【tensorflow2.0】处理时间序列数据
- 2020 年 4 月 9 日
- 筆記
国内的新冠肺炎疫情从发现至今已经持续3个多月了,这场起源于吃野味的灾难给大家的生活造成了诸多方面的影响。
有的同学是收入上的,有的同学是感情上的,有的同学是心理上的,还有的同学是体重上的。
那么国内的新冠肺炎疫情何时结束呢?什么时候我们才可以重获自由呢?
本篇文章将利用TensorFlow2.0建立时间序列RNN模型,对国内的新冠肺炎疫情结束时间进行预测。
一,准备数据
本文的数据集取自tushare,获取该数据集的方法参考了以下文章。
《https://zhuanlan.zhihu.com/p/109556102》
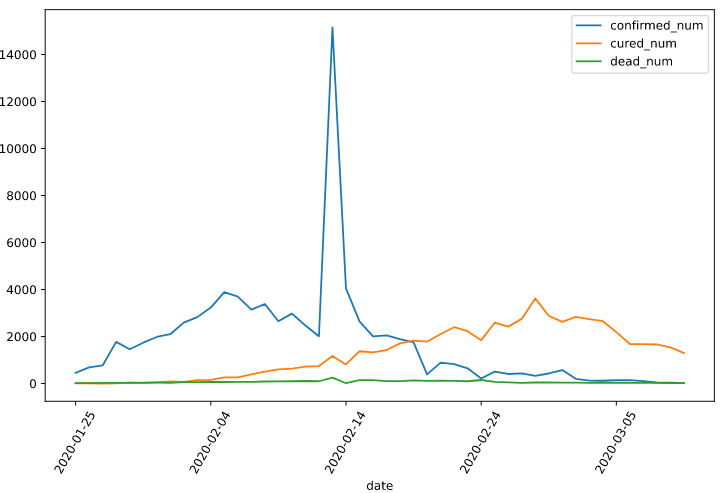
首先看下数据是什么样子的:
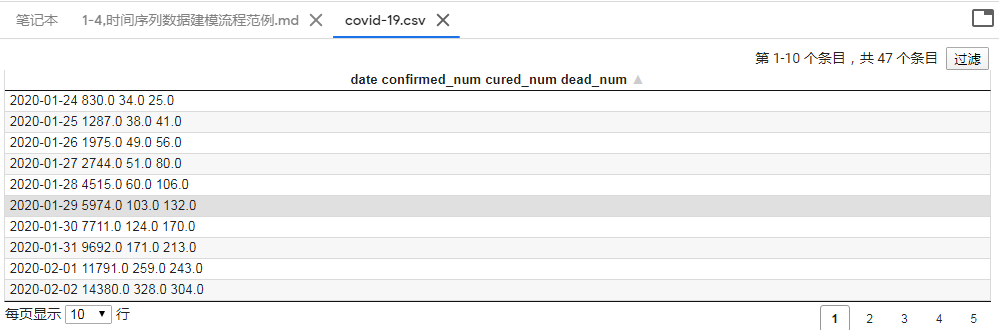
有时间、确诊人数、治愈人数、死亡人数这些列。
然后是创建数据集:
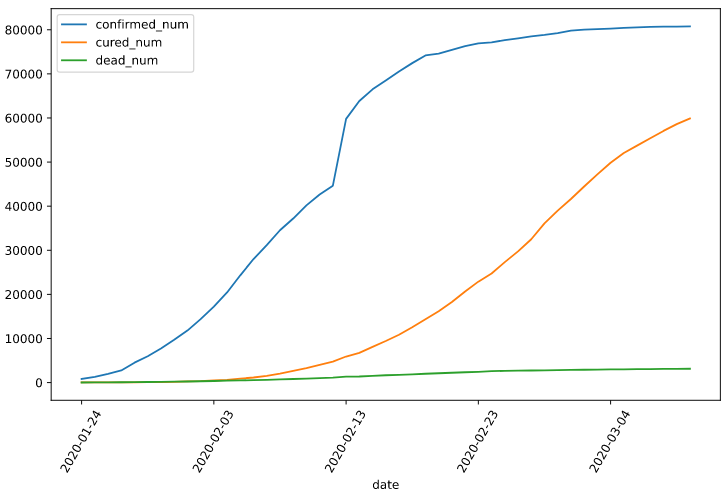
import numpy as np import pandas as pd import matplotlib.pyplot as plt import tensorflow as tf from tensorflow.keras import models,layers,losses,metrics,callbacks %matplotlib inline %config InlineBackend.figure_format = 'svg' df = pd.read_csv("./data/covid-19.csv",sep = "t") df.plot(x = "date",y = ["confirmed_num","cured_num","dead_num"],figsize=(10,6)) plt.xticks(rotation=60) dfdata = df.set_index("date") dfdiff = dfdata.diff(periods=1).dropna() dfdiff = dfdiff.reset_index("date") dfdiff.plot(x = "date",y = ["confirmed_num","cured_num","dead_num"],figsize=(10,6)) plt.xticks(rotation=60) dfdiff = dfdiff.drop("date",axis = 1).astype("float32") # 用某日前8天窗口数据作为输入预测该日数据 WINDOW_SIZE = 8 def batch_dataset(dataset): dataset_batched = dataset.batch(WINDOW_SIZE,drop_remainder=True) return dataset_batched ds_data = tf.data.Dataset.from_tensor_slices(tf.constant(dfdiff.values,dtype = tf.float32)) .window(WINDOW_SIZE,shift=1).flat_map(batch_dataset) ds_label = tf.data.Dataset.from_tensor_slices( tf.constant(dfdiff.values[WINDOW_SIZE:],dtype = tf.float32)) # 数据较小,可以将全部训练数据放入到一个batch中,提升性能 ds_train = tf.data.Dataset.zip((ds_data,ds_label)).batch(38).cache()
二,定义模型
使用Keras接口有以下3种方式构建模型:使用Sequential按层顺序构建模型,使用函数式API构建任意结构模型,继承Model基类构建自定义模型。
此处选择使用函数式API构建任意结构模型。
# 考虑到新增确诊,新增治愈,新增死亡人数数据不可能小于0,设计如下结构 class Block(layers.Layer): def __init__(self, **kwargs): super(Block, self).