webmagic源码浅析
webmagic简介
webmagic可以说是中国传播度最广的Java爬虫框架,//github.com/code4craft/webmagic,阅读相关源码,获益良多。阅读作者博客【代码工匠】,能够领略到一个IT工作者的工匠精神,希望以后成为他这样的开源贡献者。Webmagic的文档也是写得非常漂亮,这里就不具体讲它的使用方法了,见官方文档
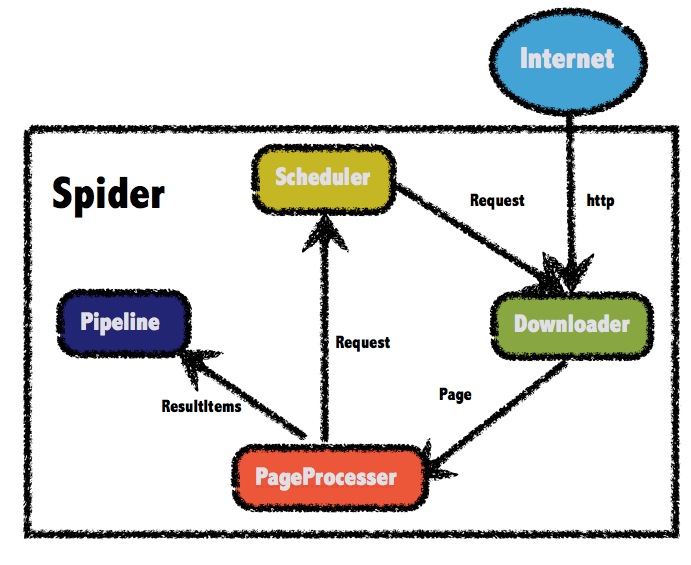
webmagic核心架构
webmagic帮我们做了几个核心的事情:
1.线程池封装,不用手动控制采集线程
2.url调度,实现了生产者消费者模型
3.封装下载器组件(downloader),解析组件,持久化。 见官方文档
4.支持注解
简单案例
借用一段官方案例,快速入门,便于后面的理解。开启一个爬虫,只需要简单几步,编写页面解析器,写具体的解析方法。新建Spider实例,添加至少一个种子URL,设置其他可选属性,最后调用run()方法,或者start(),start()方法内部会为spider单独开启一个线程,使得爬虫与主线程异步。
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class GithubRepoPageProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
@Override
public void process(Page page) {
//将提取的url加入page对象暂存,最终会加入到
page.addTargetRequests(page.getHtml().links().regex("(//github\\.com/\\w+/\\w+)").all());
page.putField("author", page.getUrl().regex("//github\\.com/(\\w+)/.*").toString());
page.putField("name", page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()").toString());
if (page.getResultItems().get("name")==null){
//skip this page
page.setSkip(true);
}
page.putField("readme", page.getHtml().xpath("//div[@id='readme']/tidyText()"));
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
//官方链式调用,拆解到下面方便理解
//Spider.create(new GithubRepoPageProcessor()).addUrl("//github.com/code4craft").thread(5).run();
//创建线程
Spider spider = Spider.create(new GithubRepoPageProcessor());
//添加采集种子URL
spider.addUrl("//github.com/code4craft");
//设置线程数
spider.thread(5);
//启动爬虫//run()方法既可以看作多线程中的Runnable接口方法,也可以直接运行,是爬虫的核心方法
spider.run();
}
}
Spider类属性
爬虫的核心是us.codecraft.webmagic.Spider类,看看Spider类中都有哪些重要属性
属性列表:
public class Spider implements Runnable, Task {
//下载器对象
protected Downloader downloader;
//持久化统一处理器,可以有多个
protected List<Pipeline> pipelines = new ArrayList<Pipeline>();
//页面解析器
protected PageProcessor pageProcessor;
//种子请求(这个地方看着种子请求也不是很对,因为spider对象在没开始运行时,仍然可以使用addRequest,addUrl添加url )
protected List<Request> startRequests;
//浏览器信息对象
protected Site site;
//爬虫任务标识
protected String uuid;
//任务调度器,默认是JDK中的LinkedBlockingQueue的实现
protected Scheduler scheduler = new QueueScheduler();
protected Logger logger = LoggerFactory.getLogger(getClass());
//线程池(自己封装的一个模型,内部的execute方法实际是executorService的execute实现添加线程的作用)
protected CountableThreadPool threadPool;
//执行管理器对象(和线程池配合使用)
protected ExecutorService executorService;
//线程数,控制采集并发
protected int threadNum = 1;
//爬虫任务运行状态
protected AtomicInteger stat = new AtomicInteger(STAT_INIT);
//是否采集完成退出
protected boolean exitWhenComplete = true;
protected final static int STAT_INIT = 0;
protected final static int STAT_RUNNING = 1;
protected final static int STAT_STOPPED = 2;
//是否回流url,spawn产卵的意思。个人觉得这个参数很多余,不想采集继续下去,可以别把url加入队列
protected boolean spawnUrl = true;
//退出时是否回收处理
protected boolean destroyWhenExit = true;
//控制新生成url锁
private ReentrantLock newUrlLock = new ReentrantLock();
//控制新生成url锁,配合newUrlLock 使用
private Condition newUrlCondition = newUrlLock.newCondition();
