Scheme语言实例入门–怎样写一个“新型冠状病毒感染风险检测程序”
- 2020 年 4 月 11 日
- 筆記
小学生都能用的编程语言
2020的春季中小学受疫情影响,一直还没有开学,孩子宅在家说想做一个学校要求的研究项目,我就说你做一个怎么样通过编程来学习数学的小项目吧,用最简单的计算机语言来解决小学数学问题。虽然我是一个老码农,但一直不赞成教小学生学编程,觉得这是揠苗助长,小学生不应该过早的固化逻辑思维而放松形象思维,某些少儿编程机构居然教学C++游戏编程,我觉得这真是在摧残祖国的花朵。现在孩子宅在家 ,想让他学点什么好几次冒出学编程的想法都被自己给否决了,直到我看到数学老师要求同学们整理小学阶段的数学公式、概念,我看到有一个小朋友居然画出了平面几何体的“继承”关系,让我眼前一亮:这种抽象关系如果用程序来表示不正合适吗?明白抽象方法了,那么学编程问题就不大了。于是我在想应该教孩子学什么语言比较好:LOGO、VB还是炙手可热的Python?虽然我非常熟悉C#,但需要了解许多背景知识,还需要安装一个很大的框架环境,显然C#不适合小学生学习,Java也是。LOGO是老牌的儿童编程语言了,操控一个小海龟来画图很形象,VB入门简单,但要一个小学生熟悉它的集成开发环境要求还是高了点,选Python无非就是因为AI应用火它就火,除此之外我找不出它适合儿童使用的理由。
我觉得给小学生使用的编程语言,要足够简单:
1,编程环境足够简单,一个命令行就行,不需要一个强大的IDE,否则用它还得熟悉很多菜单按钮和概念;
2,语法要足够简单,最好连变量都不需要定义,没有各种复杂的程序结构或语句,不需要了解方法、类、包、模块这些东西,拿来就能写程序跑起来;
3,数据结构要简单,什么数组、队列、堆栈或者树等等不要太多。
想到这里,唯一满足要求的就是Lisp语言了,它简单到只有3种最基本的数据结构:原子、表和字符串;只有一种语法,就是符号表达式,数据和函数都是采用符号表达式定义的,这种符号表达式称为S一表达式,它是原予和表的总称。Lisp衍生出了很多方言,形成一个庞大的Lisp语言家族,Scheme是其中最简单的方言,而且很长时间都是美国麻省理工学院计算机系的教学语言,Scheme的发明者和推动者都是数学家、科学家和教育学家,所以它一开始就有数学的基因,非常适合作为一种入门的计算机教学语言。前面说到孩子上数学课需要,那么Scheme语言就是不二之选了,B站有一个小学生用Scheme语言来表达三角形定理应用的小视频,可以点击这里查看。
项目程序简介
既然决定教孩子Scheme语言,那我就得先熟悉一下它了,之前断断续续学习了几次,一直没有真正用过它所以始终没学好,现在疫情期间,正好可以用它来写一个程序练手,并且使用这个有实际意义的程序作为小学生学习Scheme语言的入门教程,于是有了本篇文章标题说的这个项目,一个2019新型冠状病毒肺炎(COVID-19)感染风险自助检测程序。为了更好的介绍Scheme语言,本文将结合这个实例程序来介绍Scheme语言的语法元素,于是有了这篇博客文章。读者可以先从下面的仓库地址克隆一份,包括源码和Scheme运行程序。
源码仓库:https://github.com/bluedoctor/Check-COVID-19
程序名称:2019新型冠状病毒肺炎(COVID-19)感染风险自助检测程序
程序功能:
根据网络上收集整理的新冠肺炎临床症状表现,以及国家卫生健康委员会与国家中医药管理局发布了《新型冠状病毒肺炎诊疗方案》等资料, 整理的新冠肺炎临床症状表现、医院检查和流行病学调查情况,设计的一个风险测试表,然后根据这个风险测试表定义的诊断知识编写程序,交互式的引导用户回答提问,最后给出诊断结果。 你也可以调整这里定义的各个指标风险值,以使它更接近实际的效果。
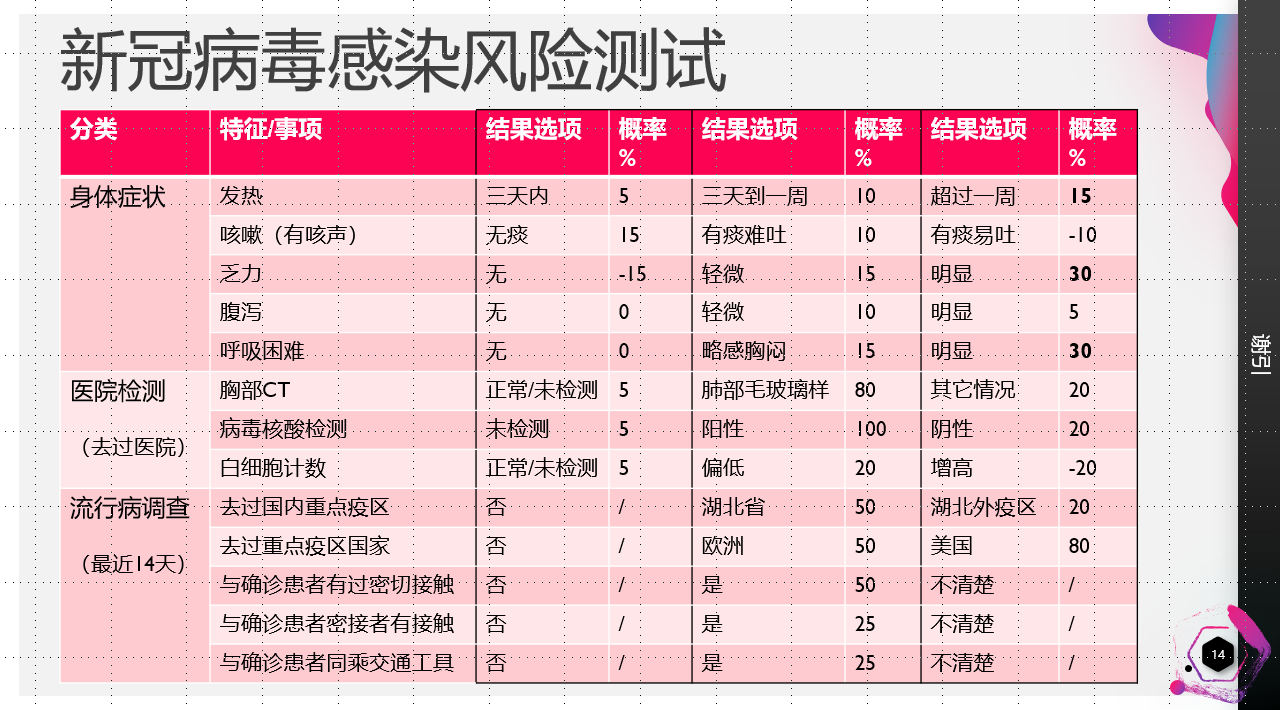
有了这个风险测试表,如何简单有效的用程序表示,这也是我选择使用Scheme语言来写这个程序的原因,因为它的S表达式具有程序和数据的一致性,也就是说我们的知识数据可以表达为一种等价的程序结构,比如将上表的身体症状表达为下面的程序结构:
