使用ElasticSearch赋能HBase二级索引 | 实践一年后总结
- 2020 年 4 月 10 日
- 筆記
前言:还记得那是2018年的一个夏天,天气特别热,我一边擦汗一边听领导大刀阔斧的讲述自己未来的改革蓝图。会议开完了,核心思想就是:我们要搞一个数据大池子,要把公司能灌的数据都灌入这个大池子,然后让别人用 各种姿势 来捞这些数据。系统从开始打造到上线差不多花了半年多不到一年的时间,线上稳定运行也有一年多的时间。今天想简单做个总结。
一。背景介绍
公司成立差不多十五六年了,老公司了。也正是因为资格老,业务迭代太多了,各个业务线错综复杂,接口调用也密密麻麻。有时候A向B要数据,有时候B向C要接口,有时候C向A要服务;各个业务线各有各的财产,各自为营,像一个个小诸侯拥兵自重,跑腿费会议费都贵的很。面对这个现状,我们急需进行一波大改造了。
而这个系统(我们暂且叫它天池吧),正是为了整合公司各个业务线的资源,改造这个错综复杂的蜘蛛网为简单的直线班车。省去不必要的接口调用、业务穿插、会议沟通以及不知去哪里拿数据、拿不到数据、拿数据慢的困扰。当然,更节省了产品、开发人员的时间,提升了各业务线整体工作效率。
几个词形容一下天池:稳、快、大、省、清晰。
二。业务梳理
经过对公司各线业务进行梳理,总结出以下几大常见的数据输出模型:
-
Key-Value快速输出型,最简单的kv查询,并发量可能很高,速度要求快。比如风控。
-
Key-Map快速输出型,定向输出,比如常见的通过文章id获取文章详情数据,kv查询升级版。
-
MultiKey-Map批量输出型,比如常见的推荐Feed流展示,Key-Map查询升级版。
-
C-List多维查询输出型,指定多个条件进行数据过滤,条件可能很灵活,分页输出满足条件的数据。这应该是非常常见的,比如筛选指定标签或打分的商品进行推荐、获取指定用户过去某段时间买过的商品等等。
-
G-Top统计排行输出型,根据某些维度分组,展示排行。如获取某论坛热度最高Top10帖子。
-
G-Count统计分析输出型,数仓统计分析型需求。
-
Multi-Table混合输出型,且不同表查询条件不同,如列表页混排输出内容。
-
Term分词输出型
或许还有更多数据模型,这里就不再列举了。从前端到后台,无论再多数据模型,其实都可以转化为索引+KV的形式进行输出,甚至有时候,我觉得索引+KV>SQL。
基于此业务数据模型分析及公司对ElasticSearch的长期使用,我们最终选择了HBase + ElasticSearch这样的技术方案来实现。
三。架构设计与模块介绍
先看一下整体架构图,如下图:
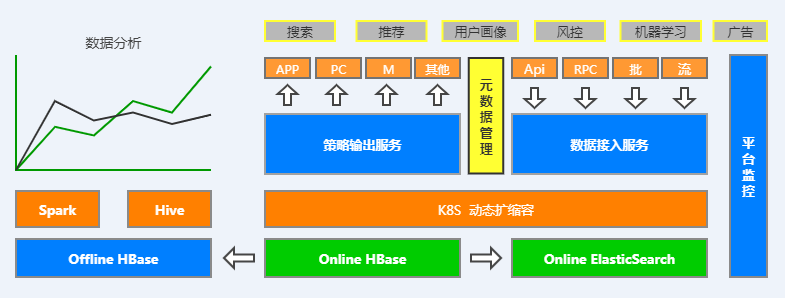
整个天池系统核心主要分为数据接入层、策略输出层、元数据管理、索引建立、平台监控以及离线数据分析六大子模块,下面将分别对其进行介绍。
1. 数据接入模块介绍