__init__(**kwargs) def call(self, x_input,x): x_out = tf.maximum((1+x)*x_input[:,-1,:],0.0) return x_out def get_config(self): config = super(Block, self).get_config() return config tf.keras.backend.clear_session() x_input = layers.Input(shape = (None,3),dtype = tf.float32) x = layers.LSTM(3,return_sequences = True,input_shape=(None,3))(x_input) x = layers.LSTM(3,return_sequences = True,input_shape=(None,3))(x) x = layers.LSTM(3,return_sequences = True,input_shape=(None,3))(x) x = layers.LSTM(3,input_shape=(None,3))(x) x = layers.Dense(3)(x) # 考虑到新增确诊,新增治愈,新增死亡人数数据不可能小于0,设计如下结构 # x = tf.maximum((1+x)*x_input[:,-1,:],0.0) x = Block()(x_input,x) model = models.Model(inputs = [x_input],outputs = [x]) model.summary()

三,训练模型
训练模型通常有3种方法,内置fit方法,内置train_on_batch方法,以及自定义训练循环。此处我们选择最常用也最简单的内置fit方法。
注:循环神经网络调试较为困难,需要设置多个不同的学习率多次尝试,以取得较好的效果。
# 自定义损失函数,考虑平方差和预测目标的比值 class MSPE(losses.Loss): def call(self,y_true,y_pred): err_percent = (y_true - y_pred)**2/(tf.maximum(y_true**2,1e-7)) mean_err_percent = tf.reduce_mean(err_percent) return mean_err_percent def get_config(self): config = super(MSPE, self).get_config() return config import datetime optimizer = tf.keras.optimizers.Adam(learning_rate=0.01) model.compile(optimizer=optimizer,loss=MSPE(name = "MSPE")) logdir = "./data/keras_model/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") tb_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1) # 如果loss在100个epoch后没有提升,学习率减半。 lr_callback = tf.keras.callbacks.ReduceLROnPlateau(monitor="loss",factor = 0.5, patience = 100) # 当loss在200个epoch后没有提升,则提前终止训练。 stop_callback = tf.keras.callbacks.EarlyStopping(monitor = "loss", patience= 200) callbacks_list = [tb_callback,lr_callback,stop_callback] history = model.fit(ds_train,epochs=500,callbacks = callbacks_list)
部分结果:
...... Epoch 491/500 1/1 [==============================] - 0s 11ms/step - loss: 0.2643 - lr: 0.0050 Epoch 492/500 1/1 [==============================] - 0s 12ms/step - loss: 0.2625 - lr: 0.0050 Epoch 493/500 1/1 [==============================] - 0s 12ms/step - loss: 0.2628 - lr: 0.0050 Epoch 494/500 1/1 [==============================] - 0s 11ms/step - loss: 0.2633 - lr: 0.0050 Epoch 495/500 1/1 [==============================] - 0s 12ms/step - loss: 0.2619 - lr: 0.0050 Epoch 496/500 1/1 [==============================] - 0s 11ms/step - loss: 0.2627 - lr: 0.0050 Epoch 497/500 1/1 [==============================] - 0s 11ms/step - loss: 0.2622 - lr: 0.0050 Epoch 498/500 1/1 [==============================] - 0s 12ms/step - loss: 0.2618 - lr: 0.0050 Epoch 499/500 1/1 [==============================] - 0s 12ms/step - loss: 0.2624 - lr: 0.0050 Epoch 500/500 1/1 [==============================] - 0s 12ms/step - loss: 0.2616 - lr: 0.0050
