Redis 哨兵模式(Sentinel)
- 2020 年 4 月 11 日
- 筆記
上一篇我们介绍了 redis 主从节点之间的数据同步复制技术,通过一次全量复制和不间断的命令传播,可以达到主从节点数据同步备份的效果,一旦主节点宕机,我们可以选择一个工作正常的 slave 成为新的主节点,并让其他 slave 去同步它。
这是处理 redis 故障转移的一个方式,但却不具备生产实用性,因为毕竟是手动处理故障,而 redis 发生故障时间节点不可预知,我们需要一个自动监控组件帮我们自动处理故障转移。
Redis 哨兵模式(Sentinel)就是一个自动地监控处理 redis 间故障节点转移工作的一个「东西」,准确来说,Sentinel 其实是一个 redis 服务端程序,只不过运行在特殊的模式下,不提供数据存储服务,只进行普通 redis 节点监控管理。
一、什么是哨兵(Sentinel)
Sentinel 其实也是一个 redis 的服务端程序,它也会定时执行 serverCron 函数,只是里面其他的程序用不到,用到的是对普通 redis 节点的监控以及故障转移模块。
Sentinel 初始化的时候会清空原来的命令表,写入自己独有的命令进去,所以普通 redis 节点支持的数据读写命令,对 Sentinel 来说都是找不到命令,因为它根本就没有初始化这些命令的执行器。
Sentinel 会定时的对自己监控的 master 执行 info 命令,获取最新的主从关系,还会定时的给所有的 redis 节点发送 ping 心跳检测命令,如果检测到某个 master 无法响应了,就会在给其他 Sentinel 发送消息,主观认为该 master 宕机,如果 Sentinel 集群认同该 master 下线的人数达到一个值,那么大家统一意见,下线该 master。
下线之前需要做的是找 Sentinel 集群中的某一个来执行下线操作,这个步骤叫领导者选举,选出来以后会从该 master 所有的 slave 节点中挑一个合适的作为新的 master,并让其他 slave 重新同步新的 master。
其实以上我们就简单的介绍了 Sentinel 是什么,本质上做了哪些事情,等下我们会结合源码细说其中的细节实现。这里我们再看下,如何配置并启动一个 Sentinel 监控。(生产环境建议配置大于三个)
第一步,启动一个普通的 redis server 节点:
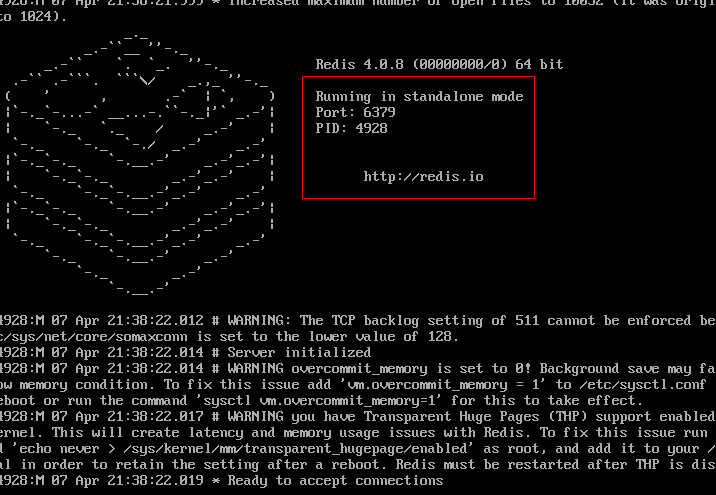
这一步没什么好说的,我们启动在一个默认的 6379 端口上。
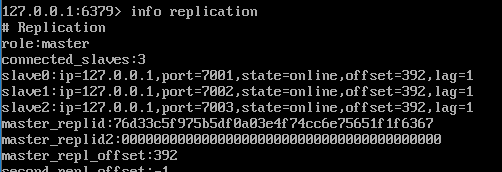
第二步,启动三个不同的 slave 节点:
第三步,编写 sentinel 配置文件:
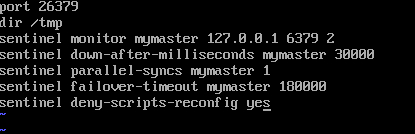
我们解释一下这几条配置的含义,我们说过 Sentinel 其实是运行在特殊模式下的 redis server,所以它需要运行端口。紧接着我们通过命令 sentinel monitor mymaster 配置当前 sentinel 需要监控的主节点 redis 以及触发客观下线参数,sentinel down-after-milliseconds 配置了一个参数,master 最长响应时间,超过这个时间就主观判断它下线。
sentinel parallel-syncs 配置用于限制主从切换之后,最多的并行同步数据的从节点数量,因为我们知道,主从进行全量同步阶段,从节点加载数据时是不提供服务的,如果这个参数越大,那么主从切换完成的时间就越短,当然也会导致大量从节点不可提供读服务,反之。
sentinel failover-timeout 配置了执行故障转移的最大等待时间。
第四步,启动 Sentinel:
使用命令,redis-sentinel [config],启动三个 sentinel。

这样的话,其实我们就完成了一个简单的 sentinel 集群配置,下面我们手动的让 master 宕机,看看整个 sentinel 有没有为我们做故障转移。
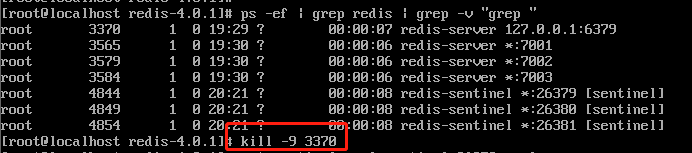
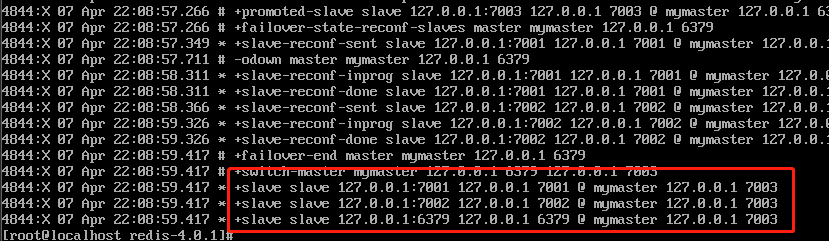
从结果上看来,sentinel 自动为我们把原先的从节点 7003 设置为新的 master,具体过程我们不细说,等下结合源码详细介绍,这里我们应该大致对 sentinel 的实际应用有了大概的认识。
二、Sentinel 如何工作的
当我们使用命令 redis-sentinel 启动 sentinel 的时候,
