#编译原理# 词法分析(三)第二部分
- 2019 年 10 月 6 日
- 筆記
词法分析
编译原理笔记第三部分,由于内容过长所以分为了两部分,跳转链接在总阅读目录处,内容参考:北航软院教师邵兵课堂课件及内容、张莉著《编译原理及编译程序构造》、国防工业出版社的《编译原理——学习指导与典型题解析》、AlvinZH的学习笔记以及个人理解
目前是包含了全部内容的版本,后续会推出精简版和复习知识点版
如有建议或错误错误欢迎在评论中指出或联系我:QQ:847590417
总阅读目录
3.1 词法分析程序的功能及实现方案
3.2 单词的种类及词法分析程序的输出形式
3.3 正则文法及状态图
3.4 正则表达式与有穷自动机FA
第二部分:
本章总内容
重点:词法分析介绍、词法分析单词种类划分、正则文法、状态图、正则表达式、自动机、自动机的转化、表达式文法和自动机的转化、词法分析程序的设计实现,词法分析程序自动生成器LEX。
之前的内容
词法分析介绍、词法分析单词种类划分、正则文法、状态图、正则表达式、自动机、自动机的转化会在第三章的第一部分进行介绍。
3.5 有穷自动机、正则文法、正则表达式的转化
转化流程图:

以下转换的顺序是按图上箭头的顺序进行排序的(NFA包含DFA,所以和NFA的转化可能称之为DFA的转化)。
0.正则文法G转状态图
绘制左线性文法的状态图(状态图只能用于左线性文法,这是和后面的DFA的明显区别)状态图的绘制没有严格规定(右线性的暂时不做考虑)
1.文法的非终结符号是一个个的结点
2.设一开始状态S(句子)
3.对规则Q::=t(t为终结符),需要一条从S到Q的一条弧,弧上标记为t
4.对Q::=Rt,画一条从R到Q的弧,弧上标记为t
(倒,谁规约于谁,谁指向谁)
5.根据自动机方法,可加上开始状态和终止状态标志,识别符号作终止状态,用双圆圈标识
1.DFA M转正则文法 G
规则:
1.对(A,t) = B,写成:A→tB(只推右线性,左线性在推导时可能递归)
2.对每个可接受状态Z(终止状态),增加产生式Z→ε
3.有穷自动机的初态对应文法开始符号,有穷自动机的字母表为文法的终结符号集
例:

2.正则文法 G转DFA M
规则:(和状态图的转化类似)
1.字母表(弧上的所有符号组成的表)和G的终结符号相同
2.为G中的每个非终结符生成M的一个状态,G大的开始符号S是开始状态S
3.增加一个新状态Z,作为NFA的终态
4.对G中的形如A→tB,其中t为终结符或空字符,A和B为非终结符号的产生式,构造M的一个转换函数(A,t)=B
4.对G中形如A→t的产生式,构造M的一个转换函数(A,t)=Z
例:

3.正则表达式转DFA M
他们是等价的
定理:在Σ上的一个字集V,V是Σ*的子集,是正则集合,当且仅当存在一个DFA M使V=L(M).
规则:
一个正则表达式,构建时从左到右拆解分析即可
a. 对空集φ不作处理
b. 对正则式ε,由x射出符号为空符号的弧到y
c. 对字母表中存在的字母符号如正则式a,由x射出符号为该字符的弧到y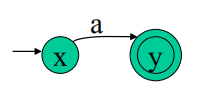
(x,y为状态,只是构建的临时初态终态,符号即是正则表达式中读取到的字符(从左到右分解))
多个正则式,例如s,t,他们的NFA为Ns和Nt
a. R=s|t
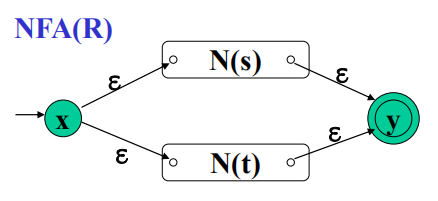
b. R=st

c. R=s*
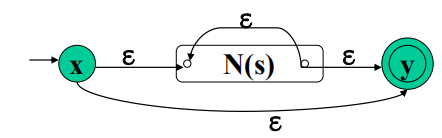
d. R=(s),和R=S的NFA一样
例:

1.从里开始构建NFA



2.从外开始构建

4.DFA M转正则表达式
规则:
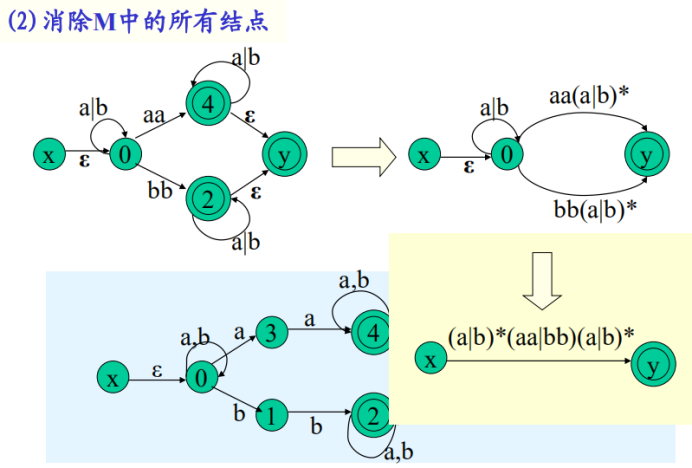
(1)在M上加两个结点x,y。从x用空符号弧连接到M的所有初态节点,从M的所有终态节点用空符号弧连接到y,形成和M等价的的M’,此时只有一个初态一个终态。
(2)消除M’中的其他节点(除了x,y)
1.邻合并

2.并变或

3.递归加边加星号

即正则表达式转NFA倒过来
例:
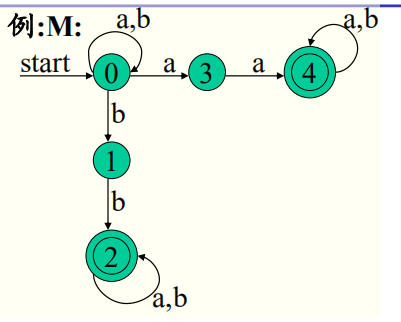

5.正则文法 G转正则表达式
三个规则,可将正则文法转换为一个只剩一个开始符号的产生式,并且右侧不含非终结符,仅含对应的表达式。转换后的产生式应用扩充的BNF表示,而在标识符好的0~n次重复时应该用*代替
(1)代入规则:对A→xB,B→y转化为A→xy
(2)消除递归规则:对A→xA|y转化为A→x*y
(3)BNF规则:对A→x,A→y转化为A→x|y
注:左线性的话,对A→Ax|y转化为A→yx*
例如:

例:

6.正则表达式转正则文法 G
规则如下:
(1)对任何正则表达式r,选择一个非终结符S作为识别符号,并产生产生式S→r
(2)若x,y是正则表达式:
1.对A→xy,转化为A→xB,B→y,B为新的非终结符
2.对A→x*y,转化为A→xA,A→y(注:对A→x*y,则需要转化为A→xA,A→ε)
3.对A→x|y的产生式
例如:
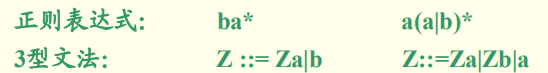
例:

左线性的话:(会死循环)

3.6 词法分析程序的设计与实现
3.6.1 词法分析原理
说明:
1.对于注释符号是不输出的
2.各单词之间用空白符号(空格、制表、回车)分开
在得知文法后
需要根据文法将所有终结符号的转化过程给绘制出来(初始符号就是每个终结符号)

这里出现的其他字符,实际是任意字符,例如读到+后再读入+,后一个+相对于前一个也是其他字符。
然后将这些转化过程都结合起来,初始状态当做传入的符号串。合并后还需要注意:对重复符号进行特殊处理(单双字符分界符处理合并),还需要一个出错的状态(符号串不属于任一流程)。

