
手把手教你爬取优酷电影信息-2
- 2021 年 2 月 26 日
- 筆記
上一章节中我们实现了对优酷单页面的爬取,简单进行回顾一下,使用HtmlAgilityPack库,对爬虫的爬取一共分为三步 …
Continue Reading上一章节中我们实现了对优酷单页面的爬取,简单进行回顾一下,使用HtmlAgilityPack库,对爬虫的爬取一共分为三步 …
Continue Reading
前言 上一篇文章讲了爬虫的概念,本篇文章主要来讲述一下如何来解析爬虫请求的网页内容。 一个简单的爬虫程序主要分为两个部分 …
Continue Reading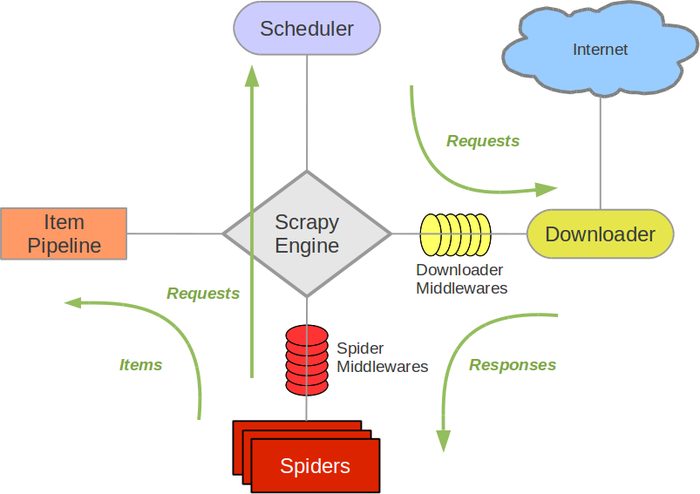
架构及简介 Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。 Sc …
Continue Reading使用时先安装 lxml 包 开始使用 和beautifulsoup类似,首先我们需要得到一个文档树 把文本转换成一个文档 …
Continue Reading目录 开始使用呢 解析器 四种对象 tag对象 标签名(name) 属性值(Attributes) 多值属性 内容 Co …
Continue Reading
上一篇(//www.cnblogs.com/meowv/p/12971041.html)使用HtmlAgilityPac …
Continue Reading
上一篇(//www.cnblogs.com/meowv/p/12966092.html)文章使用AutoMapper来处 …
Continue Reading