//监听器集合,请求爬去成功或者失败时,可以通过注入监听器分别实现onSuccess和onError方法
private List<SpiderListener> spiderListeners;
//采集页面数统计(只代表请求的次数,不代表成功抓取数)
private final AtomicLong pageCount = new AtomicLong(0);
//爬取开始时间
private Date startTime;
//调度器队列中的URL已经被消费光,且采集线程未执行完成,仍然可能生产URL到调度器队列中时,线程最多wait 30秒
private int emptySleepTime = 30000;
threadNum 这里Spider本身实现了Runnable接口,可以作为一个独立的线程开启,当然它的线程控制不仅于此,这里有一个属性threadNum才是控制采集线程数的,后面再细说。
scheduler 对象做为调度器,内部采用队列维护了一个实现生产者消费者模型,爬取的过程中,可以将采集的url提取到scheduler的队列中,线程会持续不断的消费scheduler 的队列中消费。
pageProcessor 用于用户自定义页面解析规则,定义具体的解析逻辑,新建Spider实例的方式仅两种,public static Spider create(PageProcessor pageProcessor)和构造方法public Spider(PageProcessor pageProcessor) create方法内部只是调用了一下构造方法。构造一个spider对象都需要一个自定义的解析器,不同页面,解析逻辑不相同,PageProcessor接口中。spider会调用PageProcessor的process方法,这是一个策略设计模式。
uuid 这个名字可能让人误会,和平时uuid不是一个含义,这个属性是一个爬虫进程的唯一标识
其他属性 比较重要的属性还包括threadPool,executorService,控制多线程并发,浏览器对象site,对于有些反爬策略的网站,该对象可以用于模拟浏览器,达到反反爬虫的作用。
Spider核心方法run()
@Override
public void run() {
checkRunningStat();//检查爬虫运行状态,防止run方法被调用多次
initComponent();//初始化
logger.info("Spider {} started!",getUUID());
while (!Thread.currentThread().isInterrupted() && stat.get() == STAT_RUNNING) {
//循环消费Request,url在放入scheduler时,已经封装为Request对象了
final Request request = scheduler.poll(this);
if (request == null) {
if (threadPool.getThreadAlive() == 0 && exitWhenComplete) {
//threadPool.getThreadAlive()线程池中仍然还有存活线程,那么存活线程可能会生产出新的url来
//exitWhenComplete默认为true,
//exitWhenComplete如果为false,线程等待新URL,
//如果队列(自定义队列)能实现动态添加url,那就可以实现动态添加采集任务的功能
break;
}
// wait until new url added
//等待存活的线程生产新的url
waitNewUrl();
} else {
//将request封装为线程,加入线程队列,线程池会根据设置的并行参数threadNum,并行执行
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
processRequest(request);//执行请求
onSuccess(request);//调用执行成功的方法
} catch (Exception e) {
onError(request);
logger.error("process request " + request + " error", e);
} finally {
pageCount.incrementAndGet();
signalNewUrl();
}
}
});
}
}
stat.set(STAT_STOPPED);
// release some resources
if (destroyWhenExit) {
close();
}
logger.info("Spider {} closed! {} pages downloaded.", getUUID(), pageCount.get());
}
核心方法的流程还是比较简答的,checkRunningStat()会先检查一下爬虫是否已经启动,这有点儿像多线程中的开启线程的start()方法,两次开启是不允许的。
然后初始化方法initComponent()各种组件,在initComponent()方法中,加入startRequests中的Request,实际上在Spider启动之前可以调用addUrl(String... urls)和addRequest(Request... requests)方法直接将请求加入到队列中,startRequests和后面那种添加url的方法缺少了一定的一致性。
后面一个循环消费的过程,正如我注释里写的那样,如果队列中url被消费完毕,且没有正在被消费的存活的线程了,且完成采集退出属性exitWhenComplete为true(exitWhenComplete默认为true,设置为false则进程将会一直挂起),就会跳出死循环,采集结束,反之,如果依然有线程存活,或者exitWhenComplete为false,那么线程waitNewUrl()等待,在exitWhenComplete为false的情况,进程就不会自动停止了,除非强杀了,这种设计在分布式的模式下才显得有意义,可以动态添加url到队列中去。
private void waitNewUrl() {
newUrlLock.lock();
try {
// double check
if (threadPool.getThreadAlive() == 0 && exitWhenComplete) {
return;
}
//默认是30秒后自动苏醒,可以通过设置emptySleepTime属性,控制自动苏醒的时间
newUrlCondition.await(emptySleepTime, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