int main(int argc, char **argv) { 。。。。。 server.sentinel_mode = checkForSentinelMode(argc,argv); 。。。。。 if (server.sentinel_mode) { initSentinelConfig(); initSentinel(); } 。。。。。 } checkForSentinelMode 函数中会根据你的命令以及参数,检查判断是否是以 sentinel 模式启动,如果是则返回 1,反之。如果是以 sentinel 启动,则会进行一个 sentinel 的初始化操作。
void initSentinelConfig(void) { server.port = REDIS_SENTINEL_PORT; //26379 } initSentinelConfig 实际上就是初始化当前 sentinel 运行端口,默认是 26379。
void initSentinel(void) { unsigned int j; //清空普通redis-server下可用的命令表 dictEmpty(server.commands,NULL); //加载sentinel需要的命令 for (j = 0; j < sizeof(sentinelcmds)/sizeof(sentinelcmds[0]); j++) { int retval; struct redisCommand *cmd = sentinelcmds+j; retval = dictAdd(server.commands, sdsnew(cmd->name), cmd); serverAssert(retval == DICT_OK); } sentinel.current_epoch = 0; //根据配置文件,初始化自己需要监控的master(一个sentinel是可能监控多个 master的) sentinel.masters = dictCreate(&instancesDictType,NULL); sentinel.tilt = 0; sentinel.tilt_start_time = 0; sentinel.previous_time = mstime(); sentinel.running_scripts = 0; sentinel.scripts_queue = listCreate(); sentinel.announce_ip = NULL; sentinel.announce_port = 0; sentinel.simfailure_flags = SENTINEL_SIMFAILURE_NONE; sentinel.deny_scripts_reconfig = SENTINEL_DEFAULT_DENY_SCRIPTS_RECONFIG; memset(sentinel.myid,0,sizeof(sentinel.myid)); } initSentinel 主要的作用还是清空普通模式的 redis 命令表,加载独属于 sentinel 使用的命令,并初始化自己监控的 master 集合。
至此,sentinel 的初始化就算完成了,剩下的自动监控则在定时函数 serverCron 中,我们一起来看看。
//间隔 100 毫秒执行一次 sentinelTimer run_with_period(100) { if (server.sentinel_mode) sentinelTimer(); } 也就是说,sentinel 启动之后,会间隔 100 毫秒在 serverCron 调用一次 sentinelTimer 函数处理一些重要事件(其实,sentinelTimer 中会修改执行间隔)。
void sentinelTimer(void) { sentinelCheckTiltCondition(); sentinelHandleDictOfRedisInstances(sentinel.masters); sentinelRunPendingScripts(); sentinelCollectTerminatedScripts(); sentinelKillTimedoutScripts(); server.hz = CONFIG_DEFAULT_HZ + rand() % CONFIG_DEFAULT_HZ; } sentinelTimer 函数体非常简短,但不要高兴太早。sentinelCheckTiltCondition 函数我们不去多说,redis 高度依赖系统时间,如果多次检测到系统时钟纪元不准确,它会判定当前系统不稳定,进入 TITL,类似一个休眠的状态,不会为我们做故障转移,仅仅收集数据,等待系统恢复稳定。