; 2019新型冠状病毒肺炎(COVID-19)感染风险自助检测程序 (define A1 (list "发热" (cons "三天内" 5) (cons "三天到一周" 10) (cons "超过一周" 15))) (define A2 (list "咳嗽" (cons "无痰" 15) (cons "有痰难吐" 10) (cons "有痰易吐" -10))) (define A3 (list "乏力" (cons "无" -15) (cons "轻微" 15) (cons "明显" 30))) (define A4 (list "腹泻" (cons "无" 0) (cons "轻微" 10) (cons "明显" 5))) (define A5 (list "呼吸困难" (cons "无" 0) (cons "略感胸闷" 15) (cons "明显" 30)))
这个症状风险知识的程序表示代码涉及的Scheme语言概念下面逐一介绍。
Scheme语言基础
1,表达式
最简单的表达式是常量对象,如字符串、数字、符号和列表。表达式支持其它对象类型,但这四种对象对大多数程序已经足够了。
数字型(number)
它又分为四种子类型:整型(integer),有理数型(rational),实型(real),复数型(complex);它们又被统一称为数字类型(number)。
如:复数型(complex) 可以定义为 (define c 3+2i)
实数型(real)可以定义为 (define f 22/7)
有理数型(rational)可以定义为 (define p 3.1415)
整数型(integer) 可以定义为 (define i 123)
符号类型(symbol)
是Scheme语言中有多种用途的符号名称,它可以是单词,用括号括起来的多个单词,也可以是无意义的字母组合或符号组合,它在某种意义上可以理解为C中的枚举类型。可以使用quote操作符定义一个符号,也可以单引号’开头来简单表示一个符号,如下面的示例:
> (quote a) a >'a a
在Lisp/Scheme 中,通常都需要对表达式进行求值,而符号(通常)不对自身求值,所以要是想引用符号,应该像上例那样用 ‘ 引用它。
复合表达式
由操作符、常量对象或者表达式组合而成。例如下面这个计算两个数相加的简单表达式:
> (+ 1 2) 3
通过这个程序示例看到,Scheme的表达式是前缀表达式,也就是说把运算符放在最左侧。这样做的优点是可以定义带任意个数的实参过程。
上面这个复合表达式如果想引用它而不是立即求值,就需要把它定义成符号:
> '(+ 1 2) (+ 1 2)
这样,我们可以在后续需要的时候将这个符号转换成普通的表达式让它求值。
S-表达式
Lisp 要求我们直接在抽象语法上工作。这个抽象的语法树用成对的括号表示。这样的结构在 Lisp 圈子里面被称为 sexp 表达式,俗称S-表达式。S-表达式的第一个单词决定了 sexp 的意义,剩下的单词都是参数,记住这一条规则足够了。这个规则使得我们不需要记忆其它编程语言那些复杂的语法结构,入门使用变得极其简单。我们在设计程序的时候应该始终围绕这个抽象语法进行,我们的程序设计的越抽象,那么程序就越接近问题的本质。
Lisp 程序看成是完全由”函数调用”这个单一的语法结构构成。 Lisp 里面没有为了算术表达式、或者逻辑表达式、或者语言的关键字,比如 IF 和 THEN,来准备特别的语法结构。所有的语言元素在 Lisp 里面都是按照这个简单一致的语法结构来安排,整个程序就是一个表达式,程序的运行就是对表达式进行求值。
2,原子
Lisp中有一个叫原子的东西,不可再分,是一个很基础的概念。原子可以是任何数,分数,小数,自然数,负数等等。原子可以是一个字母排列,当然其中可以夹杂数字和符号。除了表和所有函数以外均是原子。
Scheme没有直接说原子这个概念,但Scheme作为Lisp的方言,在形式上还是有原子这样的东西。所有的 Lisp/Scheme 表达式,要么是 1 这样的数原子,要么是包在括号里,由零个或多个表达式所构成的列表。所以可以这样说,List程序里面就是原子和表。这就是Lisp 表示法一个美丽的地方是:它是如此的简单!
3,表(list)
表是由多个相同或不同的数据连续组成的数据类型,它是编程中最常用的复合数据类型之一,很多过程操作都与它相关。下面是在Scheme中表的定义和相关操作:
> (define la (list 1 2 3 4 )) >la (1 2 3 4) > (length la) ; 取得列表的长度 4 > (list-ref la 3) ; 取得列表第3项的值(从0开始) 4 > (list-set! la 2 99) ; 设定列表第2项的值为99 99 > la (1 2 99 4) > (define y (make-list 5 6)) ;创建列表 > y (6 6 6 6 6)
