看数据库是如何应用记录级更新的,这对于理解Hudi是如何工作的很有价值。
RDBMS的更新原理
RDBMS将数据存储在B-Tree存储模型中,数据存储在数据页中,数据页可以通过在表的列上创建的索引来找到。因此当发出更新命令时,RDBMS引擎会找到包含该记录的确切页面,并在该数据页面中适当地更新数据,这是一个简化的描述,在大多数现代RDBMS引擎中,在多版本并发控制等方面存在额外的复杂性,但基本思想保持不变。
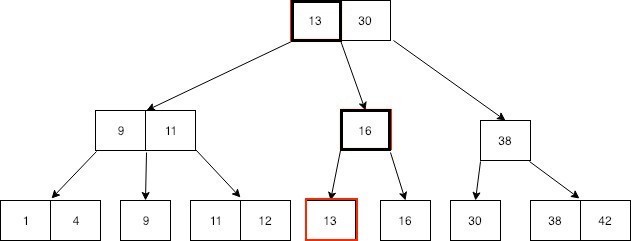
下图说明了如何通过B树索引找到带有值13的数据页,底层(第三层)是表示数据页的叶节点,顶层(第一层)和中间层(第二层)上的节点是索引值。
以下是一些非SQL数据库(如Cassandra)中的更新工作方式:
许多非SQL数据库将数据存储在LSM树的存储模型中,这是一个基于日志的存储模型,新数据(插入/更新/删除)被添加到append-only的日志中,然后定期将日志合并回数据文件,使数据文件与所有更改的数据保持最新,这种合并过程称为压缩,因此当更新一条记录时,只是将其写入到append-only日志中,根据数据库引擎的优化规则,将组合append-only日志和数据文件来为读取查询提供服务,这也是一个简化的描述,但基本思想相同。
下图说明了如何将新的和更新的数据添加到append-only日志(级别0)中,并最终合并到更大的文件中(级别1和级别2)。

现在我们已经基本了解了数据库如何处理记录级别的更新,接着看看Hudi如何工作,在Hudi(和类似的框架,如DeltaLake)出现之前,对datalake应用更新的唯一途径是重新计算并重写整个csv/parquet文件,如前所述,没有简单的机制来打开文件并更新其中的单个记录,造成这种限制有很多原因,其中一些主要原因是不知道哪个文件包含要更新的记录,也没有有效的方法来扫描一个文件来找到想要更新的记录,另外Parquet这样的列文件格式不能就地更新,只能重新创建。在数据湖中,通常还有多个被转换的数据层,其中一组文件被输入到下一组文件的计算中,因此在单记录更新期间编写逻辑来管理这种依赖关系几乎是不可能的。
HUDI
HUDI框架的基本思想是采用数据库更新机制的概念,并将其应用于datalake,这就是Hudi实现的目标,Hudi有两种“更新”机制:
- 写时拷贝(COW)-这类似于RDBMS B-Tree更新
- 读时合并(MOR)-这类似于No-SQL LSM-Tree更新
此外,HUDI还维护以下内容:
- 将数据记录映射到文件(类似于数据库索引)
- 跟踪到数据湖中的每个逻辑表的最近提交
- 能够基于“record_key”在文件中识别单个记录,这在所有Hudi数据集中是必需的,类似于数据库表中的主键
Hudi使用上述机制以及“precombine_key”机制来保证不会存在重复的记录。
- 标准数据文件大小(尽可能)
Copy on Write
在该模型中,当记录更新时,Hudi会找到包含更新数据的文件,然后使用更新值重写这些文件,包含其他记录的所有其他文件保持不变,因此更新的处理是快速有效的,读取查询通过读取最新的数据文件来查看最新的更新,此模型适用于读性能更为重要的读重负载,这种模型的缺点是突然的写操作会导致大量的文件被重写,从而导致大量的处理。
Merge on Read
在该模型中,当记录更新时,Hudi会将它附加到数据湖表的日志中,随着更多的写入操作进入,它们都会被附加到日志中,通过从日志和数据文件中读取数据并将结果合并在一起,或者根据用户定义的参数只从数据文件中读取数据来服务读取查询,如果用户希望实时查看数据,则从日志中读取数据;否则,如果指定为read optimized表,则从数据文件中读取数据,但数据可能已过时,Hudi会定期将日志合并到数据文件中,以使它们保持最新状态,这是配置为根据用例需求定期运行的压缩过程。
如果你的数据湖中有多层数据集,每一层都将其输出作为下一个计算的输入,那么只要所有这些数据集都是Hudi数据集,记录级更新可以很好地、自动地在多个处理层中传播,而不必重新编写整个数据集。
以上所有这些都是从记录更新的角度出发的,同样的Hudi概念也适用于插入和删除,对于删除有软删除和硬删除两个选项,使用软删除,Hudi保留记录键并删除记录数据,使用硬删除,Hudi会为整个记录写空白值,丢弃记录键和记录数据。