void sentinelHandleDictOfRedisInstances(dict *instances) { dictIterator *di; dictEntry *de; sentinelRedisInstance *switch_to_promoted = NULL; di = dictGetIterator(instances); //递归遍历监控的所有 master,执行监控操作 while((de = dictNext(di)) != NULL) { sentinelRedisInstance *ri = dictGetVal(de); //这是监控的核心逻辑,下文细说 sentinelHandleRedisInstance(ri); if (ri->flags & SRI_MASTER) { //不论是 slave 还是其他 sentinel,都视作一个redisInstance sentinelHandleDictOfRedisInstances(ri->slaves); sentinelHandleDictOfRedisInstances(ri->sentinels); if (ri->failover_state == SENTINEL_FAILOVER_STATE_UPDATE_CONFIG) { switch_to_promoted = ri; } } } if (switch_to_promoted) sentinelFailoverSwitchToPromotedSlave(switch_to_promoted); dictReleaseIterator(di); } sentinelHandleRedisInstance 主要两个部分组成,监控和故障转移。
void sentinelHandleRedisInstance(sentinelRedisInstance *ri) { sentinelReconnectInstance(ri); sentinelSendPeriodicCommands(ri); if (sentinel.tilt) { if (mstime()-sentinel.tilt_start_time < SENTINEL_TILT_PERIOD) return; sentinel.tilt = 0; sentinelEvent(LL_WARNING,"-tilt",NULL,"#tilt mode exited"); } sentinelCheckSubjectivelyDown(ri); if (ri->flags & (SRI_MASTER|SRI_SLAVE)) { /* Nothing so far. */ } if (ri->flags & SRI_MASTER) { sentinelCheckObjectivelyDown(ri); if (sentinelStartFailoverIfNeeded(ri)) sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED); sentinelFailoverStateMachine(ri); sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_NO_FLAGS); } } sentinelReconnectInstance 函数做两件事,因为当前是一个 sentinel 实例,所以第一件事就是与当前遍历的 instance 建立连接,不论它是 master、slave 或是 sentinel,并在成功建立连接后发送 ping 命令。第二,如果当前遍历的是一个 master 或 slave,则会订阅它的 sentinel_hello 频道,当这个频道上有消息更新,则会广播所有订阅的该频道的客户端。(订阅这个频道的主要作用还是用于发现其他 sentinel 以及与其他 sentinel 交流自己对监控的节点的看法)
sentinelSendPeriodicCommands 函数默认每间隔十秒给 master 和 slave 发送 info 命令,了解他们的主从关系,如果此 instance 被自己主观下线了,那么会加快发送 info 命令的频率,以保证自己最快知道主从关系变化,还会每间隔一秒 ping 所有类型的实例。
以上其实是 sentinelHandleRedisInstance 中监控节点的部分,下面我们继续看其故障转移怎么做的。
void sentinelHandleRedisInstance(sentinelRedisInstance *ri) { sentinelReconnectInstance(ri); sentinelSendPeriodicCommands(ri); //判断是否需要进入 tilt 模式 if (sentinel.tilt) { if (mstime()-sentinel.tilt_start_time < SENTINEL_TILT_PERIOD) return; sentinel.tilt = 0; sentinelEvent(LL_WARNING,"-tilt",NULL,"#tilt mode exited"); } //判断是否需要主观下线该节点 sentinelCheckSubjectivelyDown(ri); if (ri->flags & (SRI_MASTER|SRI_SLAVE)) { /* Nothing