logger.warn("waitNewUrl - interrupted, error {}", e);
} finally {
newUrlLock.unlock();
}
}
后面使用threadPool执行一个新的子线程。new Runnable构造的匿名内部类会通过threadPool开启一个新的子线程,执行请求processRequest(request),执行成功就调用onSuccess(request),失败就调用onError(request),接着finally代码块中的内容是非常重要的,统计请求的页面次数(无论失败或者成功),signalNewUrl()唤醒等待的线程,这里要和前面waitNewUrl()结合起来看,两者使用同一个锁,waitNewUrl()作为父线程,默认会自动苏醒,但调用signalNewUrl()的用意在于,可能这个子线程已经又生成新的URL放到队列中了,就不用再等30秒了。
private void signalNewUrl() {
try {
newUrlLock.lock();
newUrlCondition.signalAll();
} finally {
newUrlLock.unlock();
}
}
后面的代码则是爬虫结束的操作,这种情况只有前文提到的跳出死循环,采集结束,结束前设置了一下状态,做了一下close()操作
调度器Scheduler
调度器在webmagic中扮演的角色是非常重要的,说来功能也不算太复杂,实现生产者-消费者模式,顺便去重。scheduler默认为QueueScheduler ,在scheduler声明的时候就直接新建了这个实例
public class QueueScheduler extends DuplicateRemovedScheduler implements MonitorableScheduler {
//LinkedBlockingQueue队列存url
private BlockingQueue<Request> queue = new LinkedBlockingQueue<Request>();
@Override 覆盖父类DuplicateRemovedScheduler 的方法
public void pushWhenNoDuplicate(Request request, Task task) {
queue.add(request);
}
@Override 实现DuplicateRemovedScheduler 不完全实现Scheduler的poll方法
public Request poll(Task task) {
return queue.poll();
}
@Override //实现MonitorableScheduler 的方法
public int getLeftRequestsCount(Task task) {
return queue.size();
}
@Override //实现MonitorableScheduler 的方法
public int getTotalRequestsCount(Task task) {
return getDuplicateRemover().getTotalRequestsCount(task);
}
}
以上代码,可以看到QueueScheduler的构成,QueueScheduler继承了抽象类DuplicateRemovedScheduler 实现了接口MonitorableScheduler 接口,DuplicateRemovedScheduler 又实现了Scheduler,DuplicateRemovedScheduler 为抽象类,仅仅实现了push逻辑(生产者),而poll是QueueScheduler自己实现的(消费者)。push()方法使用去重器,判断该请求有没有被采集过。这里要注意,默认Post请求是不去重的,能直接打开的请求都是get的😁,官方文档也有特别说明
//DuplicateRemovedScheduler 源码
private DuplicateRemover duplicatedRemover = new HashSetDuplicateRemover();
@Override
public void push(Request request, Task task) {
logger.trace("get a candidate url {}", request.getUrl());
//duplicatedRemover.isDuplicate(request, task) 检查是否采集过
if (shouldReserved(request) || noNeedToRemoveDuplicate(request) || !duplicatedRemover.isDuplicate(request, task)) {
logger.debug("push to queue {}", request.getUrl());
pushWhenNoDuplicate(request, task);
}
}
//是否需要去重,POST请求则不需要去重
protected boolean noNeedToRemoveDuplicate(Request request) {
return HttpConstant.Method.POST.equalsIgnoreCase(request.getMethod());
}
public class HashSetDuplicateRemover implements DuplicateRemover {
private Set<String> urls = Collections.newSetFromMap(new ConcurrentHashMap<String, Boolean>());
@Override
public boolean isDuplicate(Request request, Task task) {
//add成功,说明没有添加过这条请求,返回true
return !urls.add(getUrl(request));
}
protected String getUrl(Request request) {
return request.getUrl();
}
@Override
public void resetDuplicateCheck(Task task) {
urls.clear();
}
@Override
public int getTotalRequestsCount(Task task) {
return urls.size();
}
}