在上面的例子中,使用了函数list 来构造具有4个元素的表,然后使用define函数来定义一个变量 la,将变量la与前面定义的表相绑定。除了使用list函数形势来构造表,还可以使用引用方式来使用一个表,下面的代码与上面定义la 变量绑定表是等价的:
> (define la (list 1 2 3 4 )) >la (1 2 3 4) > (define la '(1 2 3 4 )) >la (1 2 3 4)
回到文章开头,我在这个小项目中首先就定义了几个表并且与变量相绑定:
(define A1 (list “发热” (cons “三天内” 5) (cons “三天到一周” 10) (cons “超过一周” 15)))
4,点对(pair)
List/Scheme 的基本构成元素是所谓的 Pair。什么是 Pair 呢??我们可以按照这个英语单词在日常生活中最常见的意思,比如一个坐标点,来想象这个最基础的数据结构。比如坐标(1,2)是一个点对。一个点对包含两个指针,每个指针指向一个值。我们用函数cons构造点对。比如说(cons 1 2)就构造出点对(1 . 2)。因为点对总是由函数cons构造,点对又叫做cons cell。点对左边的值可以用函数car取出来,右边的值可以由函数cdr取出来。比如列表(1 2 3 4),实际上由点对构成:(1 . (2 . (3 . 4. ‘())。可以看出,列表本质是单向链表。
在当前实例程序的表变量A1中,我们构造了一个具有发热症状对应风险属性的表,它有三个点对元素,分别是:
( 三天内 . 5 ) ( 三天到一周 . 10 ) (超过一周 . 15)
构造这3个点对元素分别通过下面的三个表达式实现:
(cons “三天内” 5)(cons “三天到一周” 10)(cons “超过一周” 15)
在表变量A1 中,可以通过cdr函数得到这3个点对元素:
>(car A1) 发热 >(cdr A1) ( 三天内 . 5 ) ( 三天到一周 . 10 ) (超过一周 . 15)
可以看出,我们在程序中,使用点对模拟了症状属性和对应的风险值结构,类似于.NET中的“名-值”对结构。所以,我们通过Scheme程序,实现了新冠病毒临床诊断知识表达的 “症状–属性–风险值” 三元结构,我们的程序就是匹配患者的这些症状属性,从而计算出相对应的风险值。Scheme的表和点对结构,使得我们对于这类知识的表达更直观更容易。
5,向量(vector)
向量可以说是一个非常好用的类型 ,是一种元素按整数来索引的对象,异源的数据结构,在占用空间上比同样元素的列表要少,在外观上:
列表示为: (1 2 3 4)
VECTOR表示为: #(1 2 3 4)
可以通过下面的代码来定义和查看向量的表示:
>(define v (vector 1 2 3 4 5)) #(1 2 3 4 5) >(define v ‘#(1 2 3 4 5)) #(1 2 3 4 5) > (vector-ref v 0) ; 求第n个变量的值 1 > (vector-length v) ; 求vector的长度 5 > (vector-set! v 2 "abc") ; 设定vector第n个元素的值 > v #(1 2 "abc" 4 5) > (define x (make-vector 5 6)) ; 创建向量表 > x #(6 6 6 6 6)
在当前项目实例中,我们将所有相关的症状变量放到一个向量中:
(define QA (vector A1 A2 A3 A4 A5))
之后,我们会在程序中循环遍历这些症状表,获取向量QA的长度,获得QA指定索引的表元素。
6,变量
变量定义:
可以用define来定义一个变量,形式如下:
(define 变量名 值)
例如,上面定义了一个变量QA,它的值是一个向量。
前面的示例中好多地方都采用了这种方式来定义变量,但这种方式定义的是一个全局变量,但很多时候,我们需要使用局部变量,以消除全局变量可能意外被修改的影响。
定义局部变量需要使用let表达式,如下所示:
> (let ((x 1) (y 2)) (+ x y)) 3
这里定义了两个变量:x和y,定义的时候给它们分别绑定一个初始值1和2。
let表达式的形式定义是:
(let [binds]
bodys
)
变量在binds定义的形式中被声明并初始化。body由任意多个S-表达式构成。binds的格式如下:
[binds] → ((p1 v1) (p2 v2) …)
声明了变量p1、p2,并分别为它们赋初值v1、v2。变量的作用域(Scope)为body体,也就是说变量只在body中有效。body体的最后一个表达式的值为let表达式的值。
更改变量的值:
可以用set!来改变变量的值,格式如下:
(set! 变量名 值)
如在当前实例程序中:
(define Total_Risk 0) ;定义全局 风险总值 变量 ;其它代码略 (display "单纯性发热,调低风险值。")(newline) (set! Total_Risk (- Total_Risk 15))
Scheme语言是一种高级语言,和很多高级语言(如python,perl)一样,它的变量类型不是固定的,可以随时改变。
7,函数
Scheme语言中函数不同于其它语言的函数,它被称为过程(Procedure)。过程是一种数据类型,这也是为什么Scheme语言将程序和数据作为同一对象处理的原因。
如果我们在Chez Scheme提示符下输入加号然后回车,会出现下面的情况:
> + #<procedure +>
这告诉我们”+”是一个过程,而且是一个原始的过程,即Scheme语言中最基础的过程,在GUILE中内部已经实现的过程,这和类型判断一样,如boolean?等,它们都是Scheme语言中最基本的定义。
define不仅可以定义变量,还可以定义过程,因在Scheme语言中过程(或函数)都是一种数据类型,所以都可以通过define来定义。不同的是标准的过程定义要使用lambda这一关键字来标识。
我们可以自定义一个简单的过程并使用,如下:
> (define add1 (lambda (x) (+ x 1))) > add1 #<procedure add1> > (add1 5) 6
在Scheme语言中,也可以不用lambda,而直接用define来定义过程,它的格式为:
(define (过程名 参数) (过程内容 …))
在当前实例程序中,都使用了这种方式来定义过程,个人觉得这种方式更方便些。例如下面定义一个过程确保用户输入一个数字并返回:
(define (input_selected ) (let loop () (display "请输入你选择的答案对应的数字:") (let ((k (read))) (if (integer? k) k ;return (begin (display "输入错误!") (newline) (loop))))))
在Scheme语言中,过程定义也可以嵌套,一般情况下,过程的内部过程定义只有在过程内部才有效,相当C语言中的局部变量。
8,类型判断
Scheme语言中所有判断都是用类型名加问号再加相应的常量或变量构成,例如上面定义的函数input_selected 中使用 integer? 来判断用户输入的内容是否是一个整数:(integer? k)
也可以使用null?判断一个对象是否是空类型:
(null? (cdr name-values))
9,逻辑运算
逻辑运算实际上是计算一个逻辑表达式。原子逻辑表达式是布尔对象,在Scheme中使用 #t 表示true,#f 表示false。
逻辑表达式支持not,and,or 逻辑操作,类型判断的结果也是一个逻辑表达式,例如在本项目实例中:
;测试是否有严重腹泻并且没有咳嗽 (let ((FU_XIE (have_attribute_inResult Ctx_Attributes "腹泻"))) (if (and (not (null? FU_XIE)) (equal? "明显" (car (cdr FU_XIE))) (null? KE_SOU) ) (set! Total_Risk 0) ;为严重腹泻引起的乏力,不会是新冠感染。 (begin (display "乏力伴随咳嗽或者发热,调高风险值。")(newline) (set! Total_Risk (* Total_Risk 2)) ) ) )
and和or表达式都可以处理多个逻辑表达式参数,例如上面的and 表达式处理了三个逻辑判断表达式。
10,代码块(form)
块(form)是Scheme语言中的最小程序单元,一个Scheme语言程序是由一个或多个form构成。没有特殊说明的情况下 form 都由小括号括起来,所以一个form最小可以是一个表达式,也可以是一个变量定义,一个过程定义。form允许嵌套,这使它可以轻松的实现复杂的表达式,同时也是一种非常有自己特色的表达式。有时候需要将多个表达式组合成一个form,比如在分支判断后执行多个操作,需要在一个块中,这个功能可以通过begin来实现,例如上面逻辑运算的例子。