数据接入模块我们主要对HBase-Client API进行了二次轻封装,支持在线RESTFUL服务接口和离线SDK包两种主要方式对外提供服务,同时兼容HBase原生API和HBase BulkLoad大批量数据写入。
其中,在线RESTFUL服务以HBase Connection长连接的方式对外提供服务,好处是:在性能影响不大的情况下方便跨语言操作,更主要的一点是便于管理。在这一层,可以做很多工作,比如权限管理、负载均衡、失败恢复、动态扩缩容、数据接口监控等等,当然这一切都要感谢K8S的强大能力。
2. 策略输出模块介绍
该模块主要就是对接我们上文业务梳理模块归纳的各种业务需求,都由此模块提供服务。顾名思义,策略模块主要用于为用户配置策略,或用户自己配置策略,最终基于策略生成策略ID。
这一层我们主要是对ElasticSearch和HBase的一些封装,通过动态模板将用户请求转化为ElasticSearch DSL语句,而后对ES进行查询,直接返回数据或是获取到rowkey进而查询HBase进行结果返回。
通过元数据管理中心,我们可以判断出用户所需字段是否被索引字段覆盖,是否有必要二次查询HBase返回结果。而这整个查询过程,用户并不会感知,他们只需要一个PolicyID即可。
当然,我们也在不断普及用户如何通过后台自己配置生成策略。合作较多的业务方,甚至可以自己在测试环境配置好一切,完成数据的自助获取工作。而我们需要做的,只是一键同步测试环境的策略到线上环境,并通知他们线上已可用。整个过程5~10分钟,一个新的接口就诞生了。
其次,由于ES抗压能力毕竟不如HBase猛,我们的策略接口也会根据业务需求决定是否开启缓存。事实上,大部分接口是可以接受短时间内数据缓存的。当然像简单KV、K-Map、Mk-Map这种是直接走HBase的,需求量也挺大。
到目前为止,上述业务输出模型基本都已支持动态策略配置。这真的要感谢ElasticSearch强大的语法和业务场景覆盖能力,毕竟在我看来,ElasticSearch更像是一个为业务而生的产品。深入了解ES后,你会发现在有些方面它真的比SQL更强大;现在我们的策略平台甚至支持分词查询、分桶查询、多表联合查询、TopN、聚合查询等多种复合查询,这都要感谢ElasticSearch强大的功能。
3. 元数据管理模块介绍
大家都知道HBase是No-Schema模型,元数据管理层我们也就是为其和ES做一个虚拟的Schema管理,同时去动态控制哪些字段要建索引。在数据接入的时候,我们会通过元数据中心判断数据是否符合规则(我们自己定的一些规则);在数据输出的时候,我们控制哪些策略需要走缓存,哪些策略不需要走HBase等等。其次,维护一套元数据方便我们做一些简单的页面指标监控,并对ES和HBase有一个总线控制(如建表删表等),该模块就不多说了。
4. 索引建立模块介绍
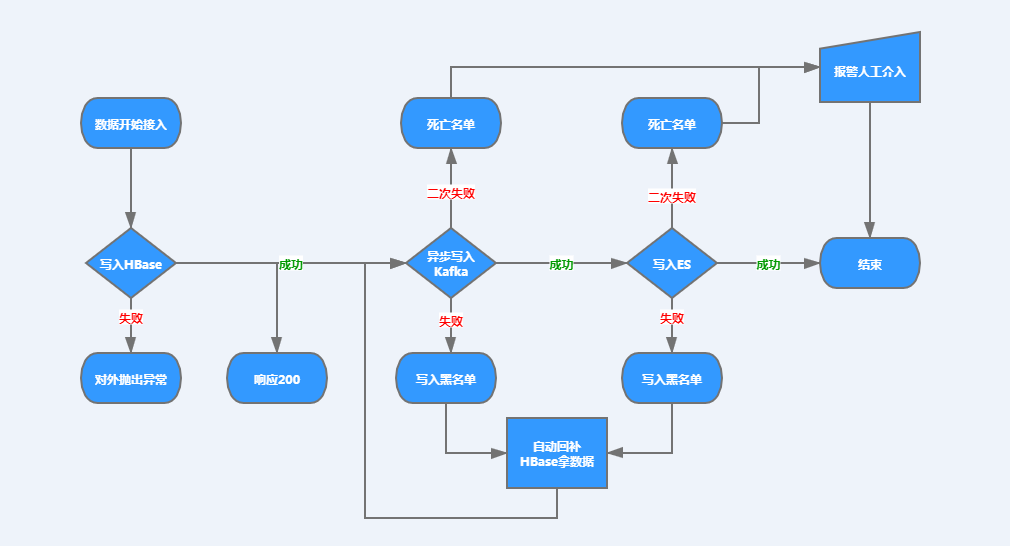