so far. */ } if (ri->flags & SRI_MASTER) { //判断是否需要客户下线该节点 sentinelCheckObjectivelyDown(ri); //如果确定该节点客观下线,进行领导者选举 if (sentinelStartFailoverIfNeeded(ri)) sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED); //故障转移 sentinelFailoverStateMachine(ri); sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_NO_FLAGS); } } sentinelCheckSubjectivelyDown 检测当前节点是否需要主观下线,判断条件是此节点对于自己的配置,如果当前这个实例超过配置的时间段没有回复自己的 ping,那么判断它下线,设置主观下线标志位。
sentinelCheckObjectivelyDown 检测当前是否达到客观下线的条件,检测逻辑是这样的,遍历所有的兄弟 sentinel 结构,看看他们有没有把当前节点主观下线,统计数量,如果达到 quorum,则判定该 master 客观下线,设置标志位并通过频道通知到其他 兄弟 sentinel。
sentinelStartFailoverIfNeeded 判断当前是否已有 sentinel 在进行故障转移(通过 master 的一个标志位,如果有 sentinel 正在进行故障转移,这个标志位会被设置),如果有,则自己不参与,什么都不做。
sentinelAskMasterStateToOtherSentinels 会去给其他 sentinel 发送消息,要求它同意自己作为领导者对 master 进行故障转移。具体怎么做的呢,首先会拿到自己这边关于所有兄弟 sentinel 的信息进行一个遍历,并给他们发送命令 is-master-down-by-addr 要求他们同意自己成为领导者,并设置回调函数 sentinelReceiveIsMasterDownReply 处理回复。
如果某个 sentinel 收到别人发来的领导者投票,且自己没有给其他人投过票的话就会同意,反之不予理睬。
当某个 sentinel 收到足够的票数,则它认为自己就是 leader,标志 master 为故障转移中,并进行真正的故障转移操作。
void sentinelFailoverStateMachine(sentinelRedisInstance *ri) { serverAssert(ri->flags & SRI_MASTER); if (!(ri->flags & SRI_FAILOVER_IN_PROGRESS)) return; switch(ri->failover_state) { //故障转移开始 case SENTINEL_FAILOVER_STATE_WAIT_START: sentinelFailoverWaitStart(ri); break; //选择一个要晋升的从节点 case SENTINEL_FAILOVER_STATE_SELECT_SLAVE: sentinelFailoverSelectSlave(ri); break; //发送slaveof no one命令,使从节点变为主节点 case SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE: sentinelFailoverSendSlaveOfNoOne(ri); break; //等待被选择的从节点晋升为主节点,如果超时则重新选择晋升的从节点 case SENTINEL_FAILOVER_STATE_WAIT_PROMOTION: sentinelFailoverWaitPromotion(ri); break; //给所有的从节点发送slaveof命令,同步新的主节点 case SENTINEL_FAILOVER_STATE_RECONF_SLAVES: sentinelFailoverReconfNextSlave(ri); break; } } sentinelFailoverStateMachine 故障转移包括五个步骤,分五个 sentinelTimer 执行周期处理。当新 master 选举完成,会给其他兄弟 sentinel 广播,告知他们新的 master 已经出现,他们收到后,会撤销对原 master 的主观下线,并重新开始监控新的 master。
至此,我们对 Sentinel 的介绍与源码分析就结束了,它本质上就是一个运行在特殊模式下的 redis-server,通过不断 ping 主从节点,在感知他们可能出现故障之后,集体进行一个投票认定并选举出一个人去执行 master 的客观下线。
下一篇,我们看 redis 中更牛逼的 cluster。