11,分支结构
if结构:
Scheme语言的if结构有两种格式:
(if (测试条件)(满足测试条件时 要执行的过程1))
(if (测试条件)(满足测试条件时 要执行的过程1)
(否则 要执行的过程2) )
要执行的过程1和2可以是一个表达式,也可以是多个表达式,如果是多个表达式,需要使用begin语句块。if结构的示例代码比较多,这里就不再重复了。
cond结构:
Scheme语言中的cond结构类似于C语言中的switch结构,cond的格式为:
(cond ((测试) 操作) … (else 操作))
cond结构的每个测试都可以是不同的逻辑表达式,相当于多个嵌套的if…else if…结构,在当前实例项目中就曾经使用cond结构来优化,示例代码如下:
;从结果中判断是否有指定的症状属性;如果有,返回症状特征表;如果没有,返回空表 (define (have_attribute_inResult result attName) (let loop ( (lst result) ) (let ( (car_lst (car lst)) (cdr_lst (cdr lst))) ;(if (equal? attName (car car_lst)) ; car_lst ; (if (null? cdr_lst) ; '() ; (loop cdr_lst) ; ) ;) ; (cond ((equal? attName (car car_lst)) car_lst ) ((null? cdr_lst) '()) (else (loop cdr_lst)) ) ) ) )
case结构:
case结构和cond结构有点类似,它的格式为:
(case (表达式) ((值) 操作)) ... (else 操作)))
case结构中的值可以是复合类型数据,如列表,向量表等,只要列表中含有表达式的这个结果,则进行相应的操作,如下面的代码:
>(case (* 2 3) ((2 3 5 7) 'prime) ((1 4 6 8 9) 'composite)) composite
上面的例子返回结果是composite,因为列表(1 4 6 8 9)中含有表达式(* 2 3)的结果6;
在当前实例项目中,使用case结构来进行流行病调查分析:
(display "2)最近14天,您是否去过 重点疫区国家?(0-未去过,1-意大利、西班牙,2-欧洲其它地方,3-美国,4-世界其它地方)") (newline) (set! Total_Risk (+ Total_Risk (case (input_selected) ((0) 0) ((1) 50) ((2 4) 30) ((3) 80) (else 0) ) ))
12,循环结构
使用递归实现循环:
Scheme最原始的语法结构是没有循环的,要实现循环功能,可以通过递归调用过程实现:
>(define loop (lambda(x y) (if (<= x y) (begin (display x) (display #\space) (set! x (+ x 1)) (loop x y))))) >(loop 1 10) 1 2 3 4 5 6 7 8 9 10
使用递归过程来实现循环虽然比较直观自然,然而它的效率不高。要改善递归效率,可以将递归过程修改为尾递归,Scheme语言规范规定尾递归将在语言内部优化为循环结构。有关尾递归的概念这里不再详细介绍。
使用命名let:
let表达式本质上是一个Scheme语法糖,它内部转换成了lambda表达式调用。命名let在Scheme中与尾递归有相似的效果,具体可以参考这篇文章。
在本实例项目中,使用了命名let来实现循环,例如前面示例的函数have_attribute_inResult的定义里面使用了命名let,下面看一个简单的例子,重新看到input_select函数的示例,注意let后的符号 loop就是它的名字:
(define (input_selected ) (let loop () (display "请输入你选择的答案对应的数字:") (let ((k (read))) (if (integer? k) k ;return (begin (display "输入错误!") (newline) (loop))))))