3.6.2 词法分析程序的构造
不同状态的做法
开始状态:利用程序依次读入字符,读到空字符就跳过,然后对每一个非空字符串转到程序中进行处理。
标识符状态:在组合成标识符后,判断是保留字还是用户自定义的
整数状态:组成数字后还要做数字字符到二进制数值的转换
单字符分界符状态:判断对应的类别编码即可
冒号状态:需要和下一个字符结合进行判断,是单字符还是双字符
斜竖状态:同样需要判断后面的字符,作为字符还是跳过注释
错误状态:打印错误信息并跳过
注:在词法分析时为了判别是否已经读到了单词的右端符号,有时候需要向前多读一个字符,例如在标识符和无符号整数等状态。这是为了防止跳过某个不该跳过的字符。所以在返回调用程序前应该将读字符指针后退一个字符。(字符指针后退实际就是退到前一个字符,因为在读取字符时可能多读一个字符,导致后面读取时这个字符就被忽略了,所以需要后退(字符指针是一直前进的,后退就是向上一个读的字符吐出来一个))
3.6.3 词法分析程序的实现
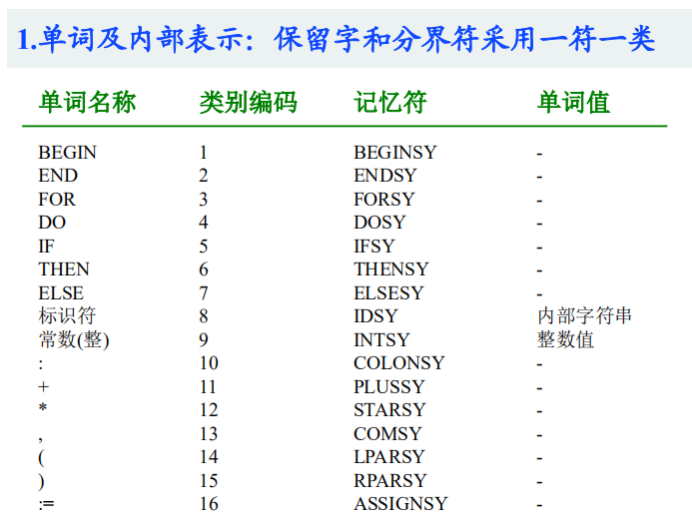
一个词法分析程序需要:1.单词及内部表示 2.词法分析程序需要引用的公共(全局)变量和过程 3.词法分析程序算法
1.输出形式:即按单词及内部表示的规定进行(一般是二元式,一个是类别编码,一个是对应的单词值)
2.全局变量和过程(即一个词法分析程序需要引用的变量和过程,一般提前定义好需要使用的,需要用时调用即可)
3.词法分析程序算法
其实算法程序的具体结构还是由开发者决定的,例如是否进行字符流的回退,如何进行类型的判断等等,都是由具体的实现进行决定的。
将之前的完整状态图构造为算法即可
伪代码:


当词法分析程序作为子程序时,一般由语法分析程序调用,当词法分析程序组合出一个单词时就返回给语法分析语句,并且返回时应将单词的类别码送入变量单元symbol。(语法分析程序中会设有变量class,用于存放单词的类别码)
3.7 词法分析程序的自动生成器LEX
3.7.1 LEX基础说明
功能:输入LEX源程序便可经过LEX后生成词法分析程序L
然后输入S.P.字符串经过L便可输出S.P.单词字符串
主要由三部分组成:
1.规则定义式,定义识别规则中要用到的正则表达式名
2.识别规则,用正则表达式给出单词的定义和在识别后的下一步行为(例如要直行的代码片段)
3.用户子程序,给出用户需要的其他操作
各部分之间需要用%%分开
规则定义式:如下形式的LEX语句
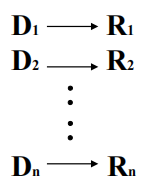 ,D为正则表达式名字,简名;R为正则表达式
,D为正则表达式名字,简名;R为正则表达式
例如:

识别规则:一串如下形式的LEX语句
 P为定义在Σ∪{D1,D2,D3…..}上的正则表达式,词形
P为定义在Σ∪{D1,D2,D3…..}上的正则表达式,词形
A为语句序列,是指识别出词形为P的但此后,词法分析器所应做的动作,基本动作即返回单词的类别编码和单词值。
一个完整的LEX源程序:

小提示:正则中{}+,表示至少1次重复
3.7.2 LEX的实现
LEX的功能是根据LEX源程序构造一个此法分析程序,该词法分析器实质上是一个有穷自动机。
LEX生成的词法分析程序由两部分组成:状态转换矩阵DFA和控制执行程序。则有LEX的功能即根据LEX源程序生成状态转换矩阵和控制程序。
LEX的处理过程:
NFA(空符号,多后继),DFA一定是NFA
转化成的DFA,每个新的终止状态所识别的单词类型,根据该子集包含的原NFA的终止状态而定,只包含一个,则就是那个终止状态是别的单词,如果多个,则需要加一个或。
1.扫描每条识别规则P构造一相应的非确定有穷自动机M
2.将各条规则的有穷自动机Mi合并成一个新的NFA M
3.NFA确定化为DFA
4.生成该DFA的状态转换矩阵和控制执行程序
LEX的二义性原则,两原则
例如begin是关键字还是标识符
1.最长匹配原则
在识别单词过程中,有一字符串根据最长匹配原则,应识别为这是一个符合Pk规则的单词而不是小范围的:

2.最优匹配原则
如有一字符串,有两条规则可以匹配,那么用规则序列中位于前面的规则相匹配,即排列在前面的的规则优先权高。
LEX实例:

1.得出单独的NFA

2.合并为一个NFA

3.确定化
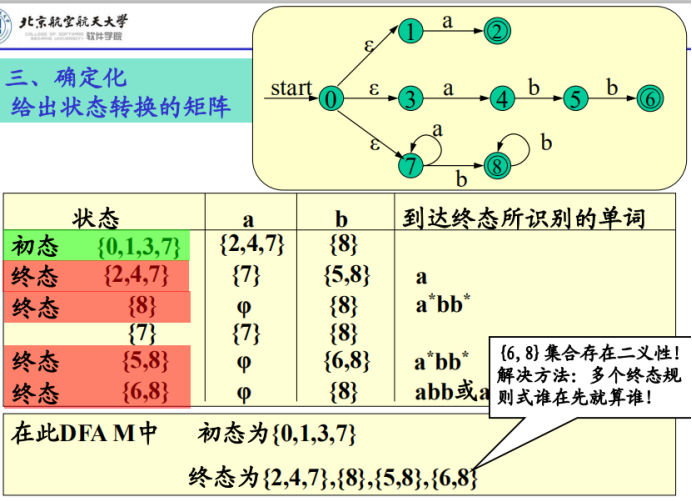
4.最后写出状态转换矩阵和控制程序即可
分析过程:

构造出的LEX是一个通用的工具,用它可以生成各种语言的语法分析程序,只需要根据不同的语言书写不同的LEX源文件就可以了。
LEX不但能自动生成词法分析其,而且也可以产生多种模式识别器及文本编辑程序。
题目讲解
在描述推导过程是,如果有了根据…,则不必再说一个“可得”了
做题时注意判断所有的终结符和非终结符,看题
判断短语:在一句型的语法树中,对任意结节点U,如果以其为根节点的子树高度不为0,将此子树的所有叶节点连接得到串u,u则是相对于U的对于该句型的短语,也就是说即使在树的最后,只要有f→p,且p后无延伸,则p本身也是一个短语,且是一个简单短语。
在绘制特定描述的字符串自动机时,直接编写语法可能会不够随机,可以用状态图进行辅助。
在根据集合获取对应字符的后继集合时,步骤如下:遍历集合的每个状态,获取每个状态通过任意长度符号为该符号的弧到达的状态以及从该状态经过任意长ε弧到达的状态(不包含出发的那个状态,除非可以通过这两种方法到达)。遍历结束后汇总获取到的状态即可获得新的集合。
左右线性:根据右侧非终结符的位置而定,在左则左。
左右线性文法生成状态图:后续补充。
给出描述的正则表达式时,注意几个点:保持随机,分段构造表达式,注意符号的真正含义(*是重复,并且是从0到无穷的,并且如果没括号只能重复一个,例如(11)*就是偶数个重复)。
表达式构造FA:从外开始从左开始,并且*转时,两个ε不是必需的,何时使用??
进行确定化时由于是集合类型,所以注意看清
判断NFA:同一个符号两个后继、有ε弧
FA的五元:全部状态,全部符号,转化矩阵,开始状态(非空开始集合),终止状态集合。注意状态转化后如果是{},就是多个后继。