这个模块呢,其实算是相对比较复杂的一个模块。我们没有采用HBase + WAL + ES的方式而是HBase + Kafka + ES 的方式去同步索引数据。一是因为WAL层不太好控制和监控,二是ES消费WAL的效率问题,三是WAL层数据一致性不好维护。
所以我们把一部分的工作放到了数据接入层,在数据写完HBase之后,即对外响应Success并异步将数据推至Kafak队列中等待ES去二次消费;写入失败则对外抛出异常,我们首先要保证的是,写入HBase要么成功,要么失败。
在ES消费层,我们是可以动态指定消费线程数量的。当Kafka Lag堆积超过一定阈值(阈值可进行Group级调节和监控),会进行警报,并动态调整消费线程数。
在数据一致性方面,我们也做了大量工作,且我们只保证数据最终一致性。当数据写入HBase成功之后,我们会对写Kafka和写ES进行链路追踪,任何一个环节一旦写入失败,即将Failed Key写入黑名单(Redis存储)。
对于进入黑名单的数据,我们会起定时调度线程去扫描这些Key并进行自动回补索引。回补方式是:到HBase中拿最新的数据再次写入队列中去。如果此时又失败,我们会把这些Key放入终极死亡名单(Redis存储),并通过定时调度线程去扫描这个死亡名单,如果有尸体,则报警,此时人力介入。
这种分层处理方式,也是借鉴了些许HBase LSM的思想,勿喷勿喷~
我简单画了一下这个流程,方便大家理解,见下图:
5. 平台监控模块介绍
该模块不再细说了,主要是Hadoop集群、HBase集群的监控,外加K8S平台监控。K8S监控平台主要基于Prometheus+Grafana+Fluent实现。
6. 离线数据分析模块介绍
该模块依赖于HBase Replication集群间复制功能实现。数据在同步至离线HBase集群之后,主要用于对接数据仓库、Spark读写分析、大范围扫描操作等等。主要是减小面向分析型作业对线上实时平台的影响。
六大模块就简单介绍到这里。
四。心得
总的感受:使用ES赋能HBase感觉很融洽,ES很棒,ES+HBase真的可以媲美SQL了。
好像ES天生跟HBase是一家人,HBase支持动态列,ES也支持动态列,这使得两者结合在一起很融洽。而ES强大的索引功能正好是HBase所不具备的,如果只是将业务索引字段存入ES中,体量其实并不大;甚至很多情况下,业务索引字段60%以上都是Term类型,根本不需要分词。虽然我们还是支持了分词,比如多标签索引就会用到。
很多设计者可能会觉得HBase + Kafka + ES三者结合在一起有点太重了,运维成本很高,有点望而却步。但转换角度想一下,我们不就是搞技术的嘛,这下子可以三个成熟产品一起学了!现在看来,收获还是大于付出的。
至于ES和Solr选择谁去做二级索引的问题,我觉得差别不大,根据自家公司的现状做选择就好了。
最后,还是要为ElasticSearch点个赞!不错的产品!
五。未来要做的事
- 多租户全链路打通
- 策略层SQL支持
- 系统不断优化、产品化

转载请注明出处!欢迎关注本人微信公众号【HBase工作笔记】