四,评估模型
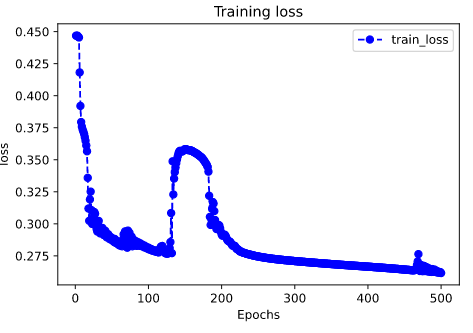
评估模型一般要设置验证集或者测试集,由于此例数据较少,我们仅仅可视化损失函数在训练集上的迭代情况。
%matplotlib inline %config InlineBackend.figure_format = 'svg' import matplotlib.pyplot as plt def plot_metric(history, metric): train_metrics = history.history[metric] epochs = range(1, len(train_metrics) + 1) plt.plot(epochs, train_metrics, 'bo--') plt.title('Training '+ metric) plt.xlabel("Epochs") plt.ylabel(metric) plt.legend(["train_"+metric]) plt.show() plot_metric(history,"loss")
五,使用模型
此处我们使用模型预测疫情结束时间,即 新增确诊病例为0 的时间。
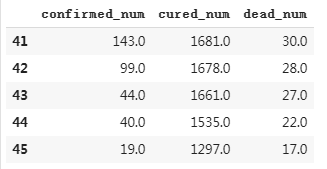
# 使用dfresult记录现有数据以及此后预测的疫情数据 dfresult = dfdiff[["confirmed_num","cured_num","dead_num"]].copy() dfresult.tail()
# 预测此后100天的新增走势,将其结果添加到dfresult中 for i in range(100): arr_predict = model.predict(tf.constant(tf.expand_dims(dfresult.values[-38:,:],axis = 0))) dfpredict = pd.DataFrame(tf.cast(tf.floor(arr_predict),tf.float32).numpy(), columns = dfresult.columns) dfresult = dfresult.append(dfpredict,ignore_index=True) dfresult.query("confirmed_num==0").head()
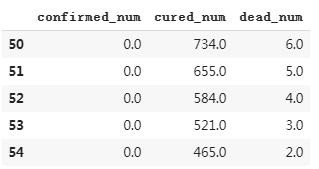
# 第55天开始新增确诊降为0,第45天对应3月10日,也就是10天后,即预计3月20日新增确诊降为0 # 注:该预测偏乐观 dfresult.query("cured_num==0").head()
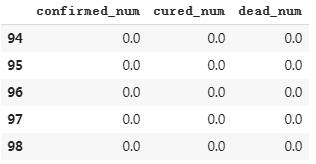
# 第164天开始新增治愈降为0,第45天对应3月10日,也就是大概4个月后,即7月10日左右全部治愈。 # 注: 该预测偏悲观,并且存在问题,如果将每天新增治愈人数加起来,将超过累计确诊人数。 dfresult.query("dead_num==0").head() # 第60天开始,新增死亡降为0,第45天对应3月10日,也就是大概15天后,即20200325 # 该预测较为合理
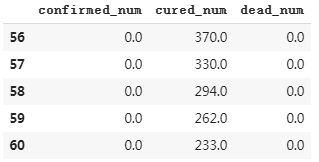
六,保存模型
推荐使用TensorFlow原生方式保存模型。
model.save('./data/tf_model_savedmodel', save_format="tf") print('export saved model.') model_loaded = tf.keras.models.load_model('./data/tf_model_savedmodel',compile=False) optimizer = tf.keras.optimizers.Adam(learning_rate=0.001) model_loaded.compile(optimizer=optimizer,loss=MSPE(name = "MSPE")) model_loaded.predict(ds_train)
参考:
开源电子书地址:https://lyhue1991.github.io/eat_tensorflow2_in_30_days/
GitHub 项目地址:https://github.com/lyhue1991/eat_tensorflow2_in_30_days