在上面的过程中,如果输入的不是整数,会要求重新输入,循环执行这个过程直到输入正确为止,在最后一行通过重新调用前面名字为 loop的let实现循环效果。而在函数have_attribute_inResult中,命名let开始的时候将变量lst的初始值绑定为函数参数result,而在方法后面部分调用名字loop的let时候,使用变量cdr_lst来更新最这个命名let的值:
(define (have_attribute_inResult result attName) (let loop ( (lst result) ) (let ( (car_lst (car lst)) (cdr_lst (cdr lst))) (cond ((equal? attName (car car_lst)) car_lst ) ((null? cdr_lst) '()) (else (loop cdr_lst)) ) ) ) )
使用do循环表达式:
就像在C系列语言中我们通常用while比较多而do比较少一样,在scheme中do也并不常见,但语法do也可以用于表达重复。它的格式如下:
(do binds (predicate value) body)
变量在binds部分被绑定,而如果predicate被求值为真,则函数从循环中逃逸(escape)出来,并返回值value,否则循环继续进行。binds部分的格式如下所示:
[binds] – ((p1 i1 u1) (p2 i2u2)…)
变量p1,p2,…被分别初始化为i1,i2,…并在循环后分别被更新为u1,u2,…。
在当前实例项目中,也使用了do循环表达式,如下所示:
1 ;获取症状特征列表指定的特征序号(从1开始的序号)对应的风险值 2 (define (get-index-value lst_attribute index) 3 (do ((name-values (cdr lst_attribute) (cdr name-values)) 4 (i 1 (+ i 1))) 5 ( (or (= i index) (null? (cdr name-values))) ;break 6 (cdr (car name-values)) ;return value 7 ) 8 ;(display (cdr name-values )) 9 ;(newline) 10 ) 11 )
在上面的第3行代码中,循环变量name-values绑定的初始值是表达式(cdr lst_attribute),而在后续的循环过程中,循环变量name-values将被更新为一个新的值:表达式(cdr name-values)的值,也就是后续的症状(属性.风险值)点对。第5行是跳出循环的条件表达式,第6行代码是do循环表达式在终止循环后返回的值。do循环的body代码部分可以没有,上面的示例中将body代码注释了。
系统设计方案
1,诊断方案
根据《新型冠状病毒肺炎诊疗方案》,这里整理一个简单的诊断方案。这里需要从三方面进行。
首先是对患者身体症状的问诊,询问是否有发热、咳嗽、腹泻、乏力、呼吸困难等新冠肺炎典型的症状,再根据具体的症状表现来分析感染病毒的风险几率,经过综合分析,设计出每一个具体症状表现的风险值。
然后是医院化验检测报告分析,主要有胸部CT、核酸检测以及全血化验中的白细胞计数情况,如果核酸检测阳性那感染新冠病毒的几率就是100%,但检测阴性并不代表没有感染几率,核酸检测有一个准确性问题以及随着病情发展的检测时间问题,都会影响检测结果准确性。所以后来对很多疑似患者采取了依据肺部CT结果的临床确诊。最后就是白细胞计数,病毒感染一般白细胞计数都不会有明显变化,甚至下降,如果白细胞计数显著增高,那么要排除病毒感染,但也可能是合并细菌性炎诊感染。多以对于医院化验检测情况也需要综合设定一个风险值。
第三就是流行病学调查,对于有疑似感染的情况,如果与确诊患者有接触,或者去过重点疫区,那么感染的风险就很高,反之就较低。根据流调的具体情况,对每一类情况设定一个相应的风险值。
综合这三方面的分析,制定一个风险测试表。不过这个表也仅仅只能做一个参考,一方面具体的风险值需要专家来综合设定,另一方面这些风险因素是相互影响的,它们的关系不是一个表格这么简单,所以需要把这个风险测试表再根据患者有的测试项目进行综合分析,根据一些诊断规则,对风险值进行修正。所以这个诊断方案,非常依赖行业专家的知识,包括科学家、医学家以及临床一线医生。鉴于笔者能力水平,当前这个诊断方案肯定会有很多问题,仅供参考和学习Scheme语言编程使用。
