
Spark的两种核心Shuffle详解
- 2021 年 8 月 16 日
- 筆記
在 MapReduce 框架中, Shuffle 阶段是连接 Map 与 Reduce 之间的桥梁, Map 阶段通过 …
Continue Reading在 MapReduce 框架中, Shuffle 阶段是连接 Map 与 Reduce 之间的桥梁, Map 阶段通过 …
Continue Reading
Spark概述 Spark定义 spark是一种基于内存的快速、通用、可扩展S的大数据分析计算引擎 Spark Core …
Continue Reading
摘要:CarbonData 在 Apache Spark 和存储系统之间起到中介服务的作用,为 Spark 提供的4个重 …
Continue Reading
1.概述 离线数据处理生态系统包含许多关键任务,最大限度的提高数据管道基础设施的稳定性和效率是至关重要的。这边博客将分享 …
Continue Reading
数据处理的过程 数据处理的过程一般如下: 数据质量管理(DATA Quality Managenment)是指对上述过程 …
Continue Reading经常有同学问我,基于Hadoop生态圈的大数据组件有很多,怎么学的过来呢,毕竟精力有限,我们需要有侧重点,我觉得下面这几 …
Continue Reading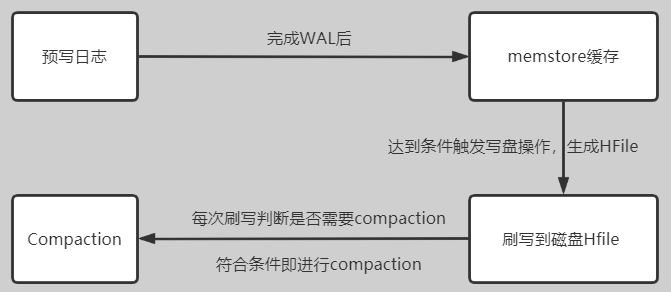
1. Hbase读写优化 写: 批量写、异步批量提交、多线程并发写、使用BulkLoad写入、表优化(压缩算法、预分区、 …
Continue Reading
一、Flink概述 1、基础简介 Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink …
Continue Reading
一、Spark概述 1、Spark简介 Spark是专为大规模数据处理而设计的,基于内存快速通用,可扩展的集群计算引擎, …
Continue Reading
前言 当我在测试SparkStreaming的状态操作mapWithState算子时,当我们设置timeout(3s)的 …
Continue Reading