2,专家系统
专家系统是一个具有大量的专门知识与经验的程序系统,是一种模拟人类专家解决领域问题的计算机程序系统。显然,写一个诊断新冠病毒感染风险的程序可以是一个专家系统,前面也说了这个诊断方案是依赖于专家的知识经验的。
专家系统通常由人机交互界面、知识库、推理机、解释器、综合数据库、知识获取等6个部分构成。其中尤以知识库与推理机相互分离而别具特色。下图是专家系统的一个结构示意图:
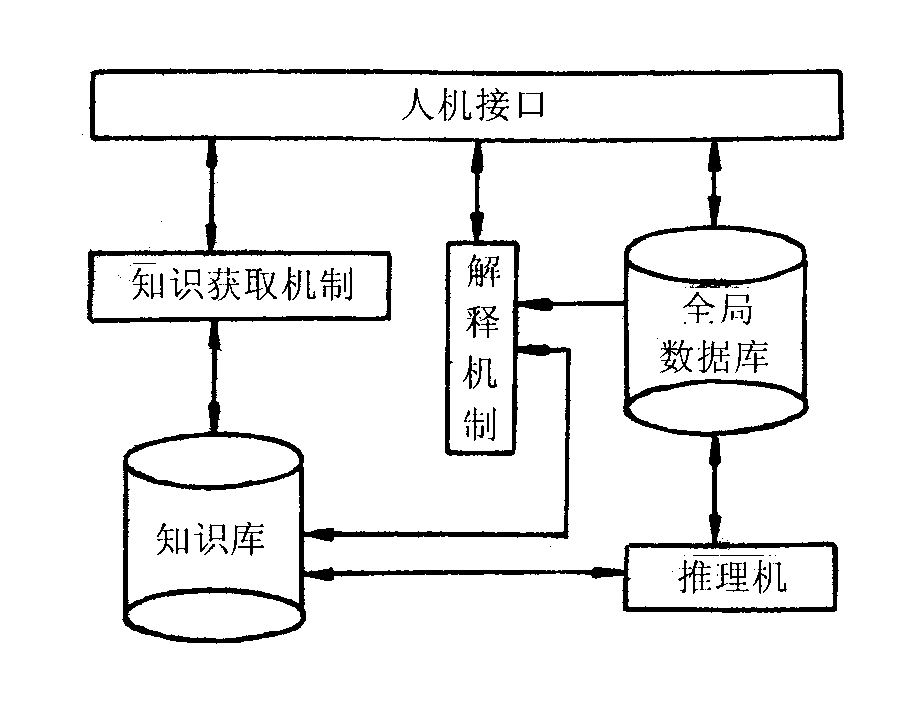
当前这个“诊断专家系统”程序中,也具有专家系统基本的元素,它们的设计方案是:
- 人机界面:采用交互式命令行方式,系统提问,用户根据提是选择回答问题,引导用户完成所有问题的测试。
- 知识库:将“新冠病毒感染风险测试表”的知识使用Scheme程序表示。
- 全局数据库:一个存储当前患者对象诊断数据的“特征上下文”对象,它是一个列表。
- 解释机制:每当用户回答一个问题,都会给出当前特征项的风险值,并在诊断完成后给出诊断数据。
- 推理机:它包括2个工作,一是根据用户回答的问题计算感染风险的累加值,另一个是根据一些特殊的风险属性相关性规则,来修正风险值,比如对于乏力症状特征与其它症状特征之间的关系进行处理的规则。
3,推理机制
采用不确定性推理机制。不确定性推理是指那种建立在不确定性知识和证据的基础上的推理。它实际上是一种从不确定的初始证据出发,通过运用不确定性知识,最终推出既保持一定程度的不确定性,又是合理和基本合理的结论的推理过程,目的是使计算机对人类思维的模拟更接近于人类的真实思维过程。
在当前项目中,患者的症状表现就是疾病诊断的一种证据,但这种证据所代表的诊断知识是不确定的。比如发热症状,很多疾病都会引起发热,一般感冒和流感都会发热,但发热的症状表现(例如持续时间和体温)是不同的,同一个症状表现也可能是不同疾病引起的,所以针对某一种疾病而言,每个症状表现都只能是一个该种疾病的确诊概率,需要综合多个症状表现才能在一个大概率上确认或者排除一种疾病。比如发热三天以内,没有咳嗽和呼吸困难,也没有乏力表现,那么是新冠的可能性就很低,如果还有鼻塞流鼻涕的表现,那么普通感冒的可能性就很大了。
在当前项目中,不确定性知识的表达采用【对象】-【特征】-【值】结构,【值】是一个“点对”结构,这个“点对”结构表示【值】的名称和【值】的数值结果,在当前程序中,【值】的具体数值表示感染风险值。例如发热是患者对象的一个症状特征,发热的具体表现,也就是特征的值,例如发热”三天内“是发热症状的特征值,它对应的新冠感染风险是5%。在当前项目中,发热症状的完整特征值表达为Scheme语言的“列表”,如下所示:
为了便于引用这个发热症状的不确定性知识,我们将它绑定到一个变量上,相当于为它定义一个编号:
这样,将咳嗽、乏力、腹泻、呼吸困难等症状都定义一个编号,组成一个身体症状“矩阵”,这个矩阵结构用一个向量来表示:
;定义 患者的身体症状特征 (define A1 (list "发热" (cons "三天内" 5) (cons "三天到一周" 10) (cons "超过一周" 15))) (define A2 (list "咳嗽" (cons "无痰" 15) (cons "有痰难吐" 10) (cons "有痰易吐" -10))) (define A3 (list "乏力" (cons "无" -15) (cons "轻微" 15) (cons "明显" 30))) (define A4 (list "腹泻" (cons "无" 0) (cons "轻微" 10) (cons "明显" 5))) (define A5 (list "呼吸困难" (cons "无" 0) (cons "略感胸闷" 15) (cons "明显" 30))) (define QA (vector A1 A2 A3 A4 A5))
使用【对象】-【特征】-【值】结构,我们处理可以定义患者的身体症状特征,还可以定义患者的医院化验检查结果特征:
;定义患者的医院化验检查结果特征 (define B1 (list "胸部CT" (cons "正常/未检测" 1) (cons "肺部毛玻璃样" 80) (cons "其它情况" 20))) (define B2 (list "病毒核酸检测" (cons "未检测" 5) (cons "阳性" 100) (cons "阴性" 20))) (define B3 (list "白细胞计数" (cons "正常/未检测" 1) (cons "偏低" 20) (cons "增高" -20))) (define QB (vector B1 B2 B3 ))
现在可以看到,通过这个【对象】-【特征】-【值】结构,我们可以表示一般的“不确定性知识”了,甚至用来表示学生考试题的答题选择率,用来发现班级的教学问题。
上面的每个特征都将形成一个要向患者询问的问题,这些问题的回答结果将在患者对象身上形成一个特征上下文。特征上下文的结构是一个表,包含多个具体的特征表,例如:
( (特征名1 特征值名 特质值) (特征名2 特征值名 特质值) …)
在当前程序中,它的值可能像下面这个样子:
((发热 三天内 5) (咳嗽 无痰 15) (乏力 无 -15) (腹泻 无 0) (呼吸困难 无 0))
患者对象的特征上下文对象,在程序中通过下面一行代码实现:
4,推理机的实现
有了推理所需要的不确定性知识表达结构,那么进行推理就很方便了:特征匹配。推理过程就是在与用户的交互过程中,通过询问用户的问题,如果该问题与预先定义的不确定性特征知识相匹配,那么就可以计算它对应的概率值(在本项目中是风险值)。推理的结果存放到特征上下文对象中,在本程序中,它是患者对象的症状问题上下文。
在本程序中,推理机的实现就是过程process-question 的定义,它会遍历特征向量中的每一个特征表,计算出匹配的特征值。过程实现的详细代码如下:
(define (process-question listAttributes) (let loop ((i 0) (j (- (vector-length listAttributes) 1))) (display (+ i 1)) (display ",您最近是否有【") (let ((Ai (vector-ref listAttributes i))) (display (car Ai)) (display "】的情况?(如果有,请输入数字1;否则输入其它字符以跳过此项检测。)") (newline) ;(let ((input 1)) ;test (let ((input (read)) (Ai_Name (car Ai))) (if (and (integer? input) (= input 1)) (begin (display Ai_Name) (display "的具体情况是:") (show-attribute Ai) (newline) (let ((q_index (input_selected ))) (display "您当前选择的情况风险值是:") (let ((curr_risk (get-index-value Ai q_index))) (display curr_risk) (set! Ctx_Attributes (append Ctx_Attributes (list (list Ai_Name (get-index-name Ai q_index) curr_risk )))) (set! Total_Risk (+ Total_Risk curr_risk)) ) ) ) (begin (display "您没有【") (display Ai_Name) (display "】的情况。") ) ) ) (newline) (newline) ) (if (< i j) (loop (+ i 1) j)) ))
下面我们就可以调用这个“推理机”来处理问题了:
(display " 一、开始身体症状测试 :")(newline) (process-question QA) (display "初步诊断详细内容:") (display Ctx_Attributes ) (newline) ;其它代码略 (display " 二、开始进行【医院检测结果】分析 :")(newline) (process-question QB)
结语
当前项目实例程序的完整代码请去前面说的Git仓库克隆一份,整个代码不到300行,其中很多代码已经作为Scheme语言基础的示例来介绍了,所以这里不再重复。通过这个项目,我们看到用Scheme语言来实现这样一个新冠病毒感染风险测试的专家系统是比较简单的,相信你阅读了本篇问诊并且下载运行这个程序之后,已经踏入了Scheme语言学习的大门。

